 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Particle Filter for Target Tracking in MIMO OFDM Integrated Sensing and Communications
Dec 09, 2025Particle filtering for target tracking using multi-input multi-output (MIMO) pulse-Doppler radars faces three long-standing obstacles: a) the absence of reliable likelihood models for raw radar data; b) the computational and statistical complications that arise when nuisance parameters (e.g., complex path gains) are augmented into state vectors; and c) the prohibitive computational burden of extracting noisy measurements of range, Doppler, and angles from snapshots. Motivated by an optimization-centric interpretation of Bayes' rule, this article addresses these challenges by proposing a new particle filtering framework that evaluates each hypothesized state using a tailored cost function, rather than relying on an explicit likelihood relation. The framework yields substantial reductions in both running time and tracking error compared to existing schemes. In addition, we examine the implementation of the proposed particle filter in MIMO orthogonal frequency-division multiplexing (OFDM) systems, aiming to equip modern communication infrastructure with integrated sensing and communications (ISAC) capabilities. Experiments suggest that MIMO-OFDM with pulse-Doppler processing holds considerable promise for ISAC, particularly when wide bandwidth, extended on-target time, and large antenna aperture are utilized.
SAMRI: Segment Anything Model for MRI
Oct 30, 2025Accurate magnetic resonance imaging (MRI) segmentation is crucial for clinical decision-making, but remains labor-intensive when performed manually. Convolutional neural network (CNN)-based methods can be accurate and efficient, but often generalize poorly to MRI's variable contrast, intensity inhomogeneity, and protocols. Although the transformer-based Segment Anything Model (SAM) has demonstrated remarkable generalizability in natural images, existing adaptations often treat MRI as another imaging modality, overlooking these modality-specific challenges. We present SAMRI, an MRI-specialized SAM trained and validated on 1.1 million labeled MR slices spanning whole-body organs and pathologies. We demonstrate that SAM can be effectively adapted to MRI by simply fine-tuning its mask decoder using a two-stage strategy, reducing training time by 94% and trainable parameters by 96% versus full-model retraining. Across diverse MRI segmentation tasks, SAMRI achieves a mean Dice of 0.87, delivering state-of-the-art accuracy across anatomical regions and robust generalization on unseen structures, particularly small and clinically important structures.
Human Behavior Atlas: Benchmarking Unified Psychological and Social Behavior Understanding
Oct 06, 2025Using intelligent systems to perceive psychological and social behaviors, that is, the underlying affective, cognitive, and pathological states that are manifested through observable behaviors and social interactions, remains a challenge due to their complex, multifaceted, and personalized nature. Existing work tackling these dimensions through specialized datasets and single-task systems often miss opportunities for scalability, cross-task transfer, and broader generalization. To address this gap, we curate Human Behavior Atlas, a unified benchmark of diverse behavioral tasks designed to support the development of unified models for understanding psychological and social behaviors. Human Behavior Atlas comprises over 100,000 samples spanning text, audio, and visual modalities, covering tasks on affective states, cognitive states, pathologies, and social processes. Our unification efforts can reduce redundancy and cost, enable training to scale efficiently across tasks, and enhance generalization of behavioral features across domains. On Human Behavior Atlas, we train three models: OmniSapiens-7B SFT, OmniSapiens-7B BAM, and OmniSapiens-7B RL. We show that training on Human Behavior Atlas enables models to consistently outperform existing multimodal LLMs across diverse behavioral tasks. Pretraining on Human Behavior Atlas also improves transfer to novel behavioral datasets; with the targeted use of behavioral descriptors yielding meaningful performance gains.
GUI-ARP: Enhancing Grounding with Adaptive Region Perception for GUI Agents
Sep 19, 2025Existing GUI grounding methods often struggle with fine-grained localization in high-resolution screenshots. To address this, we propose GUI-ARP, a novel framework that enables adaptive multi-stage inference. Equipped with the proposed Adaptive Region Perception (ARP) and Adaptive Stage Controlling (ASC), GUI-ARP dynamically exploits visual attention for cropping task-relevant regions and adapts its inference strategy, performing a single-stage inference for simple cases and a multi-stage analysis for more complex scenarios. This is achieved through a two-phase training pipeline that integrates supervised fine-tuning with reinforcement fine-tuning based on Group Relative Policy Optimization (GRPO). Extensive experiments demonstrate that the proposed GUI-ARP achieves state-of-the-art performance on challenging GUI grounding benchmarks, with a 7B model reaching 60.8% accuracy on ScreenSpot-Pro and 30.9% on UI-Vision benchmark. Notably, GUI-ARP-7B demonstrates strong competitiveness against open-source 72B models (UI-TARS-72B at 38.1%) and proprietary models.
Scalable Hessian-free Proximal Conjugate Gradient Method for Nonconvex and Nonsmooth Optimization
Sep 19, 2025


This work studies a composite minimization problem involving a differentiable function q and a nonsmooth function h, both of which may be nonconvex. This problem is ubiquitous in signal processing and machine learning yet remains challenging to solve efficiently, particularly when large-scale instances, poor conditioning, and nonconvexity coincide. To address these challenges, we propose a proximal conjugate gradient method (PCG) that matches the fast convergence of proximal (quasi-)Newton algorithms while reducing computation and memory complexity, and is especially effective for spectrally clustered Hessians. Our key innovation is to form, at each iteration, an approximation to the Newton direction based on CG iterations to build a majorization surrogate. We define this surrogate in a curvature-aware manner and equip it with a CG-derived isotropic weight, guaranteeing majorization of a local second-order model of q along the given direction. To better preserve majorization after the proximal step and enable further approximation refinement, we scale the CG direction by the ratio between the Cauchy step length and a step size derived from the largest Ritz value of the CG tridiagonal. All curvature is accessed via Hessian-vector products computed by automatic differentiation, keeping the method Hessian-free. Convergence to first-order critical points is established. Numerical experiments on CS-MRI with nonconvex regularization and on dictionary learning, against benchmark methods, demonstrate the efficiency of the proposed approach.
Dual-Arm Hierarchical Planning for Laboratory Automation: Vibratory Sieve Shaker Operations
Sep 18, 2025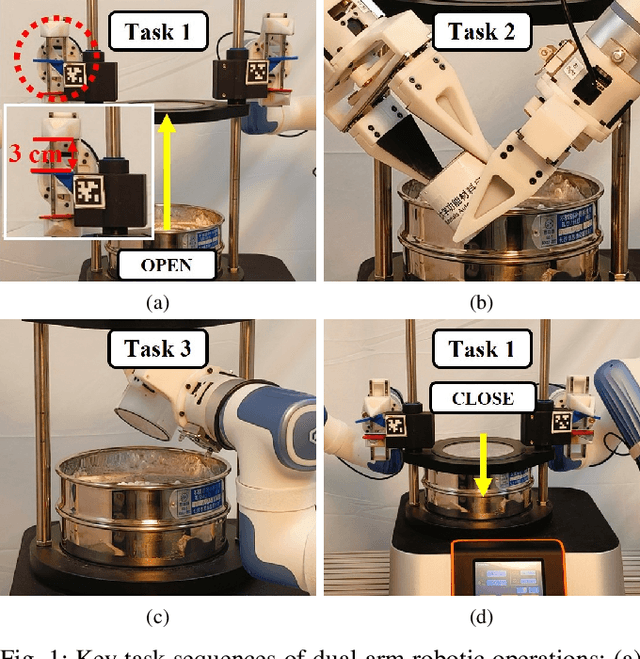
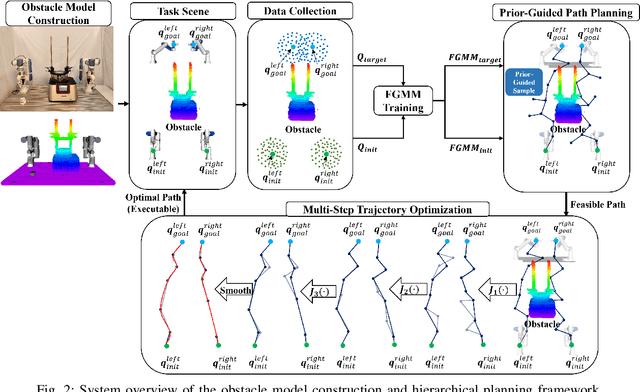
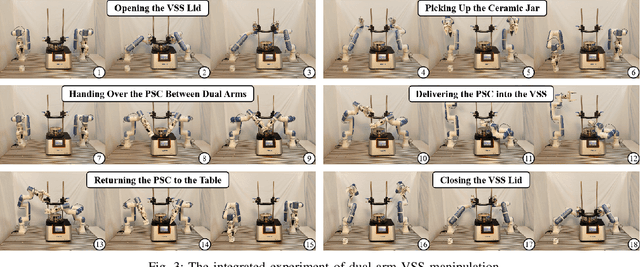
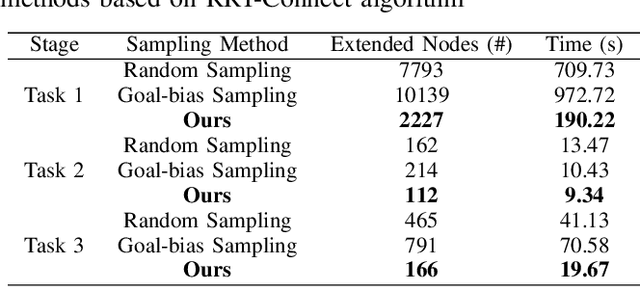
This paper addresses the challenges of automating vibratory sieve shaker operations in a materials laboratory, focusing on three critical tasks: 1) dual-arm lid manipulation in 3 cm clearance spaces, 2) bimanual handover in overlapping workspaces, and 3) obstructed powder sample container delivery with orientation constraints. These tasks present significant challenges, including inefficient sampling in narrow passages, the need for smooth trajectories to prevent spillage, and suboptimal paths generated by conventional methods. To overcome these challenges, we propose a hierarchical planning framework combining Prior-Guided Path Planning and Multi-Step Trajectory Optimization. The former uses a finite Gaussian mixture model to improve sampling efficiency in narrow passages, while the latter refines paths by shortening, simplifying, imposing joint constraints, and B-spline smoothing. Experimental results demonstrate the framework's effectiveness: planning time is reduced by up to 80.4%, and waypoints are decreased by 89.4%. Furthermore, the system completes the full vibratory sieve shaker operation workflow in a physical experiment, validating its practical applicability for complex laboratory automation.
ViDove: A Translation Agent System with Multimodal Context and Memory-Augmented Reasoning
Jul 09, 2025LLM-based translation agents have achieved highly human-like translation results and are capable of handling longer and more complex contexts with greater efficiency. However, they are typically limited to text-only inputs. In this paper, we introduce ViDove, a translation agent system designed for multimodal input. Inspired by the workflow of human translators, ViDove leverages visual and contextual background information to enhance the translation process. Additionally, we integrate a multimodal memory system and long-short term memory modules enriched with domain-specific knowledge, enabling the agent to perform more accurately and adaptively in real-world scenarios. As a result, ViDove achieves significantly higher translation quality in both subtitle generation and general translation tasks, with a 28% improvement in BLEU scores and a 15% improvement in SubER compared to previous state-of-the-art baselines. Moreover, we introduce DoveBench, a new benchmark for long-form automatic video subtitling and translation, featuring 17 hours of high-quality, human-annotated data. Our code is available here: https://github.com/pigeonai-org/ViDove
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.
Compositional Attribute Imbalance in Vision Datasets
Jun 17, 2025Visual attribute imbalance is a common yet underexplored issue in image classification, significantly impacting model performance and generalization. In this work, we first define the first-level and second-level attributes of images and then introduce a CLIP-based framework to construct a visual attribute dictionary, enabling automatic evaluation of image attributes. By systematically analyzing both single-attribute imbalance and compositional attribute imbalance, we reveal how the rarity of attributes affects model performance. To tackle these challenges, we propose adjusting the sampling probability of samples based on the rarity of their compositional attributes. This strategy is further integrated with various data augmentation techniques (such as CutMix, Fmix, and SaliencyMix) to enhance the model's ability to represent rare attributes. Extensive experiments on benchmark datasets demonstrate that our method effectively mitigates attribute imbalance, thereby improving the robustness and fairness of deep neural networks. Our research highlights the importance of modeling visual attribute distributions and provides a scalable solution for long-tail image classification tasks.
PuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
Jun 06, 2025Puzzlehunts are a genre of complex, multi-step puzzles lacking well-defined problem definitions. In contrast to conventional reasoning benchmarks consisting of tasks with clear instructions, puzzlehunts require models to discover the underlying problem structure from multimodal evidence and iterative reasoning, mirroring real-world domains such as scientific discovery, exploratory data analysis, or investigative problem-solving. Despite recent progress in foundation models, their performance on such open-ended settings remains largely untested. In this paper, we introduce PuzzleWorld, a large-scale benchmark of 667 puzzlehunt-style problems designed to assess step-by-step, open-ended, and creative multimodal reasoning. Each puzzle is annotated with the final solution, detailed reasoning traces, and cognitive skill labels, enabling holistic benchmarking and fine-grained diagnostic analysis. Most state-of-the-art models achieve only 1-2% final answer accuracy, with the best model solving only 14% of puzzles and reaching 40% stepwise accuracy. To demonstrate the value of our reasoning annotations, we show that fine-tuning a small model on reasoning traces improves stepwise reasoning from 4% to 11%, while training on final answers alone degrades performance to near zero. Our error analysis reveals that current models exhibit myopic reasoning, are bottlenecked by the limitations of language-based inference, and lack sketching capabilities crucial for visual and spatial reasoning. We release PuzzleWorld at https://github.com/MIT-MI/PuzzleWorld to support future work on building more general, open-ended, and creative reasoning systems.