 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Structure and Word Relationship Modeling for Emphasis Selection
Aug 29, 2021
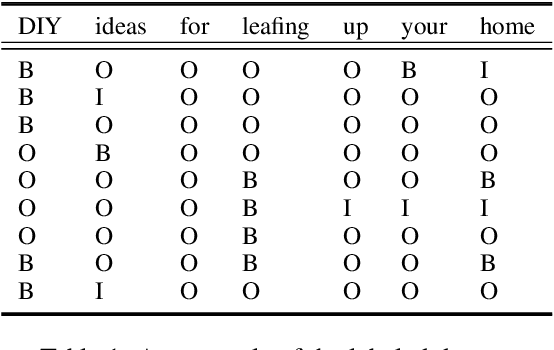
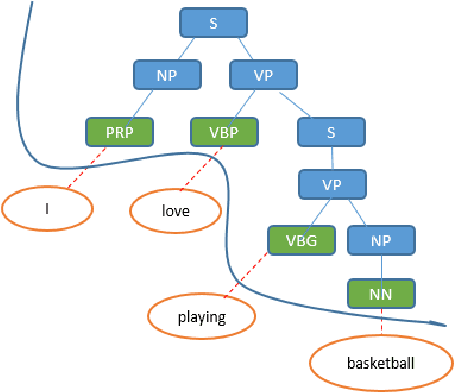
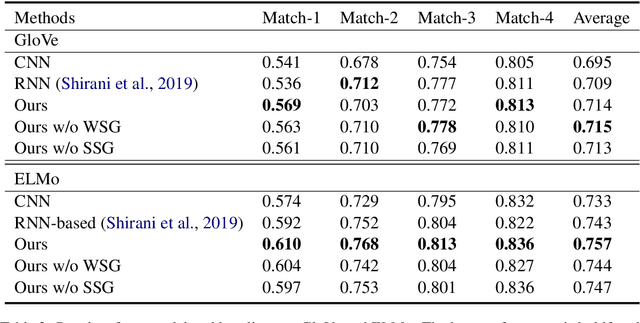
Emphasis Selection is a newly proposed task which focuses on choosing words for emphasis in short sentences. Traditional methods only consider the sequence information of a sentence while ignoring the rich sentence structure and word relationship information. In this paper, we propose a new framework that considers sentence structure via a sentence structure graph and word relationship via a word similarity graph. The sentence structure graph is derived from the parse tree of a sentence. The word similarity graph allows nodes to share information with their neighbors since we argue that in emphasis selection, similar words are more likely to be emphasized together. Graph neural networks are employed to learn the representation of each node of these two graphs. Experimental results demonstrate that our framework can achieve superior performance.
Learning to Rank Question Answer Pairs with Bilateral Contrastive Data Augmentation
Jun 21, 2021
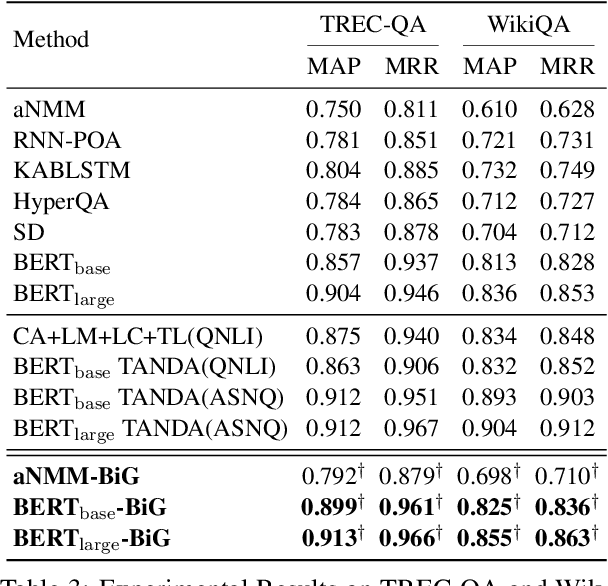
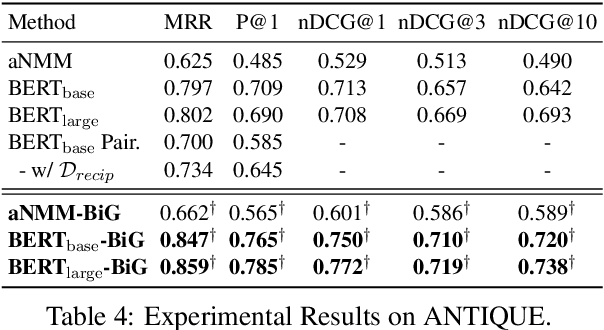
In this work, we propose a novel and easy-to-apply data augmentation strategy, namely Bilateral Generation (BiG), with a contrastive training objective for improving the performance of ranking question answer pairs with existing labeled data. In specific, we synthesize pseudo-positive QA pairs in contrast to the original negative QA pairs with two pre-trained generation models, one for question generation, the other for answer generation, which are fine-tuned on the limited positive QA pairs from the original dataset. With the augmented dataset, we design a contrastive training objective for learning to rank question answer pairs. Experimental results on three benchmark datasets, namely TREC-QA, WikiQA, and ANTIQUE, show that our method significantly improves the performance of ranking models by making full use of existing labeled data and can be easily applied to different ranking models.
Conversational Fashion Image Retrieval via Multiturn Natural Language Feedback
Jun 08, 2021
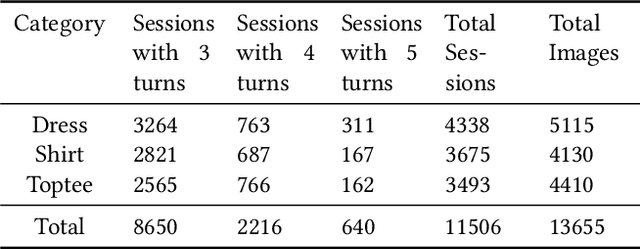
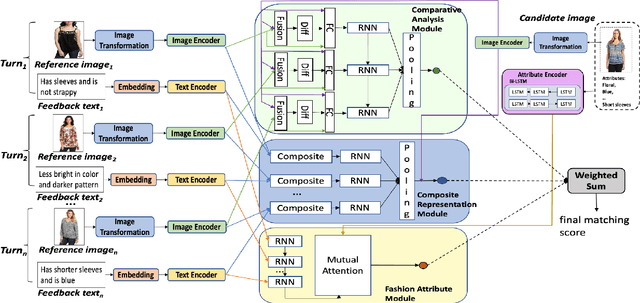
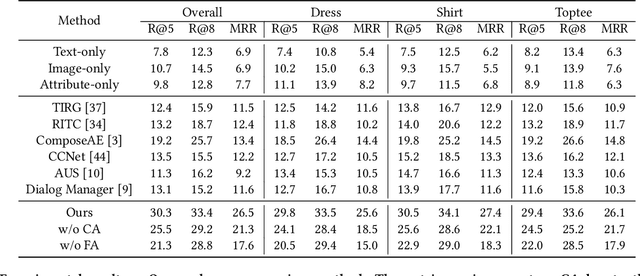
We study the task of conversational fashion image retrieval via multiturn natural language feedback. Most previous studies are based on single-turn settings. Existing models on multiturn conversational fashion image retrieval have limitations, such as employing traditional models, and leading to ineffective performance. We propose a novel framework that can effectively handle conversational fashion image retrieval with multiturn natural language feedback texts. One characteristic of the framework is that it searches for candidate images based on exploitation of the encoded reference image and feedback text information together with the conversation history. Furthermore, the image fashion attribute information is leveraged via a mutual attention strategy. Since there is no existing fashion dataset suitable for the multiturn setting of our task, we derive a large-scale multiturn fashion dataset via additional manual annotation efforts on an existing single-turn dataset. The experiments show that our proposed model significantly outperforms existing state-of-the-art methods.
Neural Machine Translation with Monolingual Translation Memory
Jun 02, 2021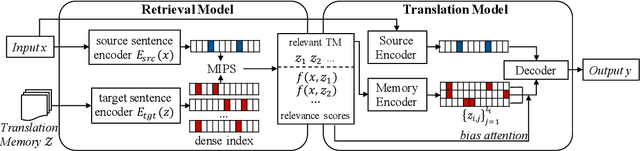
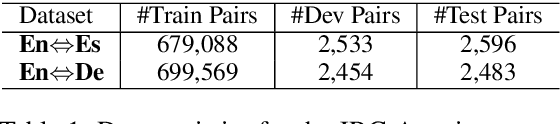
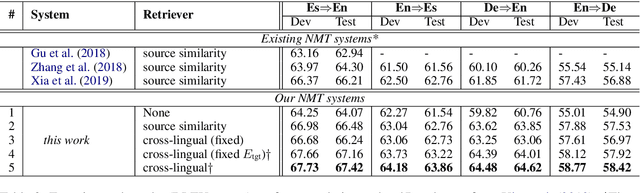
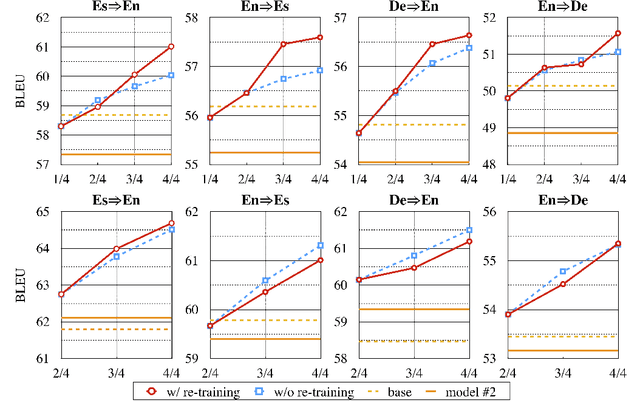
Prior work has proved that Translation memory (TM) can boost the performance of Neural Machine Translation (NMT). In contrast to existing work that uses bilingual corpus as TM and employs source-side similarity search for memory retrieval, we propose a new framework that uses monolingual memory and performs learnable memory retrieval in a cross-lingual manner. Our framework has unique advantages. First, the cross-lingual memory retriever allows abundant monolingual data to be TM. Second, the memory retriever and NMT model can be jointly optimized for the ultimate translation goal. Experiments show that the proposed method obtains substantial improvements. Remarkably, it even outperforms strong TM-augmented NMT baselines using bilingual TM. Owning to the ability to leverage monolingual data, our model also demonstrates effectiveness in low-resource and domain adaptation scenarios.
Dynamic Semantic Graph Construction and Reasoning for Explainable Multi-hop Science Question Answering
May 25, 2021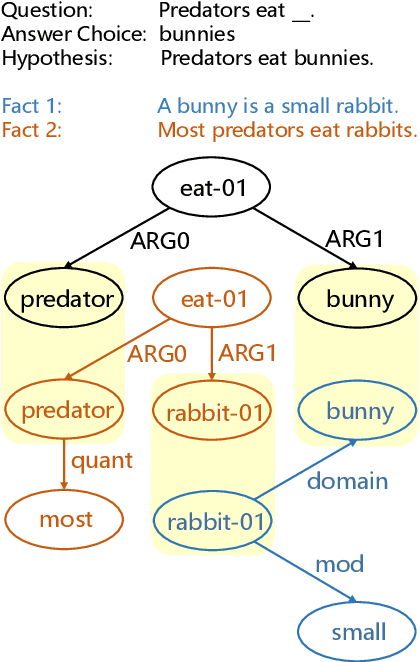
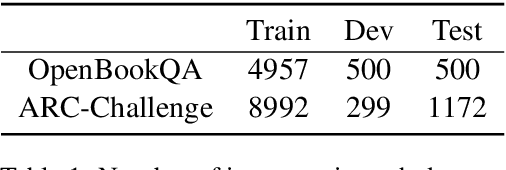
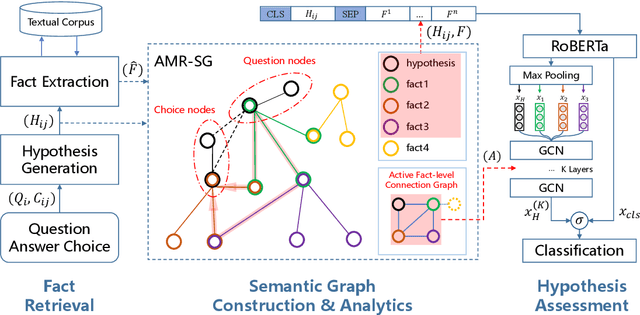
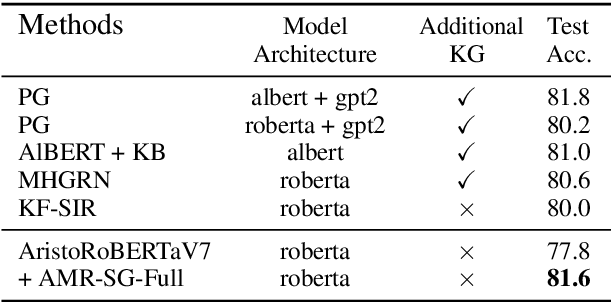
Knowledge retrieval and reasoning are two key stages in multi-hop question answering (QA) at web scale. Existing approaches suffer from low confidence when retrieving evidence facts to fill the knowledge gap and lack transparent reasoning process. In this paper, we propose a new framework to exploit more valid facts while obtaining explainability for multi-hop QA by dynamically constructing a semantic graph and reasoning over it. We employ Abstract Meaning Representation (AMR) as semantic graph representation. Our framework contains three new ideas: (a) {\tt AMR-SG}, an AMR-based Semantic Graph, constructed by candidate fact AMRs to uncover any hop relations among question, answer and multiple facts. (b) A novel path-based fact analytics approach exploiting {\tt AMR-SG} to extract active facts from a large fact pool to answer questions. (c) A fact-level relation modeling leveraging graph convolution network (GCN) to guide the reasoning process. Results on two scientific multi-hop QA datasets show that we can surpass recent approaches including those using additional knowledge graphs while maintaining high explainability on OpenBookQA and achieve a new state-of-the-art result on ARC-Challenge in a computationally practicable setting.
Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning
May 20, 2021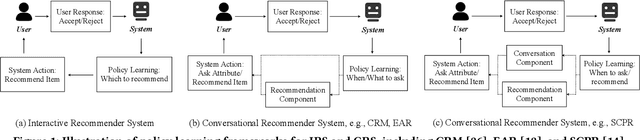
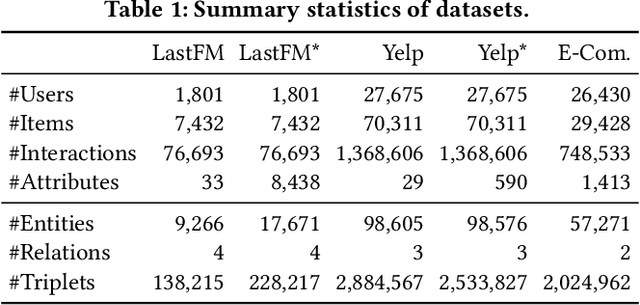
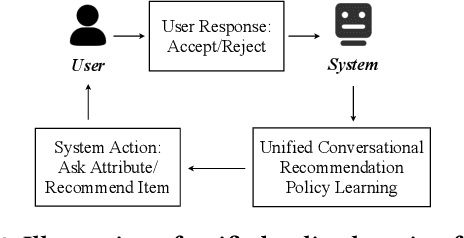
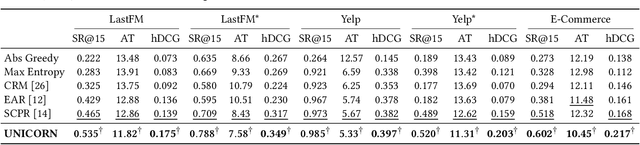
Conversational recommender systems (CRS) enable the traditional recommender systems to explicitly acquire user preferences towards items and attributes through interactive conversations. Reinforcement learning (RL) is widely adopted to learn conversational recommendation policies to decide what attributes to ask, which items to recommend, and when to ask or recommend, at each conversation turn. However, existing methods mainly target at solving one or two of these three decision-making problems in CRS with separated conversation and recommendation components, which restrict the scalability and generality of CRS and fall short of preserving a stable training procedure. In the light of these challenges, we propose to formulate these three decision-making problems in CRS as a unified policy learning task. In order to systematically integrate conversation and recommendation components, we develop a dynamic weighted graph based RL method to learn a policy to select the action at each conversation turn, either asking an attribute or recommending items. Further, to deal with the sample efficiency issue, we propose two action selection strategies for reducing the candidate action space according to the preference and entropy information. Experimental results on two benchmark CRS datasets and a real-world E-Commerce application show that the proposed method not only significantly outperforms state-of-the-art methods but also enhances the scalability and stability of CRS.
Contextualized Knowledge-aware Attentive Neural Network: Enhancing Answer Selection with Knowledge
Apr 12, 2021
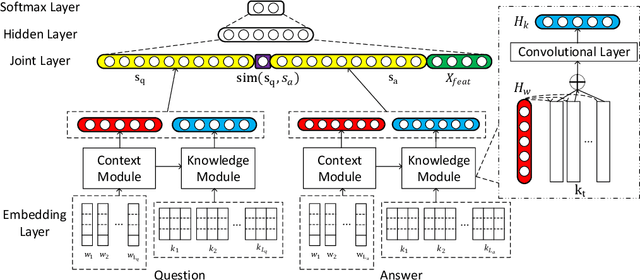
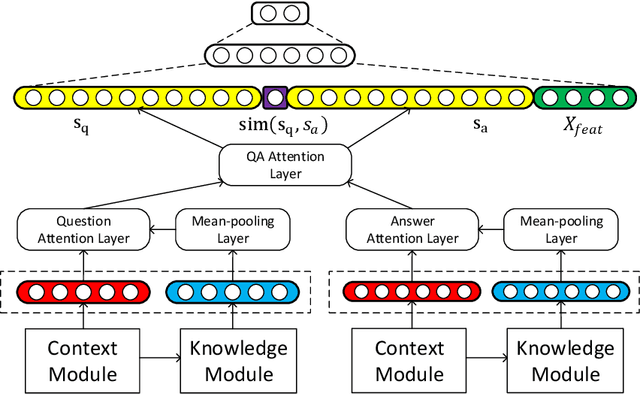
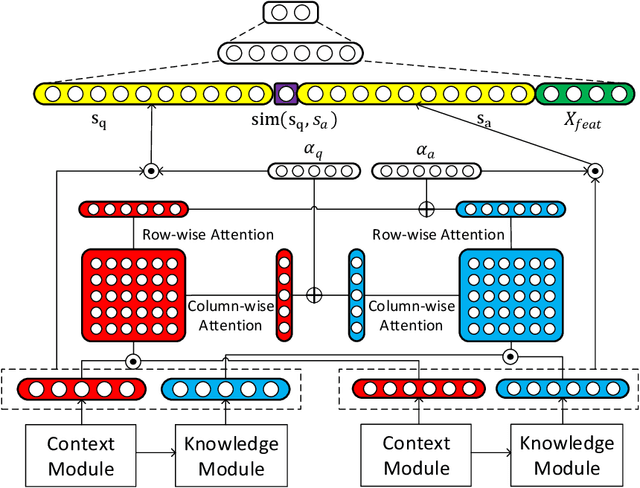
Answer selection, which is involved in many natural language processing applications such as dialog systems and question answering (QA), is an important yet challenging task in practice, since conventional methods typically suffer from the issues of ignoring diverse real-world background knowledge. In this paper, we extensively investigate approaches to enhancing the answer selection model with external knowledge from knowledge graph (KG). First, we present a context-knowledge interaction learning framework, Knowledge-aware Neural Network (KNN), which learns the QA sentence representations by considering a tight interaction with the external knowledge from KG and the textual information. Then, we develop two kinds of knowledge-aware attention mechanism to summarize both the context-based and knowledge-based interactions between questions and answers. To handle the diversity and complexity of KG information, we further propose a Contextualized Knowledge-aware Attentive Neural Network (CKANN), which improves the knowledge representation learning with structure information via a customized Graph Convolutional Network (GCN) and comprehensively learns context-based and knowledge-based sentence representation via the multi-view knowledge-aware attention mechanism. We evaluate our method on four widely-used benchmark QA datasets, including WikiQA, TREC QA, InsuranceQA and Yahoo QA. Results verify the benefits of incorporating external knowledge from KG, and show the robust superiority and extensive applicability of our method.
A Theoretical Analysis of the Repetition Problem in Text Generation
Jan 28, 2021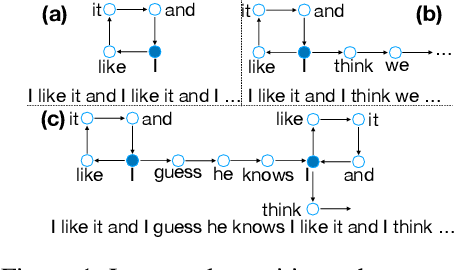
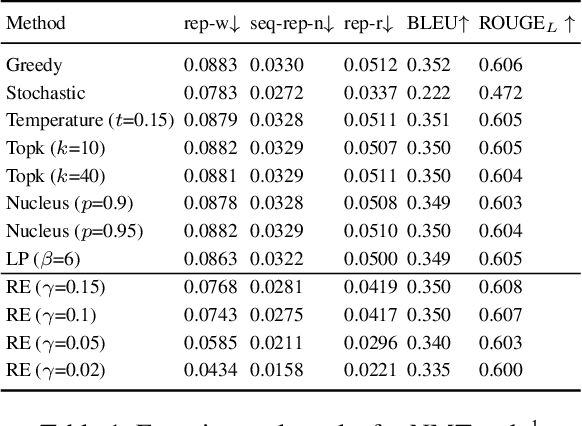
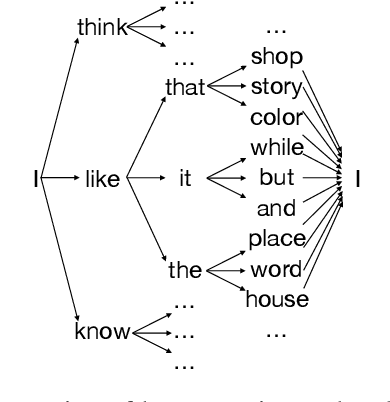
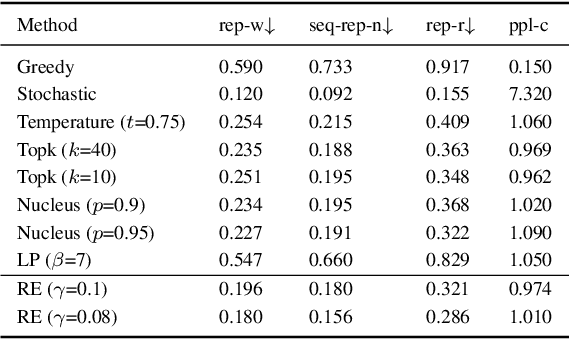
Text generation tasks, including translation, summarization, language models, and etc. see rapid growth during recent years. Despite the remarkable achievements, the repetition problem has been observed in nearly all text generation models undermining the generation performance extensively. To solve the repetition problem, many methods have been proposed, but there is no existing theoretical analysis to show why this problem happens and how it is resolved. In this paper, we propose a new framework for theoretical analysis for the repetition problem. We first define the Average Repetition Probability (ARP) to characterize the repetition problem quantitatively. Then, we conduct an extensive analysis of the Markov generation model and derive several upper bounds of the average repetition probability with intuitive understanding. We show that most of the existing methods are essentially minimizing the upper bounds explicitly or implicitly. Grounded on our theory, we show that the repetition problem is, unfortunately, caused by the traits of our language itself. One major reason is attributed to the fact that there exist too many words predicting the same word as the subsequent word with high probability. Consequently, it is easy to go back to that word and form repetitions and we dub it as the high inflow problem. Furthermore, we derive a concentration bound of the average repetition probability for a general generation model. Finally, based on the theoretical upper bounds, we propose a novel rebalanced encoding approach to alleviate the high inflow problem. The experimental results show that our theoretical framework is applicable in general generation models and our proposed rebalanced encoding approach alleviates the repetition problem significantly. The source code of this paper can be obtained from \url{https://github.com/fuzihaofzh/repetition-problem-nlg}.
Unstructured Knowledge Access in Task-oriented Dialog Modeling using Language Inference, Knowledge Retrieval and Knowledge-Integrative Response Generation
Jan 15, 2021
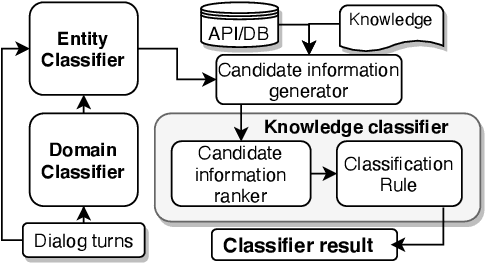

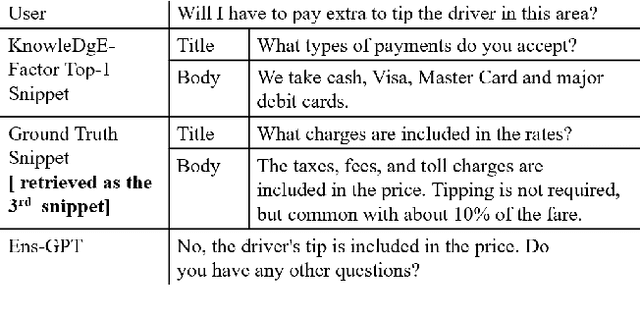
Dialog systems enriched with external knowledge can handle user queries that are outside the scope of the supporting databases/APIs. In this paper, we follow the baseline provided in DSTC9 Track 1 and propose three subsystems, KDEAK, KnowleDgEFactor, and Ens-GPT, which form the pipeline for a task-oriented dialog system capable of accessing unstructured knowledge. Specifically, KDEAK performs knowledge-seeking turn detection by formulating the problem as natural language inference using knowledge from dialogs, databases and FAQs. KnowleDgEFactor accomplishes the knowledge selection task by formulating a factorized knowledge/document retrieval problem with three modules performing domain, entity and knowledge level analyses. Ens-GPT generates a response by first processing multiple knowledge snippets, followed by an ensemble algorithm that decides if the response should be solely derived from a GPT2-XL model, or regenerated in combination with the top-ranking knowledge snippet. Experimental results demonstrate that the proposed pipeline system outperforms the baseline and generates high-quality responses, achieving at least 58.77% improvement on BLEU-4 score.
Narrative Incoherence Detection
Dec 21, 2020

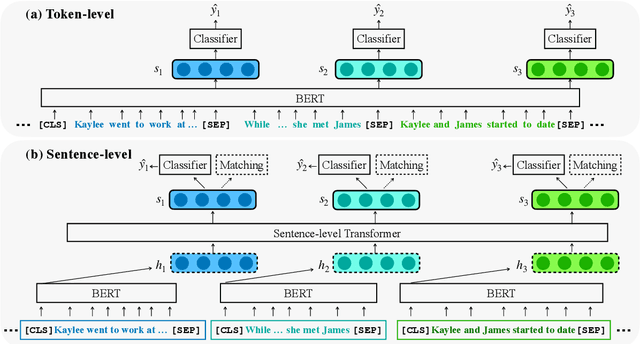
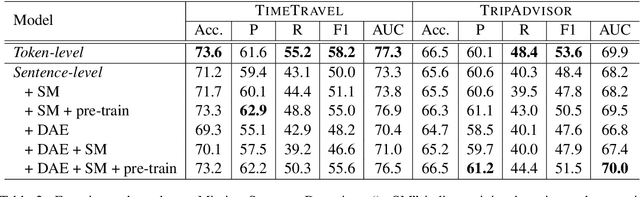
Motivated by the increasing popularity of intelligent editing assistant, we introduce and investigate the task of narrative incoherence detection: Given a (corrupted) long-form narrative, decide whether there exists some semantic discrepancy in the narrative flow. Specifically, we focus on the missing sentence and incoherent sentence detection. Despite its simple setup, this task is challenging as the model needs to understand and analyze a multi-sentence narrative text, and make decisions at the sentence level. As an initial step towards this task, we implement several baselines either directly analyzing the raw text (\textit{token-level}) or analyzing learned sentence representations (\textit{sentence-level}). We observe that while token-level modeling enjoys greater expressive power and hence better performance, sentence-level modeling possesses an advantage in efficiency and flexibility. With pre-training on large-scale data and cycle-consistent sentence embedding, our extended sentence-level model can achieve comparable detection accuracy to the token-level model. As a by-product, such a strategy enables simultaneous incoherence detection and infilling/modification suggestions.