 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpan-Level Machine Translation Meta-Evaluation
Mar 20, 2026Machine Translation (MT) and automatic MT evaluation have improved dramatically in recent years, enabling numerous novel applications. Automatic evaluation techniques have evolved from producing scalar quality scores to precisely locating translation errors and assigning them error categories and severity levels. However, it remains unclear how to reliably measure the evaluation capabilities of auto-evaluators that do error detection, as no established technique exists in the literature. This work investigates different implementations of span-level precision, recall, and F-score, showing that seemingly similar approaches can yield substantially different rankings, and that certain widely-used techniques are unsuitable for evaluating MT error detection. We propose "match with partial overlap and partial credit" (MPP) with micro-averaging as a robust meta-evaluation strategy and release code for its use publicly. Finally, we use MPP to assess the state of the art in MT error detection.
Estimating Machine Translation Difficulty
Aug 13, 2025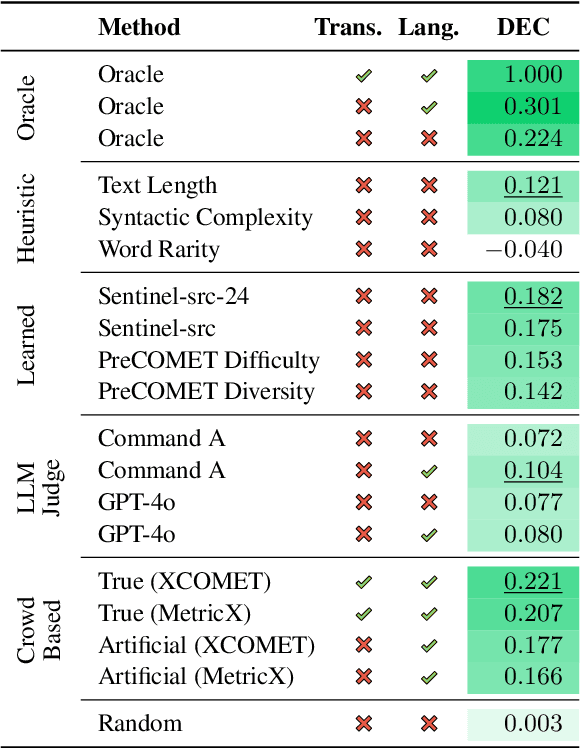
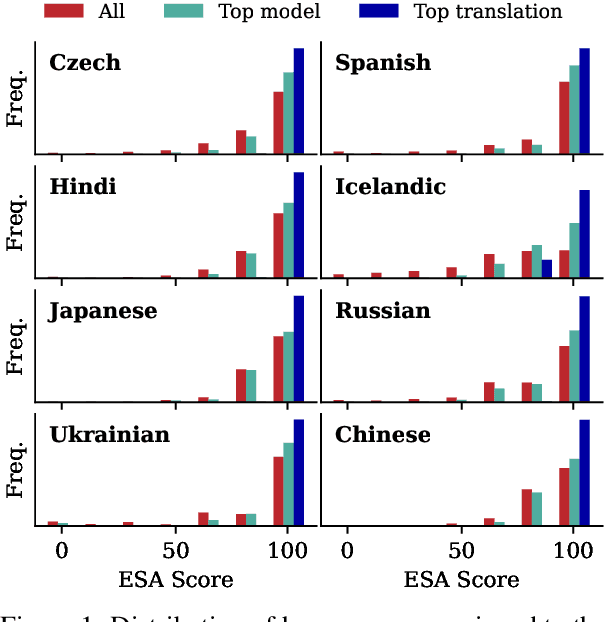
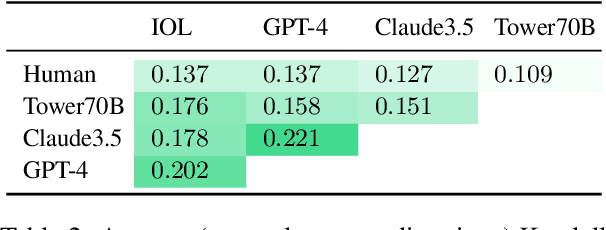
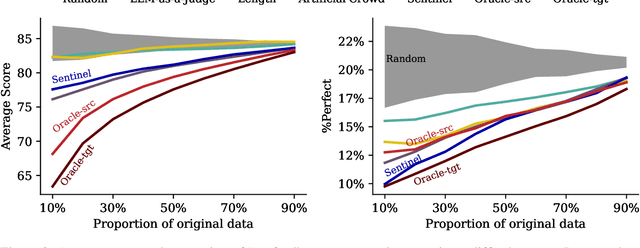
Machine translation quality has began achieving near-perfect translations in some setups. These high-quality outputs make it difficult to distinguish between state-of-the-art models and to identify areas for future improvement. Automatically identifying texts where machine translation systems struggle holds promise for developing more discriminative evaluations and guiding future research. We formalize the task of translation difficulty estimation, defining a text's difficulty based on the expected quality of its translations. We introduce a new metric to evaluate difficulty estimators and use it to assess both baselines and novel approaches. Finally, we demonstrate the practical utility of difficulty estimators by using them to construct more challenging machine translation benchmarks. Our results show that dedicated models (dubbed Sentinel-src) outperform both heuristic-based methods (e.g. word rarity or syntactic complexity) and LLM-as-a-judge approaches. We release two improved models for difficulty estimation, Sentinel-src-24 and Sentinel-src-25, which can be used to scan large collections of texts and select those most likely to challenge contemporary machine translation systems.
Has Machine Translation Evaluation Achieved Human Parity? The Human Reference and the Limits of Progress
Jun 24, 2025



In Machine Translation (MT) evaluation, metric performance is assessed based on agreement with human judgments. In recent years, automatic metrics have demonstrated increasingly high levels of agreement with humans. To gain a clearer understanding of metric performance and establish an upper bound, we incorporate human baselines in the MT meta-evaluation, that is, the assessment of MT metrics' capabilities. Our results show that human annotators are not consistently superior to automatic metrics, with state-of-the-art metrics often ranking on par with or higher than human baselines. Despite these findings suggesting human parity, we discuss several reasons for caution. Finally, we explore the broader implications of our results for the research field, asking: Can we still reliably measure improvements in MT evaluation? With this work, we aim to shed light on the limits of our ability to measure progress in the field, fostering discussion on an issue that we believe is crucial to the entire MT evaluation community.
Beyond Correlation: Interpretable Evaluation of Machine Translation Metrics
Oct 07, 2024



Machine Translation (MT) evaluation metrics assess translation quality automatically. Recently, researchers have employed MT metrics for various new use cases, such as data filtering and translation re-ranking. However, most MT metrics return assessments as scalar scores that are difficult to interpret, posing a challenge to making informed design choices. Moreover, MT metrics' capabilities have historically been evaluated using correlation with human judgment, which, despite its efficacy, falls short of providing intuitive insights into metric performance, especially in terms of new metric use cases. To address these issues, we introduce an interpretable evaluation framework for MT metrics. Within this framework, we evaluate metrics in two scenarios that serve as proxies for the data filtering and translation re-ranking use cases. Furthermore, by measuring the performance of MT metrics using Precision, Recall, and F-score, we offer clearer insights into their capabilities than correlation with human judgments. Finally, we raise concerns regarding the reliability of manually curated data following the Direct Assessments+Scalar Quality Metrics (DA+SQM) guidelines, reporting a notably low agreement with Multidimensional Quality Metrics (MQM) annotations.
Guardians of the Machine Translation Meta-Evaluation: Sentinel Metrics Fall In!
Aug 25, 2024



Annually, at the Conference of Machine Translation (WMT), the Metrics Shared Task organizers conduct the meta-evaluation of Machine Translation (MT) metrics, ranking them according to their correlation with human judgments. Their results guide researchers toward enhancing the next generation of metrics and MT systems. With the recent introduction of neural metrics, the field has witnessed notable advancements. Nevertheless, the inherent opacity of these metrics has posed substantial challenges to the meta-evaluation process. This work highlights two issues with the meta-evaluation framework currently employed in WMT, and assesses their impact on the metrics rankings. To do this, we introduce the concept of sentinel metrics, which are designed explicitly to scrutinize the meta-evaluation process's accuracy, robustness, and fairness. By employing sentinel metrics, we aim to validate our findings, and shed light on and monitor the potential biases or inconsistencies in the rankings. We discover that the present meta-evaluation framework favors two categories of metrics: i) those explicitly trained to mimic human quality assessments, and ii) continuous metrics. Finally, we raise concerns regarding the evaluation capabilities of state-of-the-art metrics, emphasizing that they might be basing their assessments on spurious correlations found in their training data.