 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised High Dynamic Range Image Reconstructing via Bi-Level Uncertain Area Masking
Nov 17, 2025Reconstructing high dynamic range (HDR) images from low dynamic range (LDR) bursts plays an essential role in the computational photography. Impressive progress has been achieved by learning-based algorithms which require LDR-HDR image pairs. However, these pairs are hard to obtain, which motivates researchers to delve into the problem of annotation-efficient HDR image reconstructing: how to achieve comparable performance with limited HDR ground truths (GTs). This work attempts to address this problem from the view of semi-supervised learning where a teacher model generates pseudo HDR GTs for the LDR samples without GTs and a student model learns from pseudo GTs. Nevertheless, the confirmation bias, i.e., the student may learn from the artifacts in pseudo HDR GTs, presents an impediment. To remove this impediment, an uncertainty-based masking process is proposed to discard unreliable parts of pseudo GTs at both pixel and patch levels, then the trusted areas can be learned from by the student. With this novel masking process, our semi-supervised HDR reconstructing method not only outperforms previous annotation-efficient algorithms, but also achieves comparable performance with up-to-date fully-supervised methods by using only 6.7% HDR GTs.
ProBench: Benchmarking GUI Agents with Accurate Process Information
Nov 12, 2025With the deep integration of artificial intelligence and interactive technology, Graphical User Interface (GUI) Agent, as the carrier connecting goal-oriented natural language and real-world devices, has received widespread attention from the community. Contemporary benchmarks aim to evaluate the comprehensive capabilities of GUI agents in GUI operation tasks, generally determining task completion solely by inspecting the final screen state. However, GUI operation tasks consist of multiple chained steps while not all critical information is presented in the final few pages. Although a few research has begun to incorporate intermediate steps into evaluation, accurately and automatically capturing this process information still remains an open challenge. To address this weakness, we introduce ProBench, a comprehensive mobile benchmark with over 200 challenging GUI tasks covering widely-used scenarios. Remaining the traditional State-related Task evaluation, we extend our dataset to include Process-related Task and design a specialized evaluation method. A newly introduced Process Provider automatically supplies accurate process information, enabling presice assessment of agent's performance. Our evaluation of advanced GUI agents reveals significant limitations for real-world GUI scenarios. These shortcomings are prevalent across diverse models, including both large-scale generalist models and smaller, GUI-specific models. A detailed error analysis further exposes several universal problems, outlining concrete directions for future improvements.
History-Aware Reasoning for GUI Agents
Nov 12, 2025Advances in Multimodal Large Language Models have significantly enhanced Graphical User Interface (GUI) automation. Equipping GUI agents with reliable episodic reasoning capabilities is essential for bridging the gap between users' concise task descriptions and the complexities of real-world execution. Current methods integrate Reinforcement Learning (RL) with System-2 Chain-of-Thought, yielding notable gains in reasoning enhancement. For long-horizon GUI tasks, historical interactions connect each screen to the goal-oriented episode chain, and effectively leveraging these clues is crucial for the current decision. However, existing native GUI agents exhibit weak short-term memory in their explicit reasoning, interpreting the chained interactions as discrete screen understanding, i.e., unawareness of the historical interactions within the episode. This history-agnostic reasoning challenges their performance in GUI automation. To alleviate this weakness, we propose a History-Aware Reasoning (HAR) framework, which encourages an agent to reflect on its own errors and acquire episodic reasoning knowledge from them via tailored strategies that enhance short-term memory in long-horizon interaction. The framework mainly comprises constructing a reflective learning scenario, synthesizing tailored correction guidelines, and designing a hybrid RL reward function. Using the HAR framework, we develop a native end-to-end model, HAR-GUI-3B, which alters the inherent reasoning mode from history-agnostic to history-aware, equipping the GUI agent with stable short-term memory and reliable perception of screen details. Comprehensive evaluations across a range of GUI-related benchmarks demonstrate the effectiveness and generalization of our method.
On Accurate and Robust Estimation of 3D and 2D Circular Center: Method and Application to Camera-Lidar Calibration
Nov 10, 2025



Circular targets are widely used in LiDAR-camera extrinsic calibration due to their geometric consistency and ease of detection. However, achieving accurate 3D-2D circular center correspondence remains challenging. Existing methods often fail due to decoupled 3D fitting and erroneous 2D ellipse-center estimation. To address this, we propose a geometrically principled framework featuring two innovations: (i) a robust 3D circle center estimator based on conformal geometric algebra and RANSAC; and (ii) a chord-length variance minimization method to recover the true 2D projected center, resolving its dual-minima ambiguity via homography validation or a quasi-RANSAC fallback. Evaluated on synthetic and real-world datasets, our framework significantly outperforms state-of-the-art approaches. It reduces extrinsic estimation error and enables robust calibration across diverse sensors and target types, including natural circular objects. Our code will be publicly released for reproducibility.
What is the Most Efficient Technique for Uplink Cell-Free Massive MIMO?
Aug 28, 2025This paper seeks to determine the most efficient uplink technique for cell-free massive MIMO systems. Despite offering great advances, existing works suffer from fragmented methodologies and inconsistent assumptions (e.g., single- vs. multi-antenna access points, ideal vs. spatially correlated channels). To address these limitations, we: (1) establish a unified analytical framework compatible with centralized/distributed processing and diverse combining schemes; (2) develop a universal optimization strategy for max-min power control; and (3) conduct a holistic study among four critical metrics: worst-case user spectral efficiency (fairness), system capacity, fronthaul signaling, and computational complexity. Through analyses and evaluation, this work ultimately identifies the optimal uplink technique for practical cell-free deployments.
Achieving Optimal Performance-Cost Trade-Off in Hierarchical Cell-Free Massive MIMO
Aug 28, 2025Cell-free (CF) massive MIMO offers uniform service via distributed access points (APs), which impose high deployment costs. A novel design called hierarchical cell-free (HCF) addresses this problem by replacing some APs with a central base station, thereby lowering the costs of fronthaul network (wireless sites and fiber cables) while preserving performance. To identify the optimal uplink configuration in HCF massive MIMO, this paper provides the first comprehensive analysis, benchmarking it against cellular and CF systems. We develop a unified analytical framework for spectral efficiency that supports arbitrary combining schemes and introduce a novel hierarchical combining approach tailored to HCF two-tier architecture. Through analysis and evaluation of user fairness, system capacity, fronthaul requirements, and computational complexity, this paper identifies that HCF using centralized zero-forcing combining achieves the optimal balance between performance and cost-efficiency.
InquireMobile: Teaching VLM-based Mobile Agent to Request Human Assistance via Reinforcement Fine-Tuning
Aug 27, 2025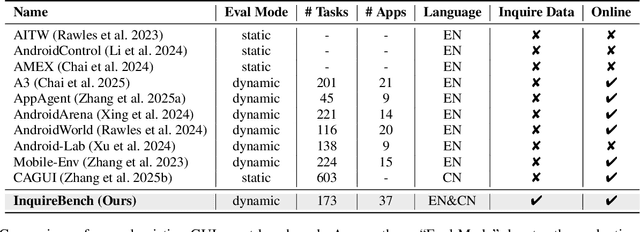
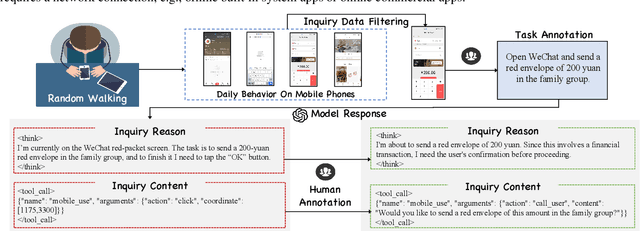

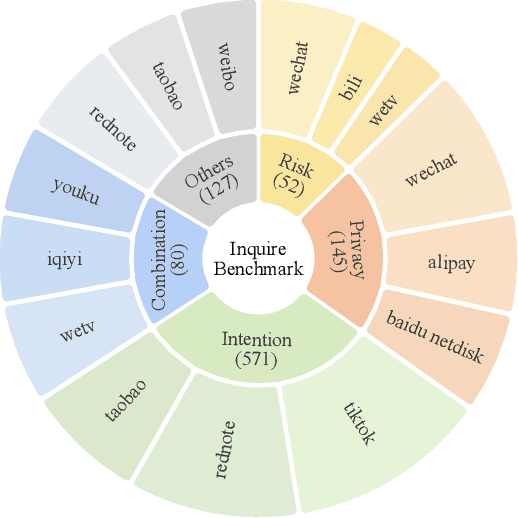
Recent advances in Vision-Language Models (VLMs) have enabled mobile agents to perceive and interact with real-world mobile environments based on human instructions. However, the current fully autonomous paradigm poses potential safety risks when model understanding or reasoning capabilities are insufficient. To address this challenge, we first introduce \textbf{InquireBench}, a comprehensive benchmark specifically designed to evaluate mobile agents' capabilities in safe interaction and proactive inquiry with users, encompassing 5 categories and 22 sub-categories, where most existing VLM-based agents demonstrate near-zero performance. In this paper, we aim to develop an interactive system that actively seeks human confirmation at critical decision points. To achieve this, we propose \textbf{InquireMobile}, a novel model inspired by reinforcement learning, featuring a two-stage training strategy and an interactive pre-action reasoning mechanism. Finally, our model achieves an 46.8% improvement in inquiry success rate and the best overall success rate among existing baselines on InquireBench. We will open-source all datasets, models, and evaluation codes to facilitate development in both academia and industry.
Convergence Analysis of the Lion Optimizer in Centralized and Distributed Settings
Aug 17, 2025In this paper, we analyze the convergence properties of the Lion optimizer. First, we establish that the Lion optimizer attains a convergence rate of $\mathcal{O}(d^{1/2}T^{-1/4})$ under standard assumptions, where $d$ denotes the problem dimension and $T$ is the iteration number. To further improve this rate, we introduce the Lion optimizer with variance reduction, resulting in an enhanced convergence rate of $\mathcal{O}(d^{1/2}T^{-1/3})$. We then analyze in distributed settings, where the standard and variance reduced version of the distributed Lion can obtain the convergence rates of $\mathcal{O}(d^{1/2}(nT)^{-1/4})$ and $\mathcal{O}(d^{1/2}(nT)^{-1/3})$, with $n$ denoting the number of nodes. Furthermore, we investigate a communication-efficient variant of the distributed Lion that ensures sign compression in both communication directions. By employing the unbiased sign operations, the proposed Lion variant and its variance reduction counterpart, achieve convergence rates of $\mathcal{O}\left( \max \left\{\frac{d^{1/4}}{T^{1/4}}, \frac{d^{1/10}}{n^{1/5}T^{1/5}} \right\} \right)$ and $\mathcal{O}\left( \frac{d^{1/4}}{T^{1/4}} \right)$, respectively.
ASM-UNet: Adaptive Scan Mamba Integrating Group Commonalities and Individual Variations for Fine-Grained Segmentation
Aug 10, 2025Precise lesion resection depends on accurately identifying fine-grained anatomical structures. While many coarse-grained segmentation (CGS) methods have been successful in large-scale segmentation (e.g., organs), they fall short in clinical scenarios requiring fine-grained segmentation (FGS), which remains challenging due to frequent individual variations in small-scale anatomical structures. Although recent Mamba-based models have advanced medical image segmentation, they often rely on fixed manually-defined scanning orders, which limit their adaptability to individual variations in FGS. To address this, we propose ASM-UNet, a novel Mamba-based architecture for FGS. It introduces adaptive scan scores to dynamically guide the scanning order, generated by combining group-level commonalities and individual-level variations. Experiments on two public datasets (ACDC and Synapse) and a newly proposed challenging biliary tract FGS dataset, namely BTMS, demonstrate that ASM-UNet achieves superior performance in both CGS and FGS tasks. Our code and dataset are available at https://github.com/YqunYang/ASM-UNet.
Improved Analysis for Sign-based Methods with Momentum Updates
Jul 16, 2025



In this paper, we present enhanced analysis for sign-based optimization algorithms with momentum updates. Traditional sign-based methods, under the separable smoothness assumption, guarantee a convergence rate of $\mathcal{O}(T^{-1/4})$, but they either require large batch sizes or assume unimodal symmetric stochastic noise. To address these limitations, we demonstrate that signSGD with momentum can achieve the same convergence rate using constant batch sizes without additional assumptions. Our analysis, under the standard $l_2$-smoothness condition, improves upon the result of the prior momentum-based signSGD method by a factor of $\mathcal{O}(d^{1/2})$, where $d$ is the problem dimension. Furthermore, we explore sign-based methods with majority vote in distributed settings and show that the proposed momentum-based method yields convergence rates of $\mathcal{O}\left( d^{1/2}T^{-1/2} + dn^{-1/2} \right)$ and $\mathcal{O}\left( \max \{ d^{1/4}T^{-1/4}, d^{1/10}T^{-1/5} \} \right)$, which outperform the previous results of $\mathcal{O}\left( dT^{-1/4} + dn^{-1/2} \right)$ and $\mathcal{O}\left( d^{3/8}T^{-1/8} \right)$, respectively. Numerical experiments further validate the effectiveness of the proposed methods.