 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Classification of US Supreme Court Cases using BERT-Based Techniques
Apr 17, 2023



Models based on bidirectional encoder representations from transformers (BERT) produce state of the art (SOTA) results on many natural language processing (NLP) tasks such as named entity recognition (NER), part-of-speech (POS) tagging etc. An interesting phenomenon occurs when classifying long documents such as those from the US supreme court where BERT-based models can be considered difficult to use on a first-pass or out-of-the-box basis. In this paper, we experiment with several BERT-based classification techniques for US supreme court decisions or supreme court database (SCDB) and compare them with the previous SOTA results. We then compare our results specifically with SOTA models for long documents. We compare our results for two classification tasks: (1) a broad classification task with 15 categories and (2) a fine-grained classification task with 279 categories. Our best result produces an accuracy of 80\% on the 15 broad categories and 60\% on the fine-grained 279 categories which marks an improvement of 8\% and 28\% respectively from previously reported SOTA results.
ON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

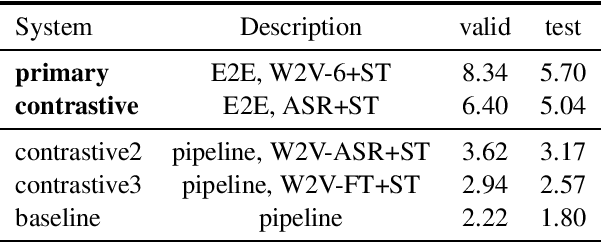

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
Findings of the LoResMT 2021 Shared Task on COVID and Sign Language for Low-resource Languages
Aug 18, 2021

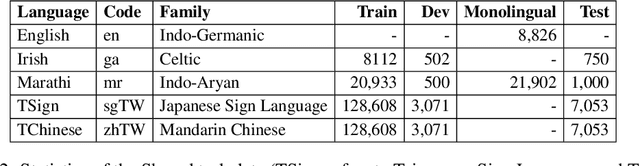
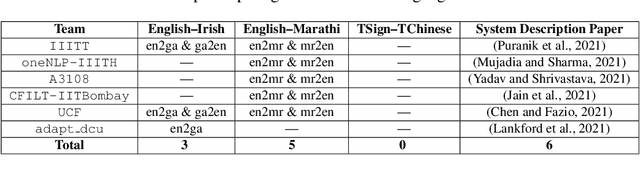
We present the findings of the LoResMT 2021 shared task which focuses on machine translation (MT) of COVID-19 data for both low-resource spoken and sign languages. The organization of this task was conducted as part of the fourth workshop on technologies for machine translation of low resource languages (LoResMT). Parallel corpora is presented and publicly available which includes the following directions: English$\leftrightarrow$Irish, English$\leftrightarrow$Marathi, and Taiwanese Sign language$\leftrightarrow$Traditional Chinese. Training data consists of 8112, 20933 and 128608 segments, respectively. There are additional monolingual data sets for Marathi and English that consist of 21901 segments. The results presented here are based on entries from a total of eight teams. Three teams submitted systems for English$\leftrightarrow$Irish while five teams submitted systems for English$\leftrightarrow$Marathi. Unfortunately, there were no systems submissions for the Taiwanese Sign language$\leftrightarrow$Traditional Chinese task. Maximum system performance was computed using BLEU and follow as 36.0 for English--Irish, 34.6 for Irish--English, 24.2 for English--Marathi, and 31.3 for Marathi--English.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021
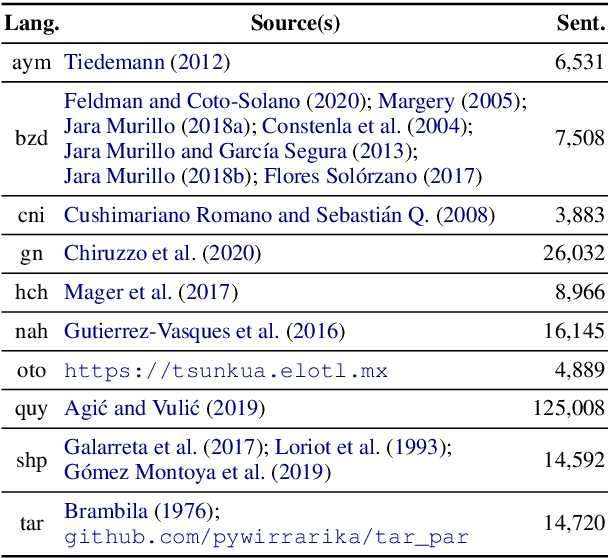
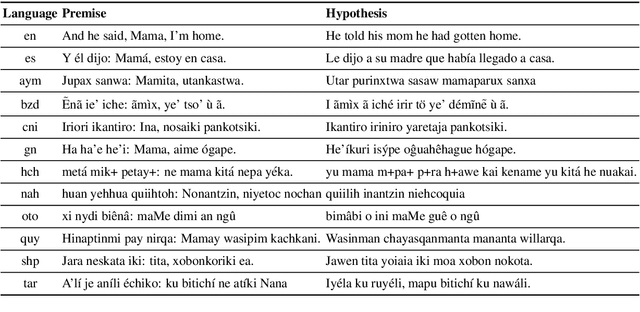

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.