 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-to-Text Adapter and Speech-to-Entity Retriever Augmented LLMs for Speech Understanding
Jun 08, 2023



Large Language Models (LLMs) have been applied in the speech domain, often incurring a performance drop due to misaligned between speech and language representations. To bridge this gap, we propose a joint speech and language model (SLM) using a Speech2Text adapter, which maps speech into text token embedding space without speech information loss. Additionally, using a CTC-based blank-filtering, we can reduce the speech sequence length to that of text. In speech MultiWoz dataset (DSTC11 challenge), SLM largely improves the dialog state tracking (DST) performance (24.7% to 28.4% accuracy). Further to address errors on rare entities, we augment SLM with a Speech2Entity retriever, which uses speech to retrieve relevant entities, and then adds them to the original SLM input as a prefix. With this retrieval-augmented SLM (ReSLM), the DST performance jumps to 34.6% accuracy. Moreover, augmenting the ASR task with the dialog understanding task improves the ASR performance from 9.4% to 8.5% WER.
Label Aware Speech Representation Learning For Language Identification
Jun 07, 2023



Speech representation learning approaches for non-semantic tasks such as language recognition have either explored supervised embedding extraction methods using a classifier model or self-supervised representation learning approaches using raw data. In this paper, we propose a novel framework of combining self-supervised representation learning with the language label information for the pre-training task. This framework, termed as Label Aware Speech Representation (LASR) learning, uses a triplet based objective function to incorporate language labels along with the self-supervised loss function. The speech representations are further fine-tuned for the downstream task. The language recognition experiments are performed on two public datasets - FLEURS and Dhwani. In these experiments, we illustrate that the proposed LASR framework improves over the state-of-the-art systems on language identification. We also report an analysis of the robustness of LASR approach to noisy/missing labels as well as its application to multi-lingual speech recognition tasks.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023



This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
Domain-Expanded ASTE: Rethinking Generalization in Aspect Sentiment Triplet Extraction
May 23, 2023



Aspect Sentiment Triplet Extraction (ASTE) is a subtask of Aspect-Based Sentiment Analysis (ABSA) that considers each opinion term, their expressed sentiment, and the corresponding aspect targets. However, existing methods are limited to the in-domain setting with two domains. Hence, we propose a domain-expanded benchmark to address the in-domain, out-of-domain and cross-domain settings. We support the new benchmark by annotating more than 4000 data samples for two new domains based on hotel and cosmetics reviews. Our analysis of five existing methods shows that while there is a significant gap between in-domain and out-of-domain performance, generative methods have a strong potential for domain generalization. Our datasets, code implementation and models are available at https://github.com/DAMO-NLP-SG/domain-expanded-aste .
Modular CSI Quantization for FDD Massive MIMO Communication
Mar 23, 2023



We consider high-dimensional MIMO transmissions in frequency division duplexing (FDD) systems. For precoding, the frequency selective channel has to be measured, quantized and fed back to the base station by the users. When the number of antennas is very high this typically leads to prohibitively high quantization complexity and large feedback. In 5G New Radio (NR), a modular quantization approach has been applied for this, where first a low-dimensional subspace is identified for the whole frequency selective channel, and then subband channels are linearly mapped to this subspace and quantized. We analyze how the components in such a modular scheme contribute to the overall quantization distortion. Based on this analysis we improve the technology components in the modular approach and propose an orthonormalized wideband precoding scheme and a sequential wideband precoding approach which provide considerable gains over the conventional method. We compare the performance of the developed quantization schemes to prior art by simulations in terms of the projection distortion, overall distortion and spectral efficiency, in a scenario with a realistic spatial channel model.
Miipher: A Robust Speech Restoration Model Integrating Self-Supervised Speech and Text Representations
Mar 03, 2023



Speech restoration (SR) is a task of converting degraded speech signals into high-quality ones. In this study, we propose a robust SR model called Miipher, and apply Miipher to a new SR application: increasing the amount of high-quality training data for speech generation by converting speech samples collected from the Web to studio-quality. To make our SR model robust against various degradation, we use (i) a speech representation extracted from w2v-BERT for the input feature, and (ii) a text representation extracted from transcripts via PnG-BERT as a linguistic conditioning feature. Experiments show that Miipher (i) is robust against various audio degradation and (ii) enable us to train a high-quality text-to-speech (TTS) model from restored speech samples collected from the Web. Audio samples are available at our demo page: google.github.io/df-conformer/miipher/
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
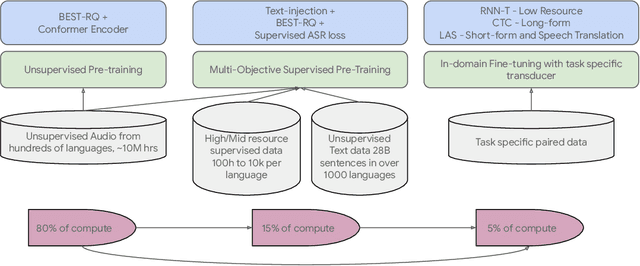
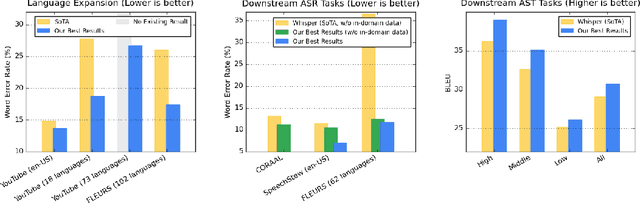

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023



We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
Efficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Electromagnetic-Compliant Channel Modeling and Performance Evaluation for Holographic MIMO
Jan 13, 2023



Recently, the concept of holographic multiple-input multiple-output (MIMO) is emerging as one of the promising technologies beyond massive MIMO. Many challenges need to be addressed to bring this novel idea into practice, including electromagnetic (EM)-compliant channel modeling and accurate performance evaluation. In this paper, an EM-compliant channel model is proposed for the holographic MIMO systems, which is able to model both the characteristics of the propagation channel and the non-ideal factors caused by mutual coupling at the transceivers, including the antenna pattern distortion and the decrease of antenna efficiency. Based on the proposed channel model, a more realistic performance evaluation is conducted to show the performance of the holographic MIMO system in both the single-user and the multi-user scenarios. Key challenges and future research directions are further provided based on the theoretical analyses and numerical results.