 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data
Jun 02, 2021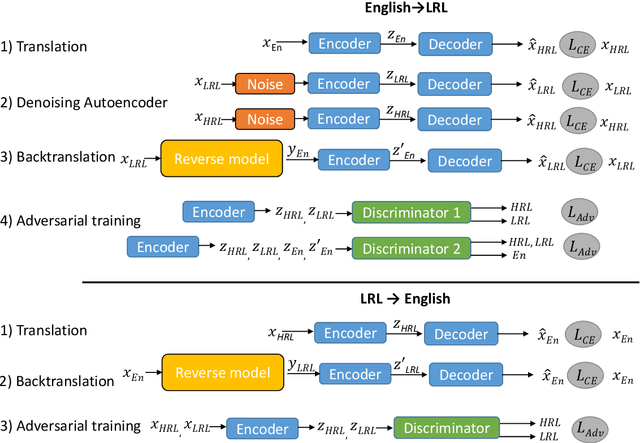
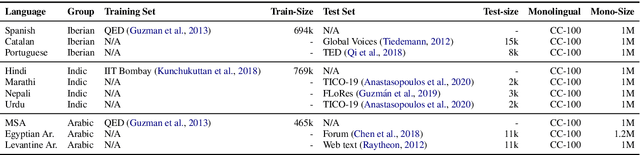
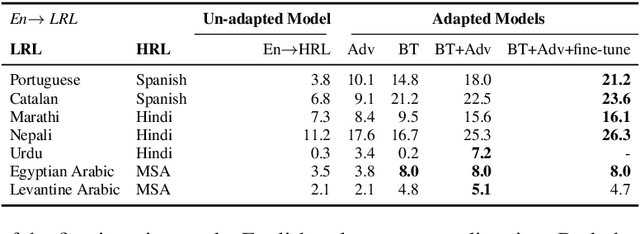
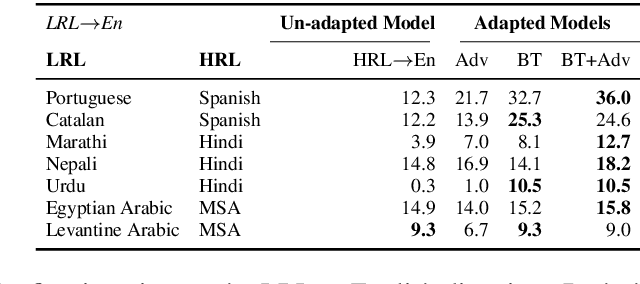
The scarcity of parallel data is a major obstacle for training high-quality machine translation systems for low-resource languages. Fortunately, some low-resource languages are linguistically related or similar to high-resource languages; these related languages may share many lexical or syntactic structures. In this work, we exploit this linguistic overlap to facilitate translating to and from a low-resource language with only monolingual data, in addition to any parallel data in the related high-resource language. Our method, NMT-Adapt, combines denoising autoencoding, back-translation and adversarial objectives to utilize monolingual data for low-resource adaptation. We experiment on 7 languages from three different language families and show that our technique significantly improves translation into low-resource language compared to other translation baselines.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021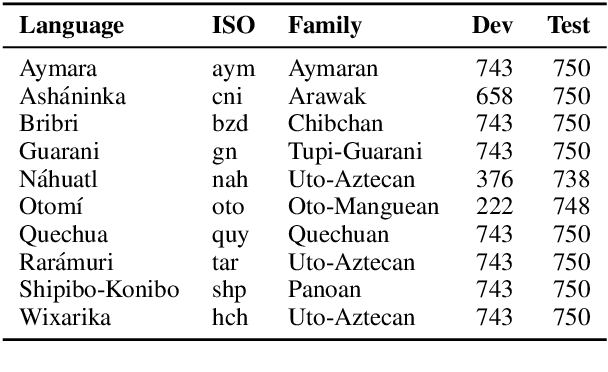
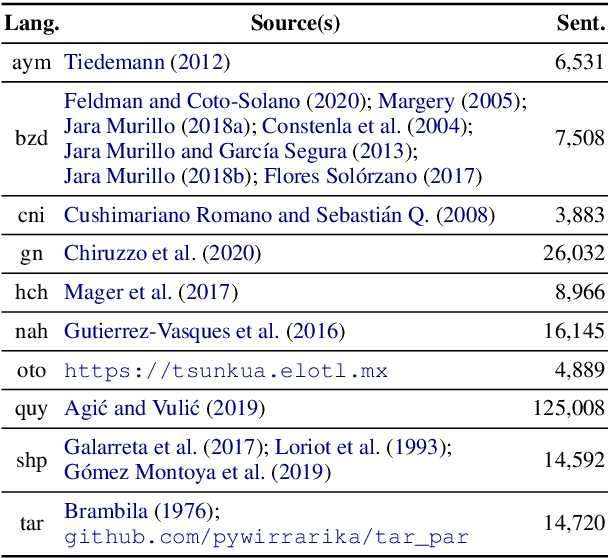
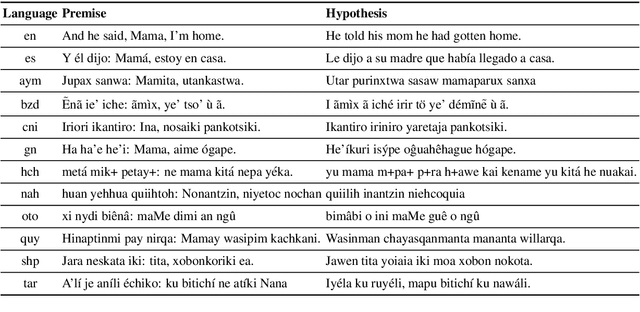

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
Quality Estimation without Human-labeled Data
Feb 08, 2021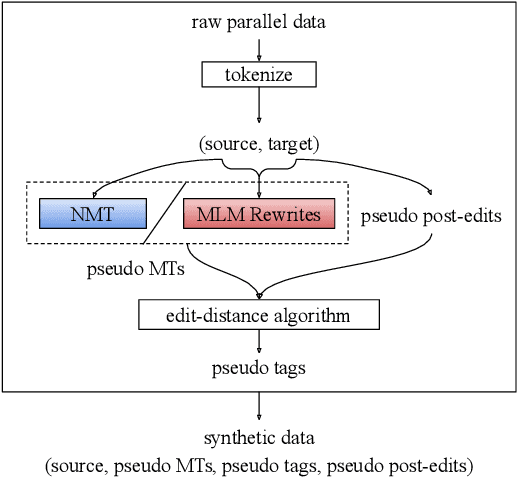
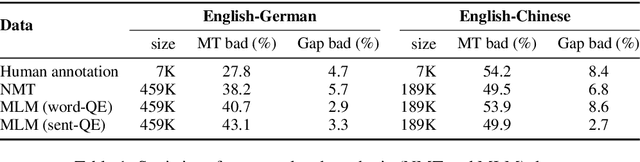
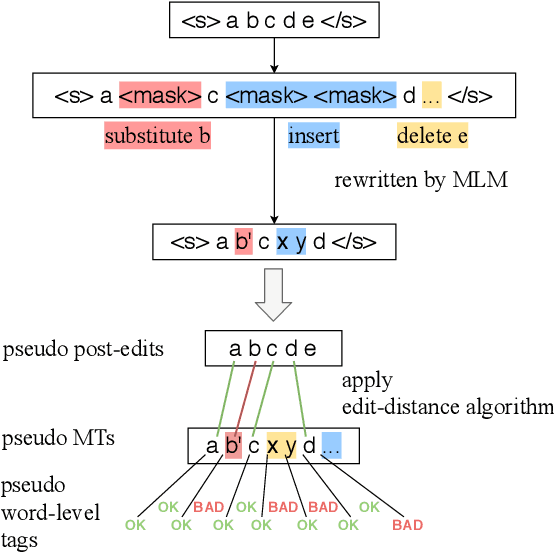
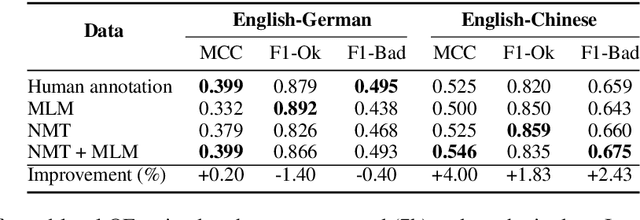
Quality estimation aims to measure the quality of translated content without access to a reference translation. This is crucial for machine translation systems in real-world scenarios where high-quality translation is needed. While many approaches exist for quality estimation, they are based on supervised machine learning requiring costly human labelled data. As an alternative, we propose a technique that does not rely on examples from human-annotators and instead uses synthetic training data. We train off-the-shelf architectures for supervised quality estimation on our synthetic data and show that the resulting models achieve comparable performance to models trained on human-annotated data, both for sentence and word-level prediction.
Beyond English-Centric Multilingual Machine Translation
Oct 21, 2020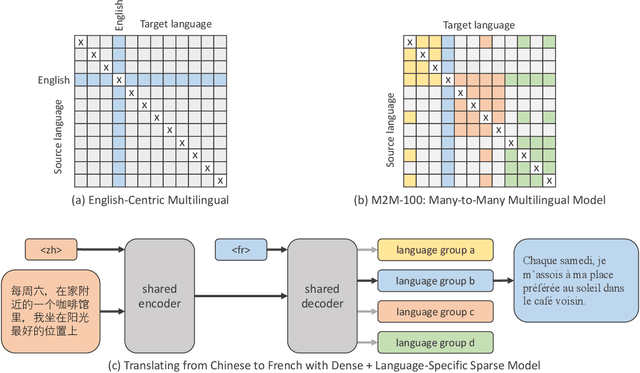
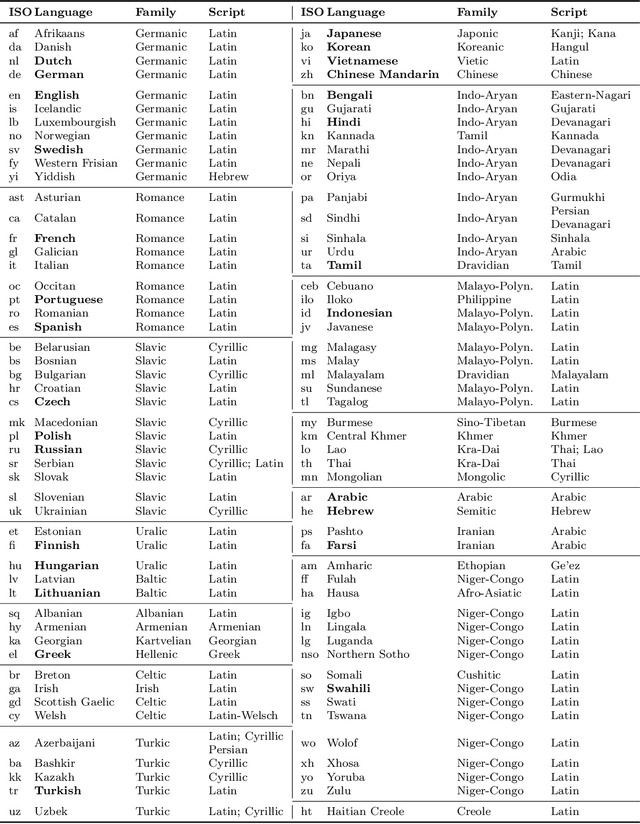
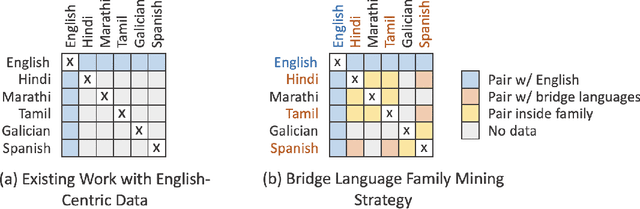

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
MLQE-PE: A Multilingual Quality Estimation and Post-Editing Dataset
Oct 09, 2020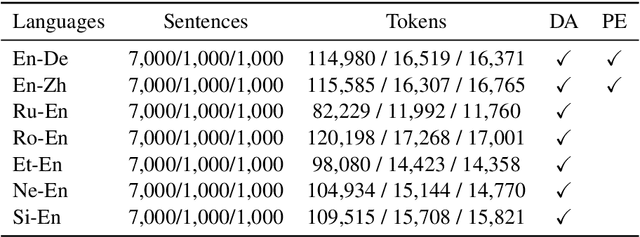
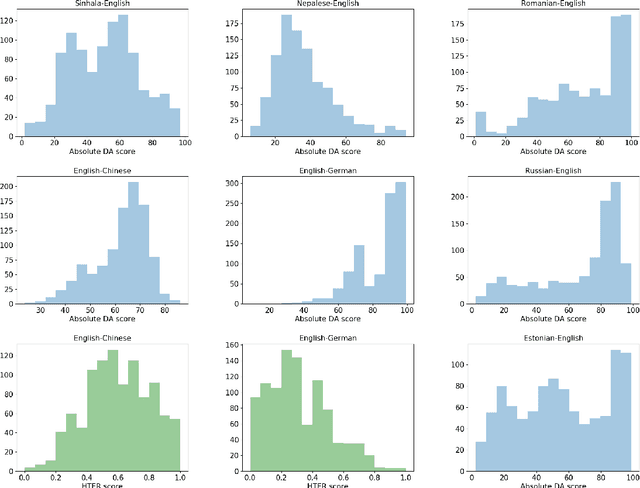
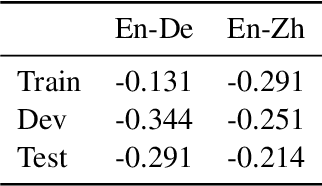
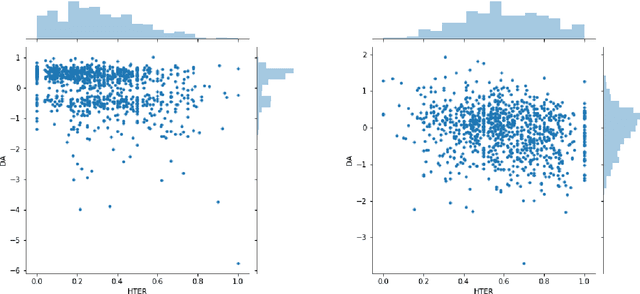
We present MLQE-PE, a new dataset for Machine Translation (MT) Quality Estimation (QE) and Automatic Post-Editing (APE). The dataset contains seven language pairs, with human labels for 9,000 translations per language pair in the following formats: sentence-level direct assessments and post-editing effort, and word-level good/bad labels. It also contains the post-edited sentences, as well as titles of the articles where the sentences were extracted from, and the neural MT models used to translate the text.
Self-training Improves Pre-training for Natural Language Understanding
Oct 05, 2020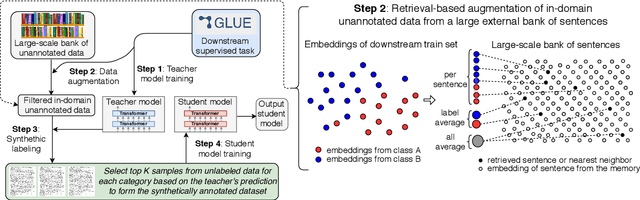
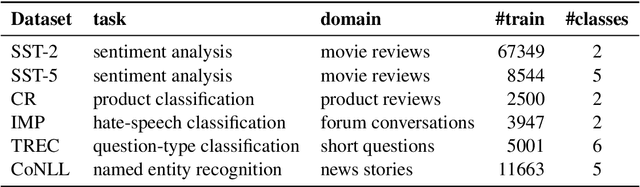
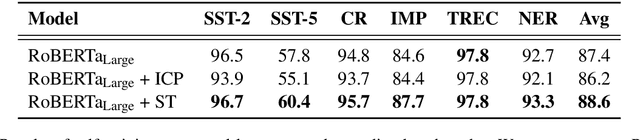

Unsupervised pre-training has led to much recent progress in natural language understanding. In this paper, we study self-training as another way to leverage unlabeled data through semi-supervised learning. To obtain additional data for a specific task, we introduce SentAugment, a data augmentation method which computes task-specific query embeddings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web. Unlike previous semi-supervised methods, our approach does not require in-domain unlabeled data and is therefore more generally applicable. Experiments show that self-training is complementary to strong RoBERTa baselines on a variety of tasks. Our augmentation approach leads to scalable and effective self-training with improvements of up to 2.6% on standard text classification benchmarks. Finally, we also show strong gains on knowledge-distillation and few-shot learning.
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning
Aug 02, 2020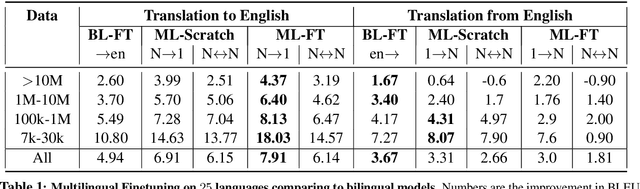
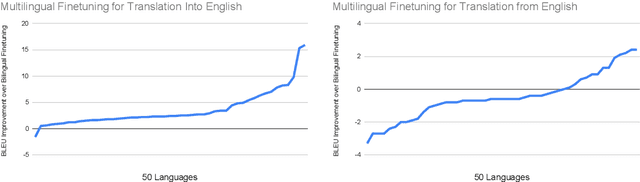
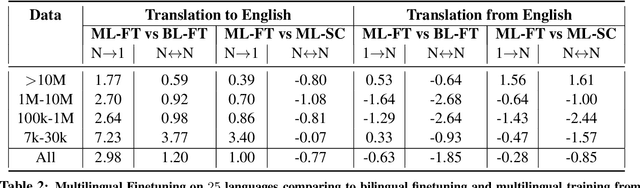
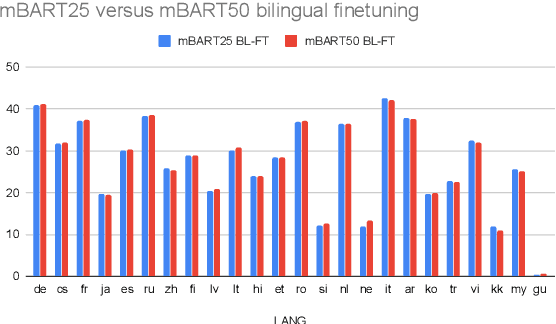
Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.
Unsupervised Quality Estimation for Neural Machine Translation
May 21, 2020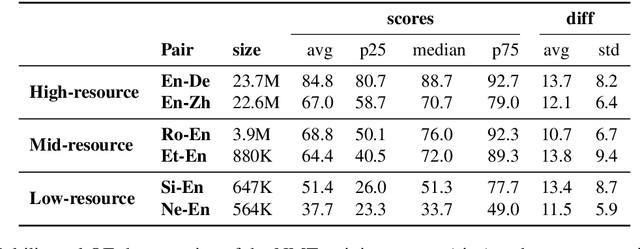
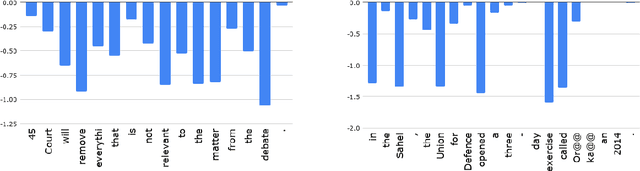
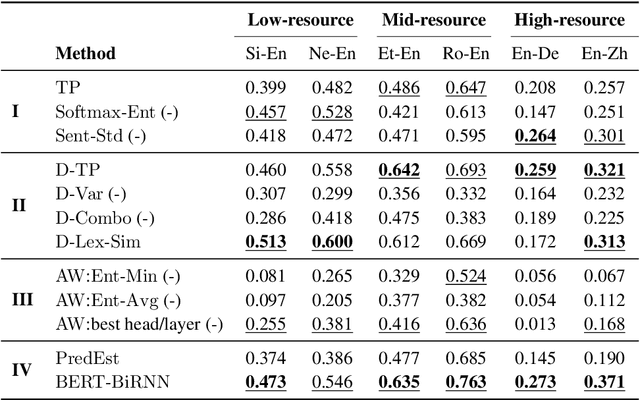
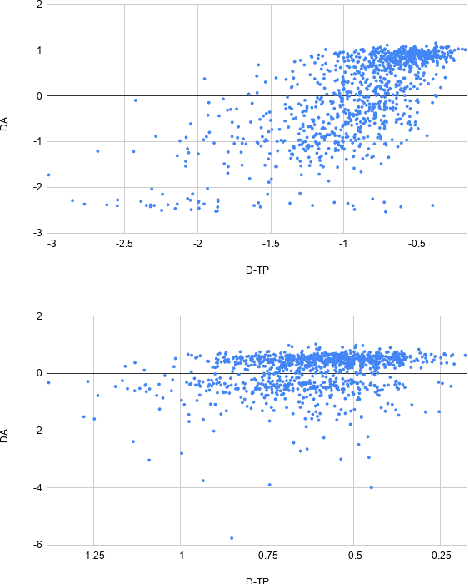
Quality Estimation (QE) is an important component in making Machine Translation (MT) useful in real-world applications, as it is aimed to inform the user on the quality of the MT output at test time. Existing approaches require large amounts of expert annotated data, computation and time for training. As an alternative, we devise an unsupervised approach to QE where no training or access to additional resources besides the MT system itself is required. Different from most of the current work that treats the MT system as a black box, we explore useful information that can be extracted from the MT system as a by-product of translation. By employing methods for uncertainty quantification, we achieve very good correlation with human judgments of quality, rivalling state-of-the-art supervised QE models. To evaluate our approach we collect the first dataset that enables work on both black-box and glass-box approaches to QE.
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Nov 15, 2019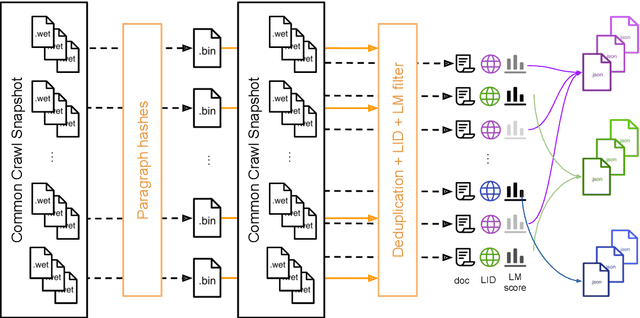
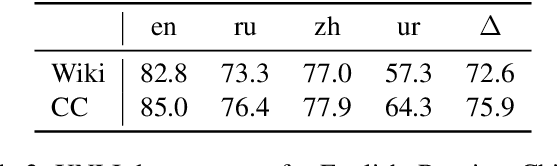
Pre-training text representations have led to significant improvements in many areas of natural language processing. The quality of these models benefits greatly from the size of the pretraining corpora as long as its quality is preserved. In this paper, we describe an automatic pipeline to extract massive high-quality monolingual datasets from Common Crawl for a variety of languages. Our pipeline follows the data processing introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that deduplicates documents and identifies their language. We augment this pipeline with a filtering step to select documents that are close to high quality corpora like Wikipedia.
A Massive Collection of Cross-Lingual Web-Document Pairs
Nov 10, 2019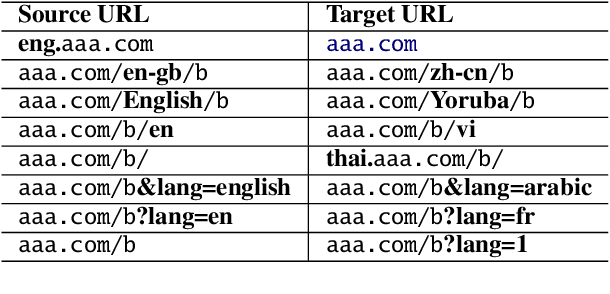

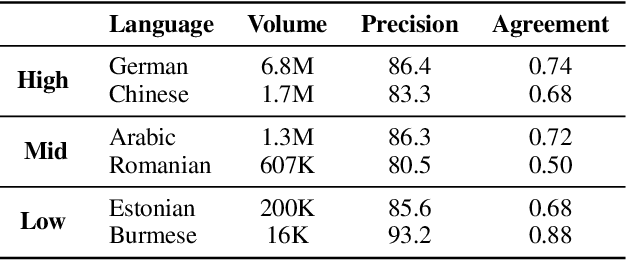

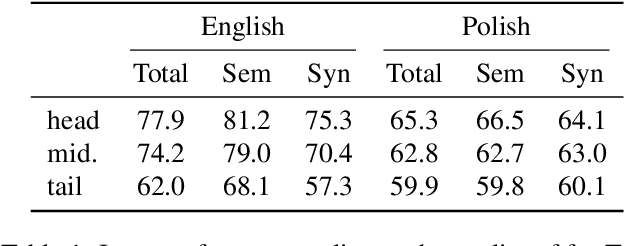
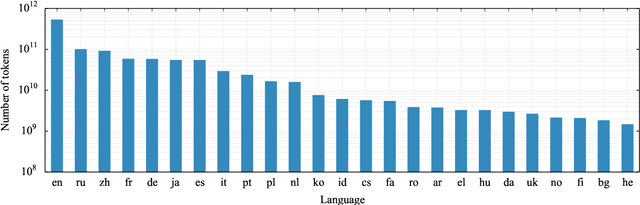
Cross-lingual document alignment aims to identify pairs of documents in two distinct languages that are of comparable content or translations of each other. Small-scale efforts have been made to collect aligned document level data on a limited set of language-pairs such as English-German or on limited comparable collections such as Wikipedia. In this paper, we mine twelve snapshots of the Common Crawl corpus and identify web document pairs that are translations of each other. We release a new web dataset consisting of 54 million URL pairs from Common Crawl covering documents in 92 languages paired with English. We evaluate the quality of the dataset by measuring the quality of machine translations from models that have been trained on mined parallel sentence pairs from this aligned corpora and introduce a simple yet effective baseline for identifying these aligned documents. The objective of this dataset and paper is to foster new research in cross-lingual NLP across a variety of low, mid, and high-resource languages.