 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
Domain Transfer for 3D Pose Estimation from Color Images without Manual Annotations
Oct 08, 2018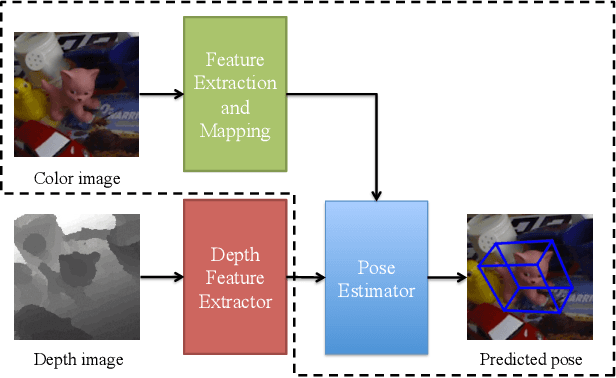

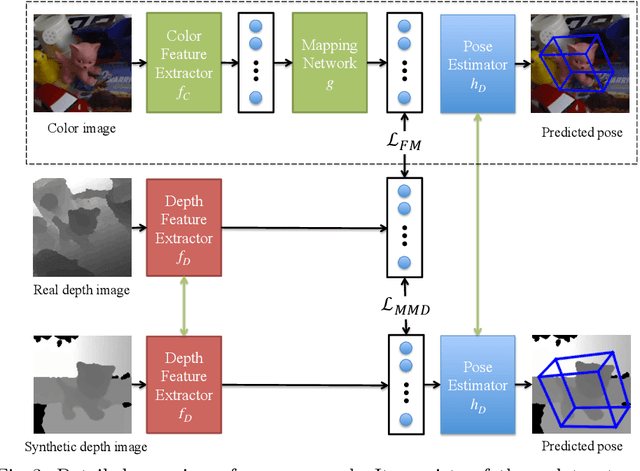
We introduce a novel learning method for 3D pose estimation from color images. While acquiring annotations for color images is a difficult task, our approach circumvents this problem by learning a mapping from paired color and depth images captured with an RGB-D camera. We jointly learn the pose from synthetic depth images that are easy to generate, and learn to align these synthetic depth images with the real depth images. We show our approach for the task of 3D hand pose estimation and 3D object pose estimation, both from color images only. Our method achieves performances comparable to state-of-the-art methods on popular benchmark datasets, without requiring any annotations for the color images.
Geometry-Aware Network for Non-Rigid Shape Prediction from a Single View
Sep 27, 2018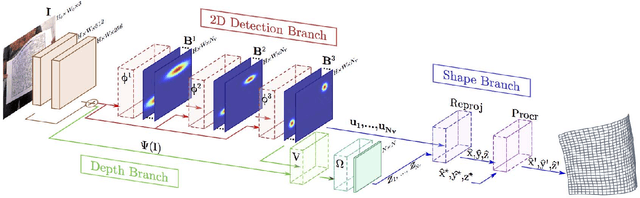
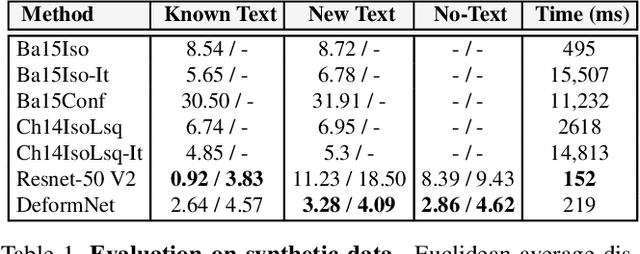


We propose a method for predicting the 3D shape of a deformable surface from a single view. By contrast with previous approaches, we do not need a pre-registered template of the surface, and our method is robust to the lack of texture and partial occlusions. At the core of our approach is a {\it geometry-aware} deep architecture that tackles the problem as usually done in analytic solutions: first perform 2D detection of the mesh and then estimate a 3D shape that is geometrically consistent with the image. We train this architecture in an end-to-end manner using a large dataset of synthetic renderings of shapes under different levels of deformation, material properties, textures and lighting conditions. We evaluate our approach on a test split of this dataset and available real benchmarks, consistently improving state-of-the-art solutions with a significantly lower computational time.
HandSeg: An Automatically Labeled Dataset for Hand Segmentation from Depth Images
Aug 02, 2018
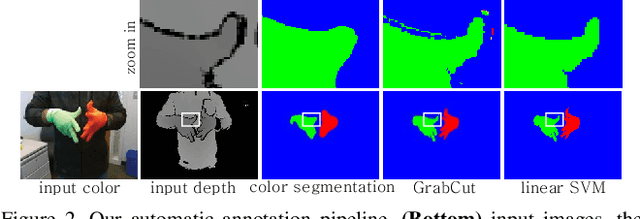
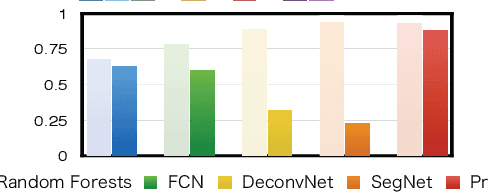
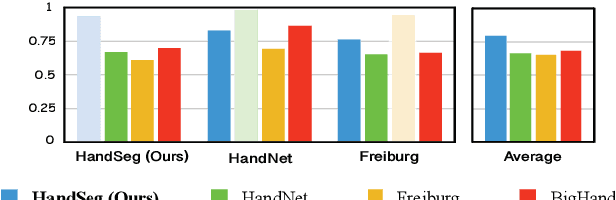
We propose an automatic method for generating high-quality annotations for depth-based hand segmentation, and introduce a large-scale hand segmentation dataset. Existing datasets are typically limited to a single hand. By exploiting the visual cues given by an RGBD sensor and a pair of colored gloves, we automatically generate dense annotations for two hand segmentation. This lowers the cost/complexity of creating high quality datasets, and makes it easy to expand the dataset in the future. We further show that existing datasets, even with data augmentation, are not sufficient to train a hand segmentation algorithm that can distinguish two hands. Source and datasets will be made publicly available.
Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation
Jul 26, 2018

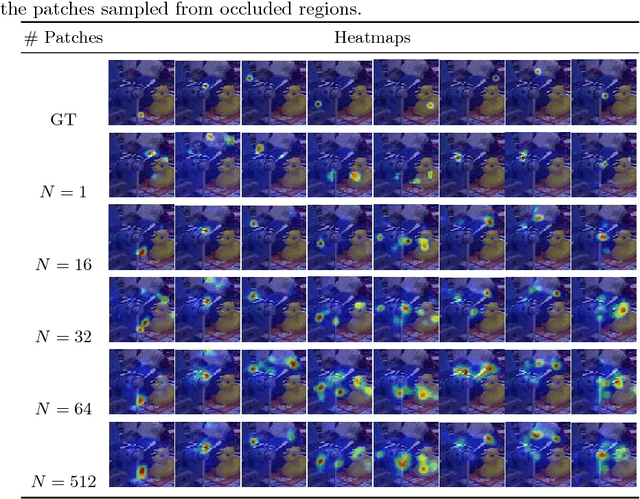

We introduce a novel method for robust and accurate 3D object pose estimation from a single color image under large occlusions. Following recent approaches, we first predict the 2D projections of 3D points related to the target object and then compute the 3D pose from these correspondences using a geometric method. Unfortunately, as the results of our experiments show, predicting these 2D projections using a regular CNN or a Convolutional Pose Machine is highly sensitive to partial occlusions, even when these methods are trained with partially occluded examples. Our solution is to predict heatmaps from multiple small patches independently and to accumulate the results to obtain accurate and robust predictions. Training subsequently becomes challenging because patches with similar appearances but different positions on the object correspond to different heatmaps. However, we provide a simple yet effective solution to deal with such ambiguities. We show that our approach outperforms existing methods on two challenging datasets: The Occluded LineMOD dataset and the YCB-Video dataset, both exhibiting cluttered scenes with highly occluded objects. Project website: https://www.tugraz.at/institute/icg/research/team-lepetit/research-projects/robust-object-pose-estimation/
Learning to Find Good Correspondences
May 21, 2018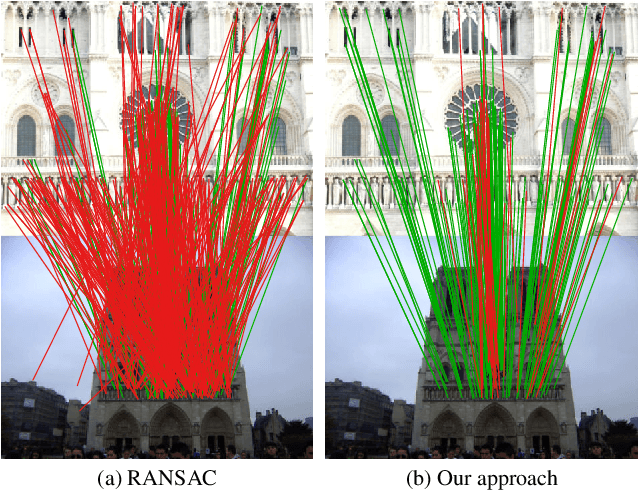
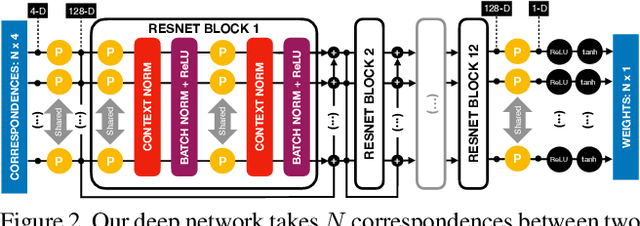

We develop a deep architecture to learn to find good correspondences for wide-baseline stereo. Given a set of putative sparse matches and the camera intrinsics, we train our network in an end-to-end fashion to label the correspondences as inliers or outliers, while simultaneously using them to recover the relative pose, as encoded by the essential matrix. Our architecture is based on a multi-layer perceptron operating on pixel coordinates rather than directly on the image, and is thus simple and small. We introduce a novel normalization technique, called Context Normalization, which allows us to process each data point separately while imbuing it with global information, and also makes the network invariant to the order of the correspondences. Our experiments on multiple challenging datasets demonstrate that our method is able to drastically improve the state of the art with little training data.
3D Pose Estimation and 3D Model Retrieval for Objects in the Wild
Mar 30, 2018

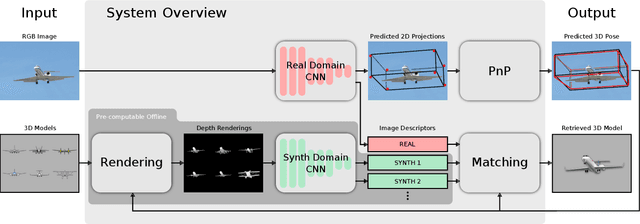
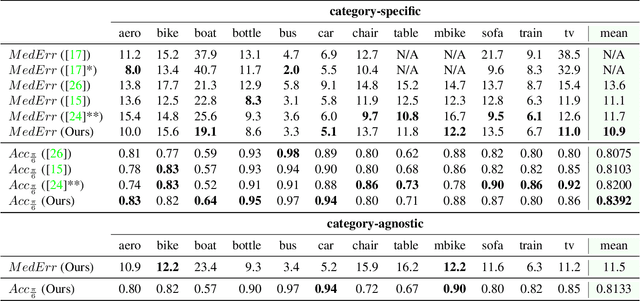
We propose a scalable, efficient and accurate approach to retrieve 3D models for objects in the wild. Our contribution is twofold. We first present a 3D pose estimation approach for object categories which significantly outperforms the state-of-the-art on Pascal3D+. Second, we use the estimated pose as a prior to retrieve 3D models which accurately represent the geometry of objects in RGB images. For this purpose, we render depth images from 3D models under our predicted pose and match learned image descriptors of RGB images against those of rendered depth images using a CNN-based multi-view metric learning approach. In this way, we are the first to report quantitative results for 3D model retrieval on Pascal3D+, where our method chooses the same models as human annotators for 50% of the validation images on average. In addition, we show that our method, which was trained purely on Pascal3D+, retrieves rich and accurate 3D models from ShapeNet given RGB images of objects in the wild.
* Accepted to Conference on Computer Vision and Pattern Recognition (CVPR) 2018
BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth
Mar 26, 2018
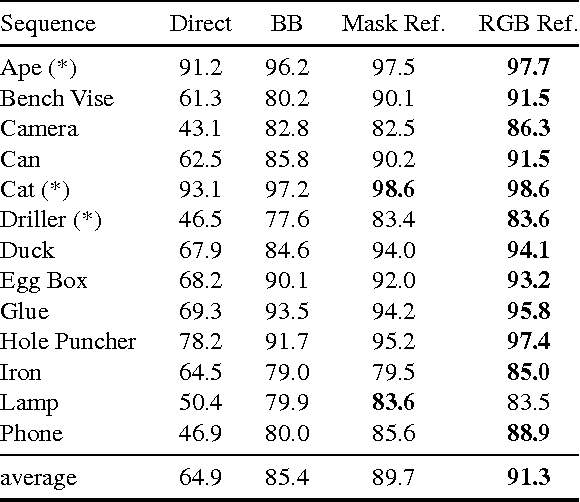

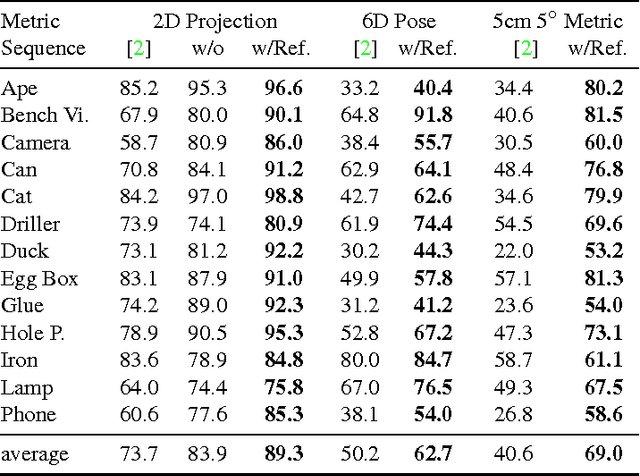
We introduce a novel method for 3D object detection and pose estimation from color images only. We first use segmentation to detect the objects of interest in 2D even in presence of partial occlusions and cluttered background. By contrast with recent patch-based methods, we rely on a "holistic" approach: We apply to the detected objects a Convolutional Neural Network (CNN) trained to predict their 3D poses in the form of 2D projections of the corners of their 3D bounding boxes. This, however, is not sufficient for handling objects from the recent T-LESS dataset: These objects exhibit an axis of rotational symmetry, and the similarity of two images of such an object under two different poses makes training the CNN challenging. We solve this problem by restricting the range of poses used for training, and by introducing a classifier to identify the range of a pose at run-time before estimating it. We also use an optional additional step that refines the predicted poses. We improve the state-of-the-art on the LINEMOD dataset from 73.7% to 89.3% of correctly registered RGB frames. We are also the first to report results on the Occlusion dataset using color images only. We obtain 54% of frames passing the Pose 6D criterion on average on several sequences of the T-LESS dataset, compared to the 67% of the state-of-the-art on the same sequences which uses both color and depth. The full approach is also scalable, as a single network can be trained for multiple objects simultaneously.
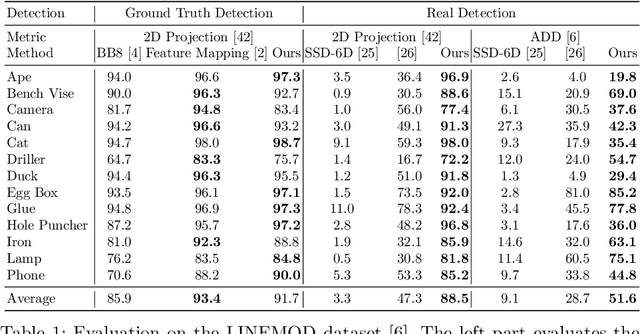
Feature Mapping for Learning Fast and Accurate 3D Pose Inference from Synthetic Images
Mar 26, 2018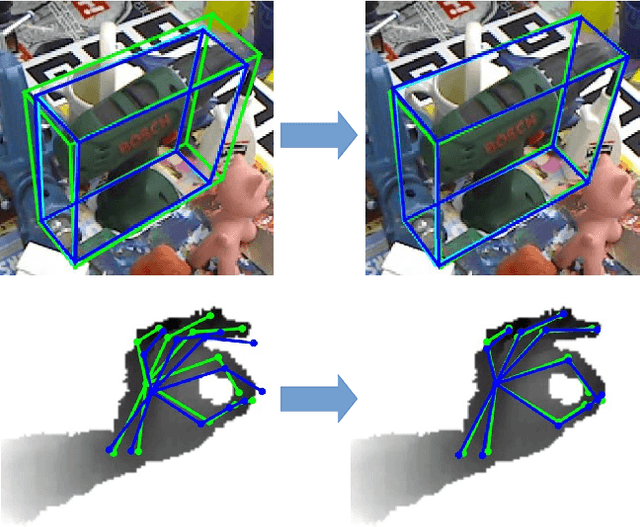
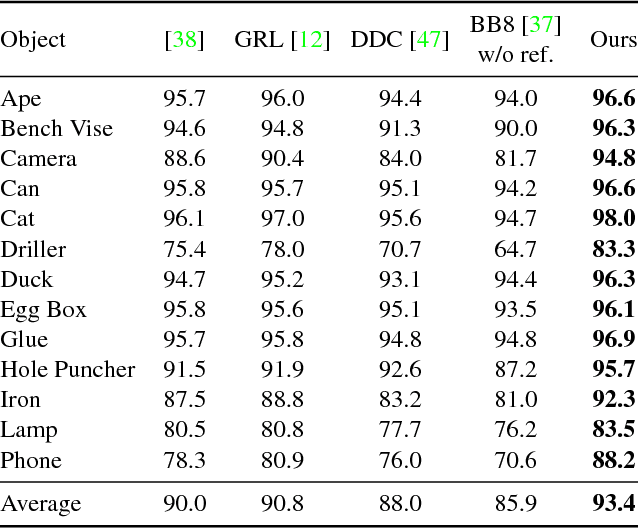
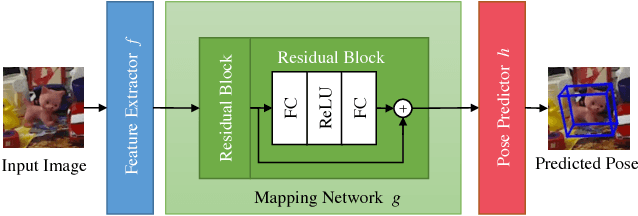
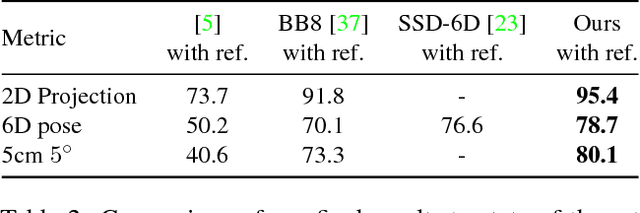
We propose a simple and efficient method for exploiting synthetic images when training a Deep Network to predict a 3D pose from an image. The ability of using synthetic images for training a Deep Network is extremely valuable as it is easy to create a virtually infinite training set made of such images, while capturing and annotating real images can be very cumbersome. However, synthetic images do not resemble real images exactly, and using them for training can result in suboptimal performance. It was recently shown that for exemplar-based approaches, it is possible to learn a mapping from the exemplar representations of real images to the exemplar representations of synthetic images. In this paper, we show that this approach is more general, and that a network can also be applied after the mapping to infer a 3D pose: At run time, given a real image of the target object, we first compute the features for the image, map them to the feature space of synthetic images, and finally use the resulting features as input to another network which predicts the 3D pose. Since this network can be trained very effectively by using synthetic images, it performs very well in practice, and inference is faster and more accurate than with an exemplar-based approach. We demonstrate our approach on the LINEMOD dataset for 3D object pose estimation from color images, and the NYU dataset for 3D hand pose estimation from depth maps. We show that it allows us to outperform the state-of-the-art on both datasets.
On Pre-Trained Image Features and Synthetic Images for Deep Learning
Nov 16, 2017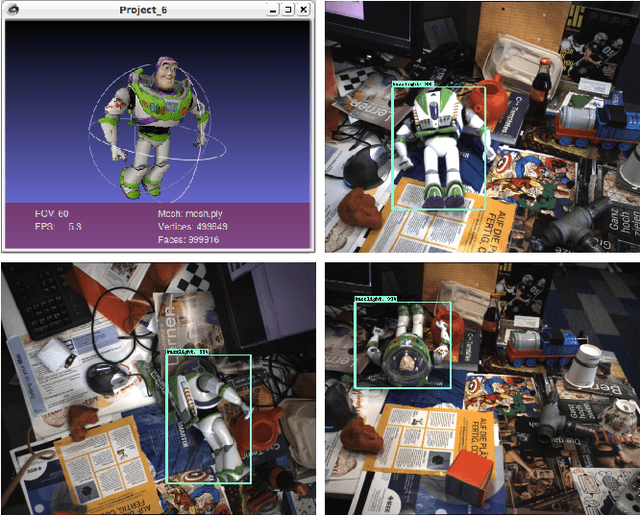
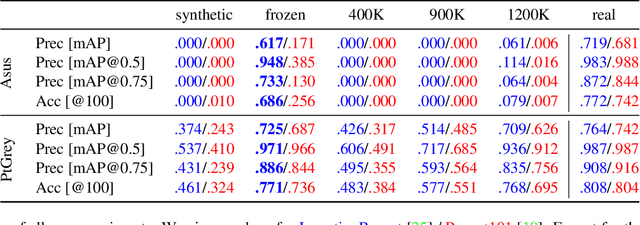
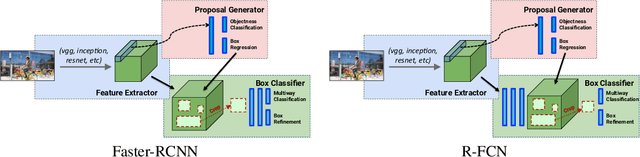
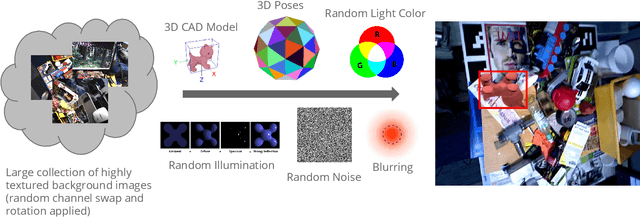
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling. Using synthetic images is therefore very attractive to train object detectors, as the labeling comes for free, and several approaches have been proposed to combine synthetic and real images for training. In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.