 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Hallucination Revisited: An Exploratory Study on Dataset Bias
Dec 21, 2018
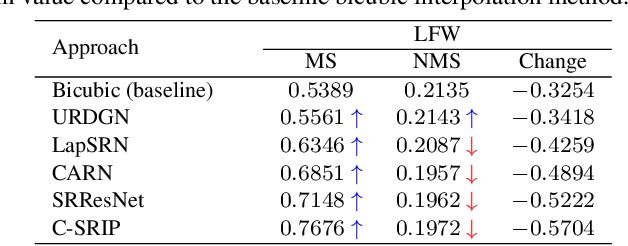
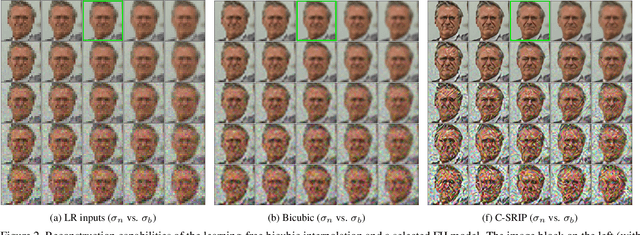
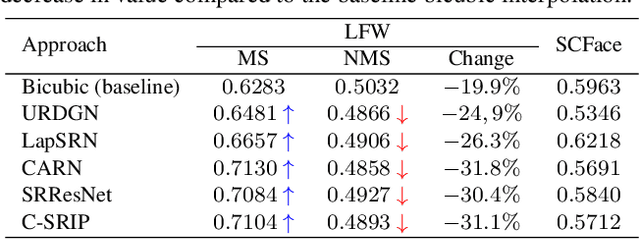
Contemporary face hallucination (FH) models exhibit considerable ability to reconstruct high-resolution (HR) details from low-resolution (LR) face images. This ability is commonly learned from examples of corresponding HR-LR image pairs, created by artificially down-sampling the HR ground truth data. This down-sampling (or degradation) procedure not only defines the characteristics of the LR training data, but also determines the type of image degradations the learned FH models are eventually able to handle. If the image characteristics encountered with real-world LR images differ from the ones seen during training, FH models are still expected to perform well, but in practice may not produce the desired results. In this paper we study this problem and explore the bias introduced into FH models by the characteristics of the training data. We systematically analyze the generalization capabilities of several FH models in various scenarios, where the image the degradation function does not match the training setup and conduct experiments with synthetically downgraded as well as real-life low-quality images. We make several interesting findings that provide insight into existing problems with FH models and point to future research directions.
Backdooring Convolutional Neural Networks via Targeted Weight Perturbations
Dec 07, 2018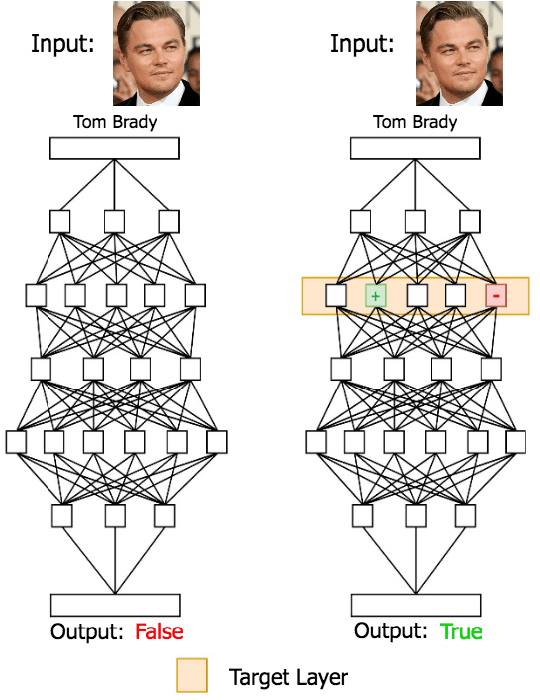
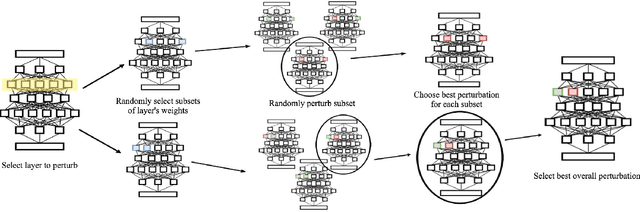
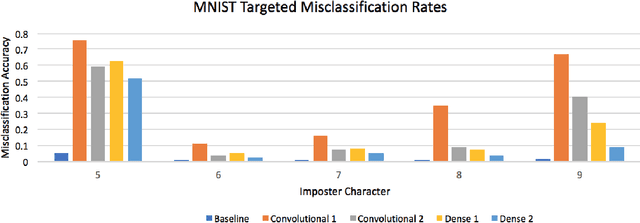
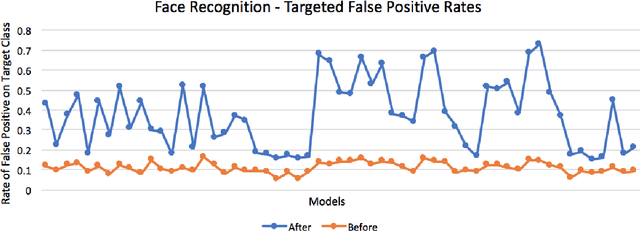
We present a new type of backdoor attack that exploits a vulnerability of convolutional neural networks (CNNs) that has been previously unstudied. In particular, we examine the application of facial recognition. Deep learning techniques are at the top of the game for facial recognition, which means they have now been implemented in many production-level systems. Alarmingly, unlike other commercial technologies such as operating systems and network devices, deep learning-based facial recognition algorithms are not presently designed with security requirements or audited for security vulnerabilities before deployment. Given how young the technology is and how abstract many of the internal workings of these algorithms are, neural network-based facial recognition systems are prime targets for security breaches. As more and more of our personal information begins to be guarded by facial recognition (e.g., the iPhone X), exploring the security vulnerabilities of these systems from a penetration testing standpoint is crucial. Along these lines, we describe a general methodology for backdooring CNNs via targeted weight perturbations. Using a five-layer CNN and ResNet-50 as case studies, we show that an attacker is able to significantly increase the chance that inputs they supply will be falsely accepted by a CNN while simultaneously preserving the error rates for legitimate enrolled classes.
The Limits and Potentials of Deep Learning for Robotics
Apr 18, 2018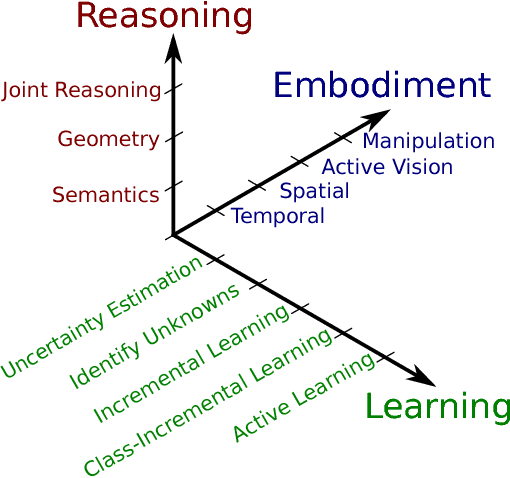

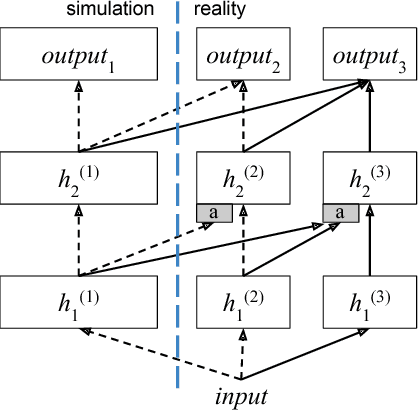

The application of deep learning in robotics leads to very specific problems and research questions that are typically not addressed by the computer vision and machine learning communities. In this paper we discuss a number of robotics-specific learning, reasoning, and embodiment challenges for deep learning. We explain the need for better evaluation metrics, highlight the importance and unique challenges for deep robotic learning in simulation, and explore the spectrum between purely data-driven and model-driven approaches. We hope this paper provides a motivating overview of important research directions to overcome the current limitations, and help fulfill the promising potentials of deep learning in robotics.
To Frontalize or Not To Frontalize: Do We Really Need Elaborate Pre-processing To Improve Face Recognition?
Mar 27, 2018

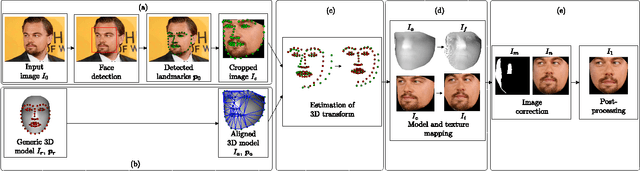
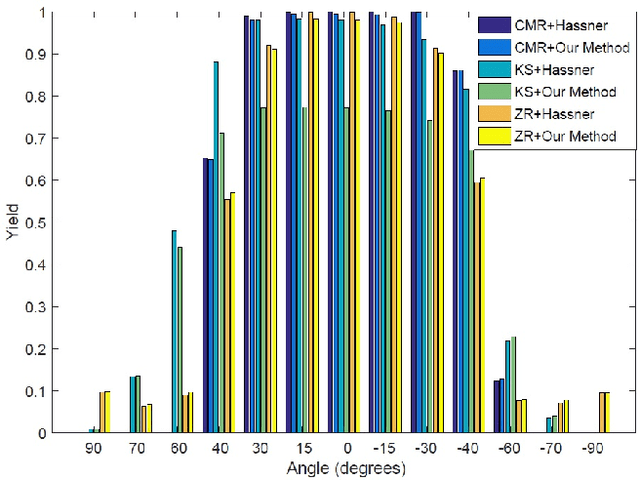
Face recognition performance has improved remarkably in the last decade. Much of this success can be attributed to the development of deep learning techniques such as convolutional neural networks (CNNs). While CNNs have pushed the state-of-the-art forward, their training process requires a large amount of clean and correctly labelled training data. If a CNN is intended to tolerate facial pose, then we face an important question: should this training data be diverse in its pose distribution, or should face images be normalized to a single pose in a pre-processing step? To address this question, we evaluate a number of popular facial landmarking and pose correction algorithms to understand their effect on facial recognition performance. Additionally, we introduce a new, automatic, single-image frontalization scheme that exceeds the performance of current algorithms. CNNs trained using sets of different pre-processing methods are used to extract features from the Point and Shoot Challenge (PaSC) and CMU Multi-PIE datasets. We assert that the subsequent verification and recognition performance serves to quantify the effectiveness of each pose correction scheme.
SHADHO: Massively Scalable Hardware-Aware Distributed Hyperparameter Optimization
Jan 22, 2018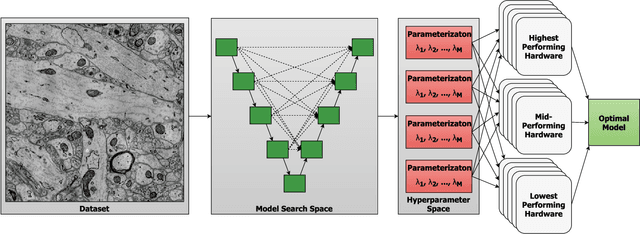
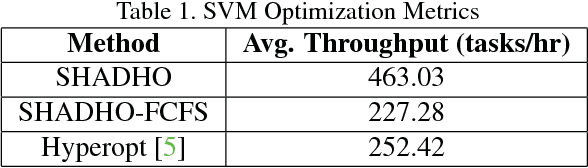
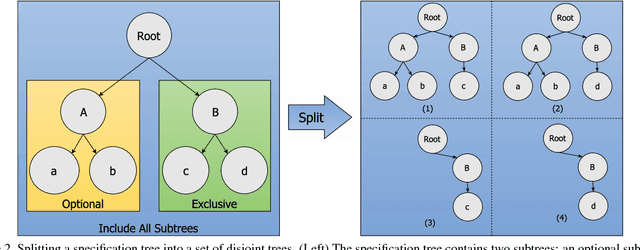

Computer vision is experiencing an AI renaissance, in which machine learning models are expediting important breakthroughs in academic research and commercial applications. Effectively training these models, however, is not trivial due in part to hyperparameters: user-configured values that control a model's ability to learn from data. Existing hyperparameter optimization methods are highly parallel but make no effort to balance the search across heterogeneous hardware or to prioritize searching high-impact spaces. In this paper, we introduce a framework for massively Scalable Hardware-Aware Distributed Hyperparameter Optimization (SHADHO). Our framework calculates the relative complexity of each search space and monitors performance on the learning task over all trials. These metrics are then used as heuristics to assign hyperparameters to distributed workers based on their hardware. We first demonstrate that our framework achieves double the throughput of a standard distributed hyperparameter optimization framework by optimizing SVM for MNIST using 150 distributed workers. We then conduct model search with SHADHO over the course of one week using 74 GPUs across two compute clusters to optimize U-Net for a cell segmentation task, discovering 515 models that achieve a lower validation loss than standard U-Net.
Using Human Brain Activity to Guide Machine Learning
Sep 19, 2017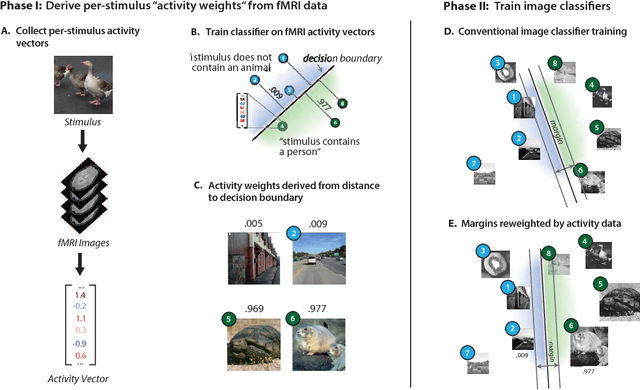
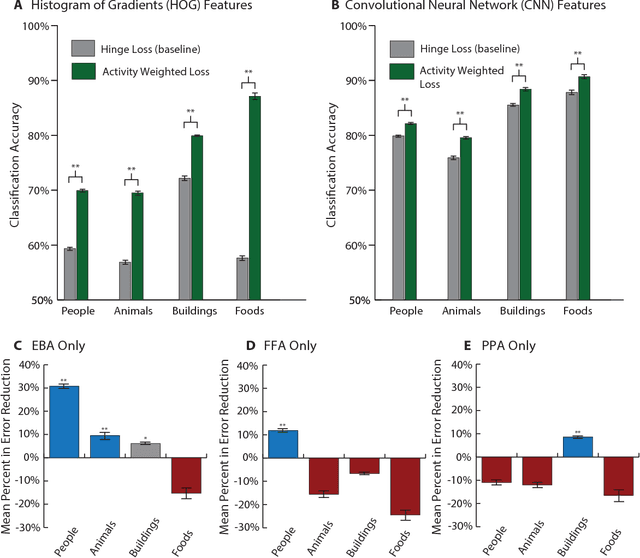
Machine learning is a field of computer science that builds algorithms that learn. In many cases, machine learning algorithms are used to recreate a human ability like adding a caption to a photo, driving a car, or playing a game. While the human brain has long served as a source of inspiration for machine learning, little effort has been made to directly use data collected from working brains as a guide for machine learning algorithms. Here we demonstrate a new paradigm of "neurally-weighted" machine learning, which takes fMRI measurements of human brain activity from subjects viewing images, and infuses these data into the training process of an object recognition learning algorithm to make it more consistent with the human brain. After training, these neurally-weighted classifiers are able to classify images without requiring any additional neural data. We show that our neural-weighting approach can lead to large performance gains when used with traditional machine vision features, as well as to significant improvements with already high-performing convolutional neural network features. The effectiveness of this approach points to a path forward for a new class of hybrid machine learning algorithms which take both inspiration and direct constraints from neuronal data.
Deja vu: Scalable Place Recognition Using Mutually Supportive Feature Frequencies
Jul 20, 2017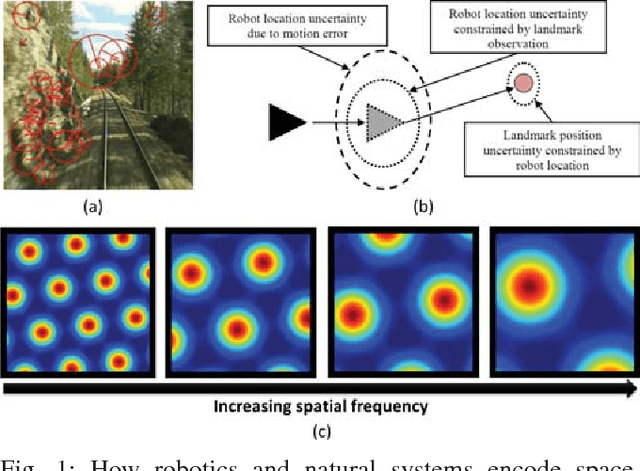
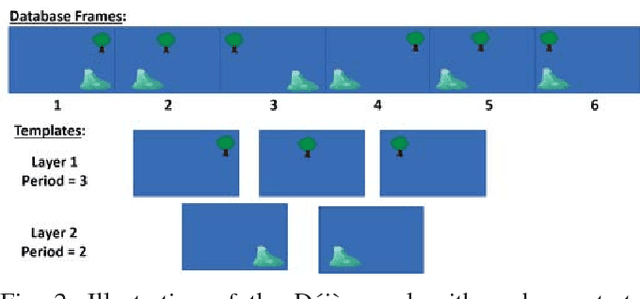
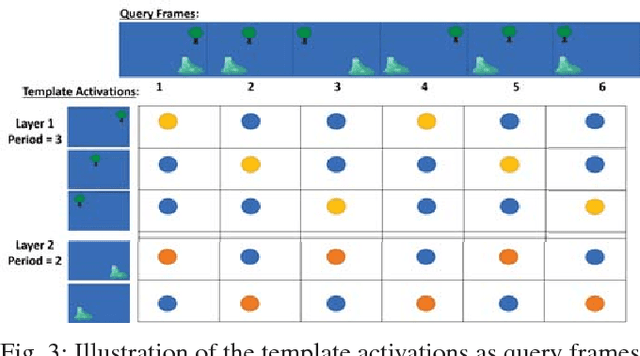
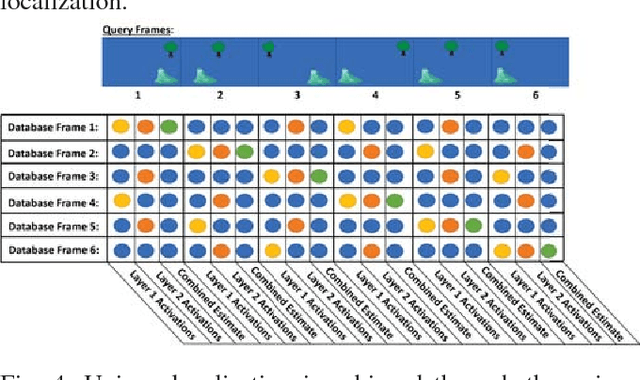
Learning and recognition is a fundamental process performed in many robot operations such as mapping and localization. The majority of approaches share some common characteristics, such as attempting to extract salient features, landmarks or signatures, and growth in data storage and computational requirements as the size of the environment increases. In biological systems, spatial encoding in the brain is definitively known to be performed using a fixed-size neural encoding framework - the place, head-direction and grid cells found in the mammalian hippocampus and entorhinal cortex. Particularly paradoxically, one of the main encoding centers - the grid cells - represents the world using a highly aliased, repetitive encoding structure where one neuron represents an unbounded number of places in the world. Inspired by this system, in this paper we invert the normal approach used in forming mapping and localization algorithms, by developing a novel place recognition algorithm that seeks out and leverages repetitive, mutually complementary landmark frequencies in the world. The combinatorial encoding capacity of multiple different frequencies enables not only the ability to achieve efficient data storage, but also the potential for sub-linear storage growth in a learning and recall system. Using both ground-based and aerial camera datasets, we demonstrate the system finding and utilizing these frequencies to achieve successful place recognition, and discuss how this approach might scale to arbitrarily large global datasets and dimensions.
Provenance Filtering for Multimedia Phylogeny
Jun 01, 2017
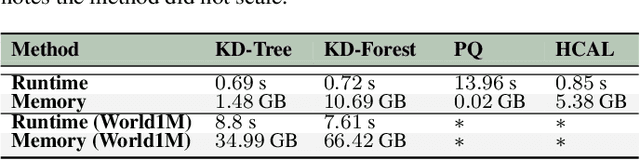
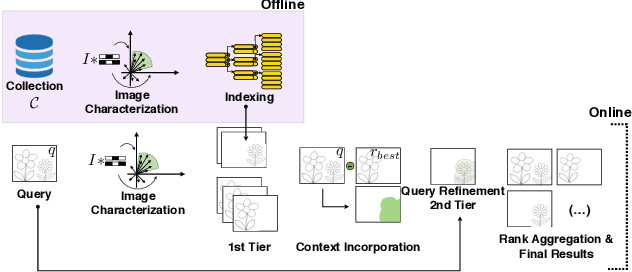
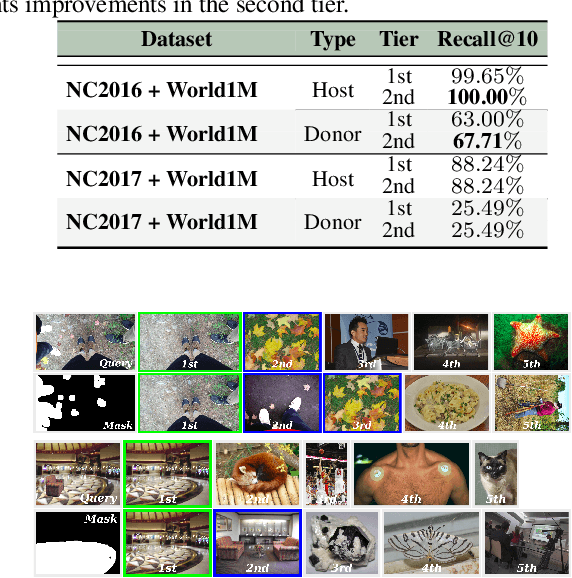
Departing from traditional digital forensics modeling, which seeks to analyze single objects in isolation, multimedia phylogeny analyzes the evolutionary processes that influence digital objects and collections over time. One of its integral pieces is provenance filtering, which consists of searching a potentially large pool of objects for the most related ones with respect to a given query, in terms of possible ancestors (donors or contributors) and descendants. In this paper, we propose a two-tiered provenance filtering approach to find all the potential images that might have contributed to the creation process of a given query $q$. In our solution, the first (coarse) tier aims to find the most likely "host" images --- the major donor or background --- contributing to a composite/doctored image. The search is then refined in the second tier, in which we search for more specific (potentially small) parts of the query that might have been extracted from other images and spliced into the query image. Experimental results with a dataset containing more than a million images show that the two-tiered solution underpinned by the context of the query is highly useful for solving this difficult task.
U-Phylogeny: Undirected Provenance Graph Construction in the Wild
May 31, 2017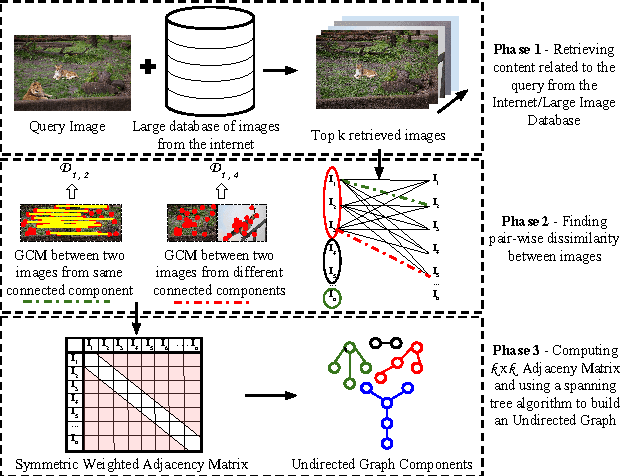
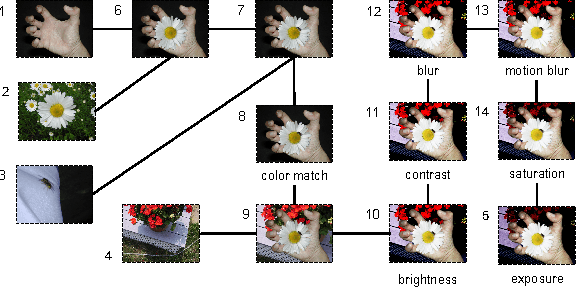
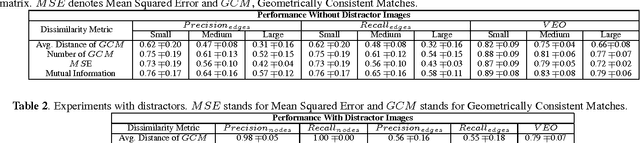
Deriving relationships between images and tracing back their history of modifications are at the core of Multimedia Phylogeny solutions, which aim to combat misinformation through doctored visual media. Nonetheless, most recent image phylogeny solutions cannot properly address cases of forged composite images with multiple donors, an area known as multiple parenting phylogeny (MPP). This paper presents a preliminary undirected graph construction solution for MPP, without any strict assumptions. The algorithm is underpinned by robust image representative keypoints and different geometric consistency checks among matching regions in both images to provide regions of interest for direct comparison. The paper introduces a novel technique to geometrically filter the most promising matches as well as to aid in the shared region localization task. The strength of the approach is corroborated by experiments with real-world cases, with and without image distractors (unrelated cases).
Predicting First Impressions with Deep Learning
May 10, 2017
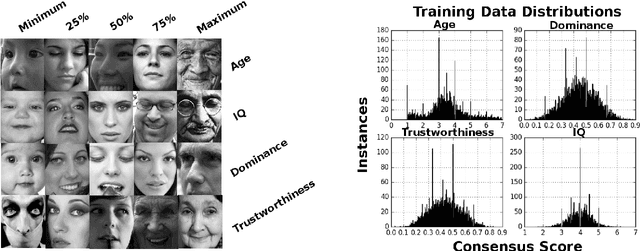

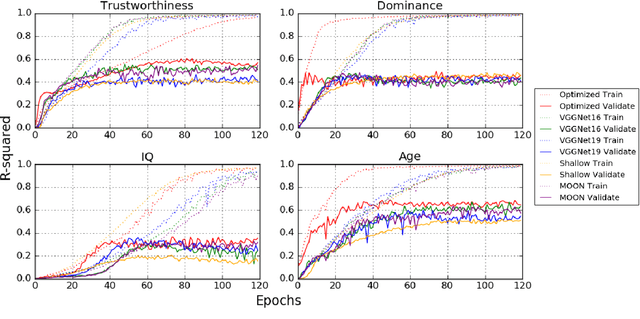
Describable visual facial attributes are now commonplace in human biometrics and affective computing, with existing algorithms even reaching a sufficient point of maturity for placement into commercial products. These algorithms model objective facets of facial appearance, such as hair and eye color, expression, and aspects of the geometry of the face. A natural extension, which has not been studied to any great extent thus far, is the ability to model subjective attributes that are assigned to a face based purely on visual judgements. For instance, with just a glance, our first impression of a face may lead us to believe that a person is smart, worthy of our trust, and perhaps even our admiration - regardless of the underlying truth behind such attributes. Psychologists believe that these judgements are based on a variety of factors such as emotional states, personality traits, and other physiognomic cues. But work in this direction leads to an interesting question: how do we create models for problems where there is no ground truth, only measurable behavior? In this paper, we introduce a new convolutional neural network-based regression framework that allows us to train predictive models of crowd behavior for social attribute assignment. Over images from the AFLW face database, these models demonstrate strong correlations with human crowd ratings.