 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Labelling of Speech Translation Errors
Jun 04, 2026Errors in speech translations reduce trustworthiness of Speech Translation (ST) systems and can have serious consequences. Yet currently there is no established methodology for evaluating confidence and quality estimation of speech translations. To initiate progress in this direction, we propose Speech Translation Error Labelling (STEL). We create an annotation protocol, a small authentic end-to-end evaluation dataset, and we analyse how existing text-only and speech-processing systems perform the STEL task. Our results show that text-only XCOMET and multimodal LLM Qwen2.5-Omni are able to perform the STEL task in roughly half the precision of humans. We also find that direct speech processing is necessary for the STEL task, and that the current text-only and speech-processing systems are complementary in labelling translation-only vs. speech-processing errors in ST.
Multilingual Long-Form Speech Instruction Following: KIT's Submission to IWSLT 2026
Jun 03, 2026With the advent of Large Language Models, single-task and token-based multi-task models have evolved into instruction-based systems that infer task and target language implicitly from natural language prompts. This trend is reflected in IWSLT's Instruction Following Track, which this year introduced new tasks including an unknown surprise task, posing a genuine challenge against overfitting to known tasks. We present KIT's submission to the Long and Short Instruction Following tracks in the unconstrained setting. Our approach combines a general data augmentation pipeline that converts short-form corpora into long-form training data through segment concatenation, LLM-based label generation, and cross-lingual translation, yielding over 1M instances across six tasks and four languages. We further show that likelihood-based re-ranking, while highly effective for ASR, systematically degrades semantic tasks by spuriously selecting candidates generated from segmented audio processing rather than holistic long-form inference, a failure mode resolved by combining likelihood with Minimum Bayes Risk decoding.
When Helpful Context Leaks: Privacy Risks in Domain-Adapted ASR
May 27, 2026SpeechLLMs are increasingly deployed in professional settings where domain customisation is standard practice: users supply context in prompts with sensitive information, fine-tune on proprietary recordings, or both. We identify and systematically investigate an overlooked privacy risk of such customisation: a model adapted to recognise domain-specific terminology can be nudged into transcribing a phonetically similar word from its context or training data, even when a different word is spoken, thereby leaking private information. To evaluate this risk, we construct a controlled dataset and measure leakage rates across two customisation mechanisms, prompting and fine-tuning. Both mechanisms cause measurable leakage, compounding when combined. We evaluate a prompt-level mitigation strategy and analyse the accuracy-leakage trade-off across customisation approaches, finding that fine-tuning without context prompts offers the best balance. We release our code and dataset publicly.
Why We Need Speech to Evaluate Speech Translation
May 27, 2026Speech translation models are increasingly capable of preserving speech-specific information (e.g., speaker gender, prosody, and emphasis), yet evaluation metrics remain blind to such phenomena. We meta-evaluate both text- and speech-based quality estimation metrics on two contrastive datasets targeting gender agreement and prosody, and find that both fall short, even when given direct access to the speech signal. We then train SpeechCOMET, a family of quality estimation models with speech encoders, and evaluate a state-of-the-art SpeechLLM as a judge. Both match or exceed text-based COMET on standard quality estimation, but neither consistently assesses speech-specific phenomena. We identify three causes: (1) speech-specific features are not reliably preserved in current encoders, (2) models tend to ignore the speech source signal, and (3) quality estimation training data contains too few relevant examples. We release all models and code, and argue that progress requires dedicated speech-specific training data and models that genuinely condition on speech.
Do What I Say: A Spoken Prompt Dataset for Instruction-Following
Mar 10, 2026Speech Large Language Models (SLLMs) have rapidly expanded, supporting a wide range of tasks. These models are typically evaluated using text prompts, which may not reflect real-world scenarios where users interact with speech. To address this gap, we introduce DoWhatISay (DOWIS), a multilingual dataset of human-recorded spoken and written prompts designed to pair with any existing benchmark for realistic evaluation of SLLMs under spoken instruction conditions. Spanning 9 tasks and 11 languages, it provides 10 prompt variants per task-language pair, across five styles. Using DOWIS, we benchmark state-of-the-art SLLMs, analyzing the interplay between prompt modality, style, language, and task type. Results show that text prompts consistently outperform spoken prompts, particularly for low-resource and cross-lingual settings. Only for tasks with speech output, spoken prompts do close the gap, highlighting the need for speech-based prompting in SLLM evaluation.
Beyond Transcripts: A Renewed Perspective on Audio Chaptering
Feb 09, 2026Audio chaptering, the task of automatically segmenting long-form audio into coherent sections, is increasingly important for navigating podcasts, lectures, and videos. Despite its relevance, research remains limited and text-based, leaving key questions unresolved about leveraging audio information, handling ASR errors, and transcript-free evaluation. We address these gaps through three contributions: (1) a systematic comparison between text-based models with acoustic features, a novel audio-only architecture (AudioSeg) operating on learned audio representations, and multimodal LLMs; (2) empirical analysis of factors affecting performance, including transcript quality, acoustic features, duration, and speaker composition; and (3) formalized evaluation protocols contrasting transcript-dependent text-space protocols with transcript-invariant time-space protocols. Our experiments on YTSeg reveal that AudioSeg substantially outperforms text-based approaches, pauses provide the largest acoustic gains, and MLLMs remain limited by context length and weak instruction following, yet MLLMs are promising on shorter audio.
F-Actor: Controllable Conversational Behaviour in Full-Duplex Models
Jan 16, 2026Spoken conversational systems require more than accurate speech generation to have human-like conversations: to feel natural and engaging, they must produce conversational behaviour that adapts dynamically to the context. Current spoken conversational systems, however, rarely allow such customization, limiting their naturalness and usability. In this work, we present the first open, instruction-following full-duplex conversational speech model that can be trained efficiently under typical academic resource constraints. By keeping the audio encoder frozen and finetuning only the language model, our model requires just 2,000 hours of data, without relying on large-scale pretraining or multi-stage optimization. The model can follow explicit instructions to control speaker voice, conversation topic, conversational behaviour (e.g., backchanneling and interruptions), and dialogue initiation. We propose a single-stage training protocol and systematically analyze design choices. Both the model and training code will be released to enable reproducible research on controllable full-duplex speech systems.
Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025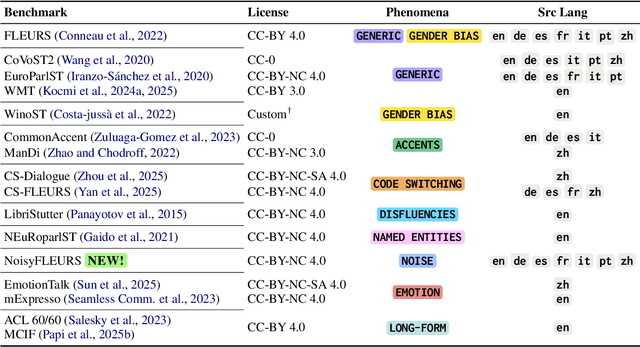
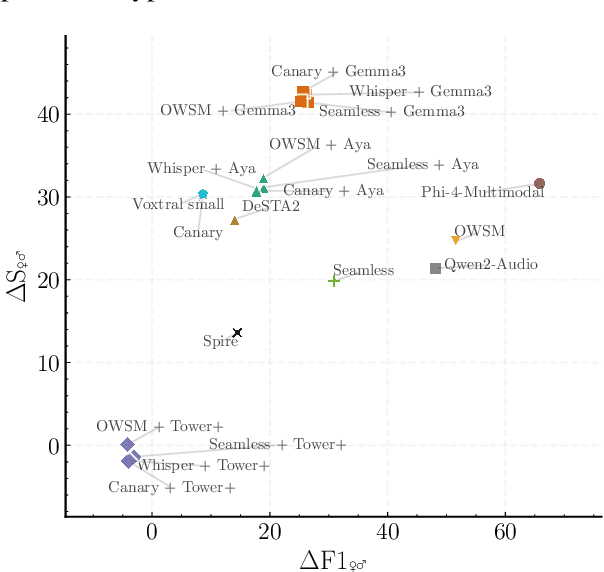
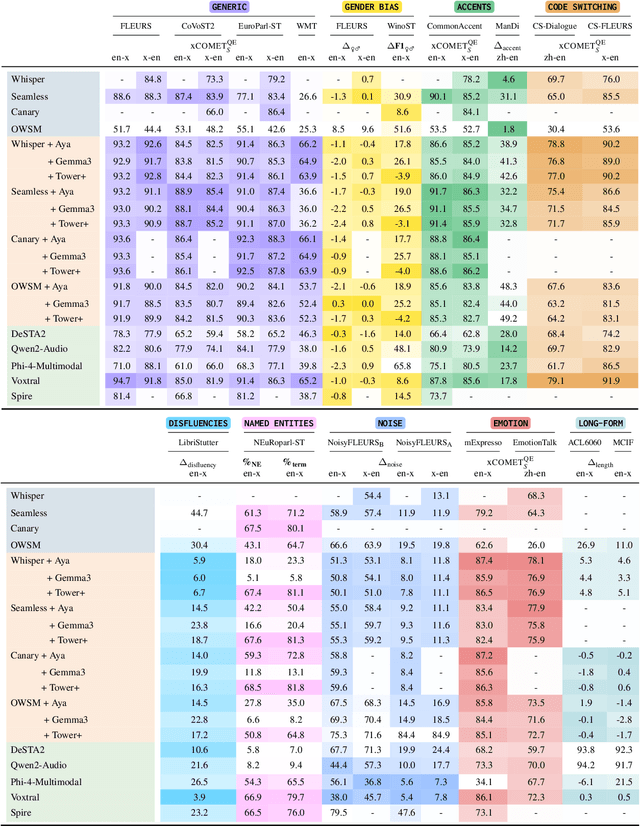
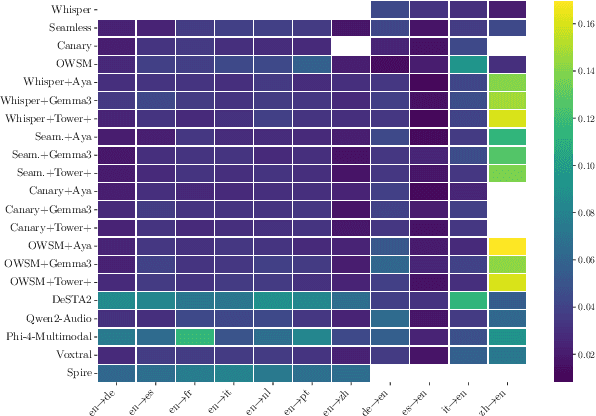
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
KIT's Offline Speech Translation and Instruction Following Submission for IWSLT 2025
May 19, 2025



The scope of the International Workshop on Spoken Language Translation (IWSLT) has recently broadened beyond traditional Speech Translation (ST) to encompass a wider array of tasks, including Speech Question Answering and Summarization. This shift is partly driven by the growing capabilities of modern systems, particularly with the success of Large Language Models (LLMs). In this paper, we present the Karlsruhe Institute of Technology's submissions for the Offline ST and Instruction Following (IF) tracks, where we leverage LLMs to enhance performance across all tasks. For the Offline ST track, we propose a pipeline that employs multiple automatic speech recognition systems, whose outputs are fused using an LLM with document-level context. This is followed by a two-step translation process, incorporating additional refinement step to improve translation quality. For the IF track, we develop an end-to-end model that integrates a speech encoder with an LLM to perform a wide range of instruction-following tasks. We complement it with a final document-level refinement stage to further enhance output quality by using contextual information.
From Speech to Summary: A Comprehensive Survey of Speech Summarization
Apr 10, 2025Speech summarization has become an essential tool for efficiently managing and accessing the growing volume of spoken and audiovisual content. However, despite its increasing importance, speech summarization is still not clearly defined and intersects with several research areas, including speech recognition, text summarization, and specific applications like meeting summarization. This survey not only examines existing datasets and evaluation methodologies, which are crucial for assessing the effectiveness of summarization approaches but also synthesizes recent developments in the field, highlighting the shift from traditional systems to advanced models like fine-tuned cascaded architectures and end-to-end solutions.