 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocKD: Knowledge Distillation from LLMs for Open-World Document Understanding Models
Oct 04, 2024



Visual document understanding (VDU) is a challenging task that involves understanding documents across various modalities (text and image) and layouts (forms, tables, etc.). This study aims to enhance generalizability of small VDU models by distilling knowledge from LLMs. We identify that directly prompting LLMs often fails to generate informative and useful data. In response, we present a new framework (called DocKD) that enriches the data generation process by integrating external document knowledge. Specifically, we provide an LLM with various document elements like key-value pairs, layouts, and descriptions, to elicit open-ended answers. Our experiments show that DocKD produces high-quality document annotations and surpasses the direct knowledge distillation approach that does not leverage external document knowledge. Moreover, student VDU models trained with solely DocKD-generated data are not only comparable to those trained with human-annotated data on in-domain tasks but also significantly excel them on out-of-domain tasks.
Enhancing Vision-Language Pre-training with Rich Supervisions
Mar 05, 2024



We propose Strongly Supervised pre-training with ScreenShots (S4) - a novel pre-training paradigm for Vision-Language Models using data from large-scale web screenshot rendering. Using web screenshots unlocks a treasure trove of visual and textual cues that are not present in using image-text pairs. In S4, we leverage the inherent tree-structured hierarchy of HTML elements and the spatial localization to carefully design 10 pre-training tasks with large scale annotated data. These tasks resemble downstream tasks across different domains and the annotations are cheap to obtain. We demonstrate that, compared to current screenshot pre-training objectives, our innovative pre-training method significantly enhances performance of image-to-text model in nine varied and popular downstream tasks - up to 76.1% improvements on Table Detection, and at least 1% on Widget Captioning.
Multiple-Question Multiple-Answer Text-VQA
Nov 15, 2023



We present Multiple-Question Multiple-Answer (MQMA), a novel approach to do text-VQA in encoder-decoder transformer models. The text-VQA task requires a model to answer a question by understanding multi-modal content: text (typically from OCR) and an associated image. To the best of our knowledge, almost all previous approaches for text-VQA process a single question and its associated content to predict a single answer. In order to answer multiple questions from the same image, each question and content are fed into the model multiple times. In contrast, our proposed MQMA approach takes multiple questions and content as input at the encoder and predicts multiple answers at the decoder in an auto-regressive manner at the same time. We make several novel architectural modifications to standard encoder-decoder transformers to support MQMA. We also propose a novel MQMA denoising pre-training task which is designed to teach the model to align and delineate multiple questions and content with associated answers. MQMA pre-trained model achieves state-of-the-art results on multiple text-VQA datasets, each with strong baselines. Specifically, on OCR-VQA (+2.5%), TextVQA (+1.4%), ST-VQA (+0.6%), DocVQA (+1.1%) absolute improvements over the previous state-of-the-art approaches.
DEED: Dynamic Early Exit on Decoder for Accelerating Encoder-Decoder Transformer Models
Nov 15, 2023Encoder-decoder transformer models have achieved great success on various vision-language (VL) tasks, but they suffer from high inference latency. Typically, the decoder takes up most of the latency because of the auto-regressive decoding. To accelerate the inference, we propose an approach of performing Dynamic Early Exit on Decoder (DEED). We build a multi-exit encoder-decoder transformer model which is trained with deep supervision so that each of its decoder layers is capable of generating plausible predictions. In addition, we leverage simple yet practical techniques, including shared generation head and adaptation modules, to keep accuracy when exiting at shallow decoder layers. Based on the multi-exit model, we perform step-level dynamic early exit during inference, where the model may decide to use fewer decoder layers based on its confidence of the current layer at each individual decoding step. Considering different number of decoder layers may be used at different decoding steps, we compute deeper-layer decoder features of previous decoding steps just-in-time, which ensures the features from different decoding steps are semantically aligned. We evaluate our approach with two state-of-the-art encoder-decoder transformer models on various VL tasks. We show our approach can reduce overall inference latency by 30%-60% with comparable or even higher accuracy compared to baselines.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation
Feb 14, 2023



In this work, instead of directly predicting the pixel-level segmentation masks, the problem of referring image segmentation is formulated as sequential polygon generation, and the predicted polygons can be later converted into segmentation masks. This is enabled by a new sequence-to-sequence framework, Polygon Transformer (PolyFormer), which takes a sequence of image patches and text query tokens as input, and outputs a sequence of polygon vertices autoregressively. For more accurate geometric localization, we propose a regression-based decoder, which predicts the precise floating-point coordinates directly, without any coordinate quantization error. In the experiments, PolyFormer outperforms the prior art by a clear margin, e.g., 5.40% and 4.52% absolute improvements on the challenging RefCOCO+ and RefCOCOg datasets. It also shows strong generalization ability when evaluated on the referring video segmentation task without fine-tuning, e.g., achieving competitive 61.5% J&F on the Ref-DAVIS17 dataset.
MATrIX -- Modality-Aware Transformer for Information eXtraction
May 17, 2022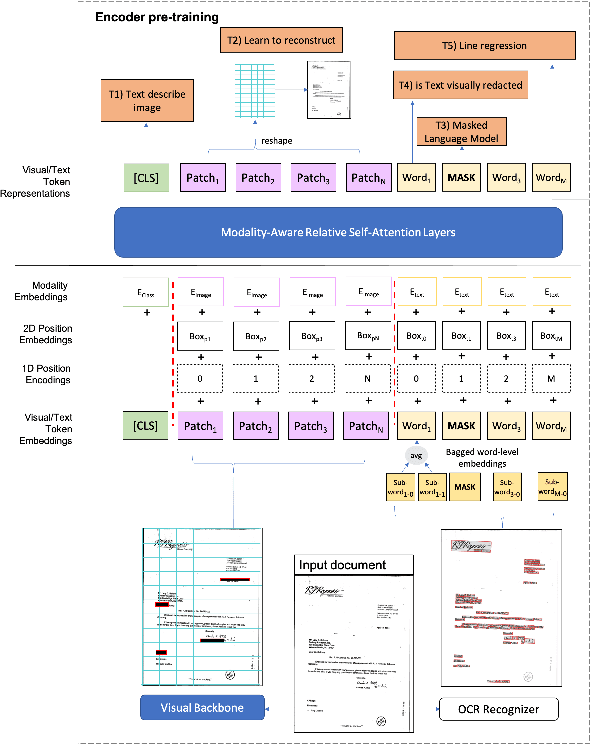
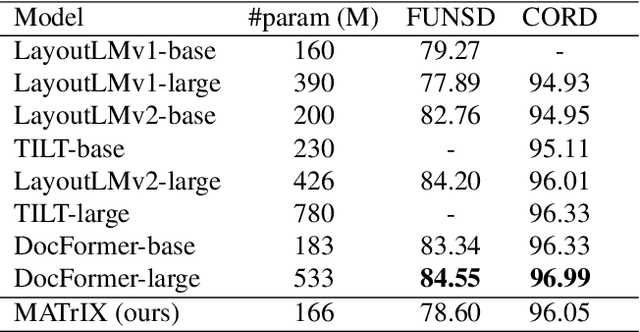

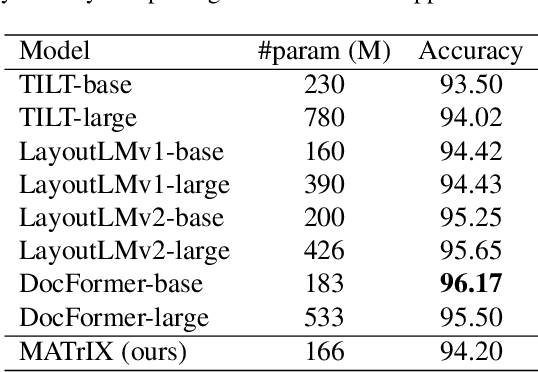
We present MATrIX - a Modality-Aware Transformer for Information eXtraction in the Visual Document Understanding (VDU) domain. VDU covers information extraction from visually rich documents such as forms, invoices, receipts, tables, graphs, presentations, or advertisements. In these, text semantics and visual information supplement each other to provide a global understanding of the document. MATrIX is pre-trained in an unsupervised way with specifically designed tasks that require the use of multi-modal information (spatial, visual, or textual). We consider the spatial and text modalities all at once in a single token set. To make the attention more flexible, we use a learned modality-aware relative bias in the attention mechanism to modulate the attention between the tokens of different modalities. We evaluate MATrIX on 3 different datasets each with strong baselines.
Towards Differential Relational Privacy and its use in Question Answering
Mar 30, 2022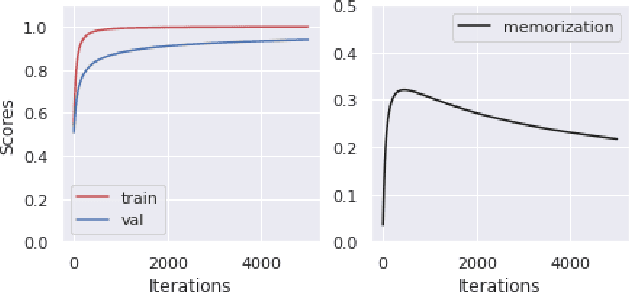

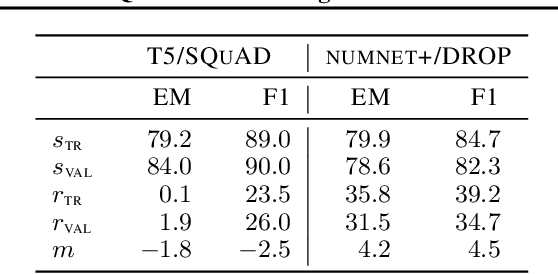
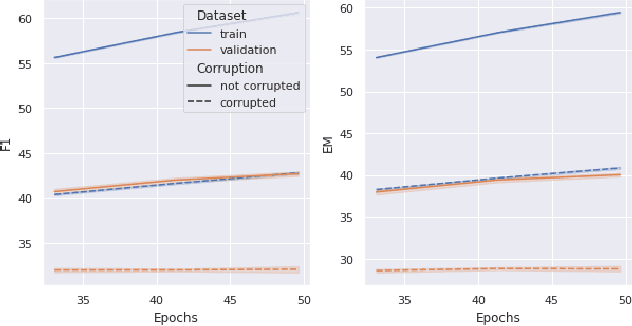
Memorization of the relation between entities in a dataset can lead to privacy issues when using a trained model for question answering. We introduce Relational Memorization (RM) to understand, quantify and control this phenomenon. While bounding general memorization can have detrimental effects on the performance of a trained model, bounding RM does not prevent effective learning. The difference is most pronounced when the data distribution is long-tailed, with many queries having only few training examples: Impeding general memorization prevents effective learning, while impeding only relational memorization still allows learning general properties of the underlying concepts. We formalize the notion of Relational Privacy (RP) and, inspired by Differential Privacy (DP), we provide a possible definition of Differential Relational Privacy (DrP). These notions can be used to describe and compute bounds on the amount of RM in a trained model. We illustrate Relational Privacy concepts in experiments with large-scale models for Question Answering.
Contrastive Neighborhood Alignment
Jan 06, 2022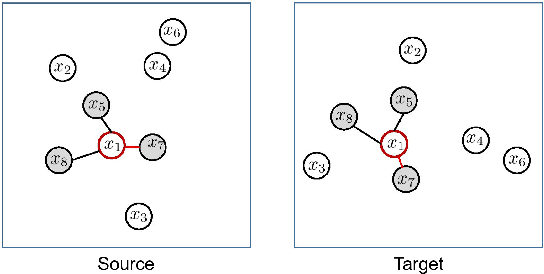
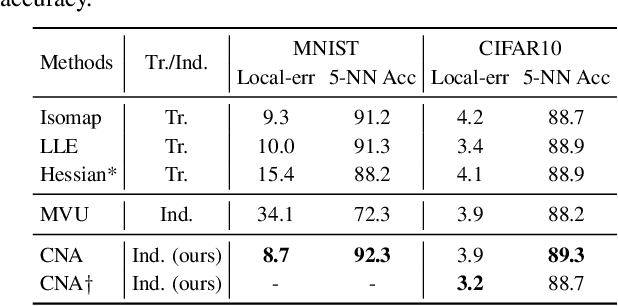
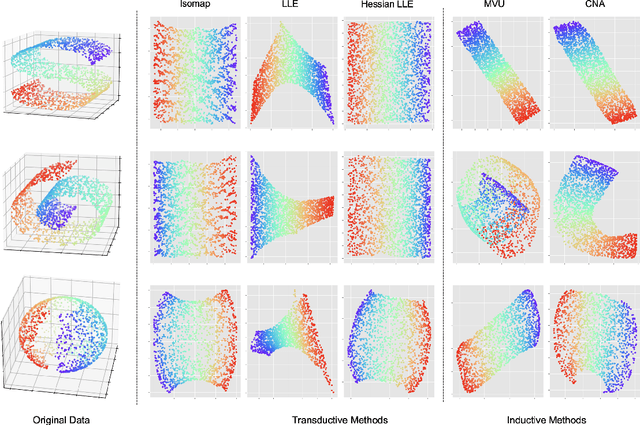
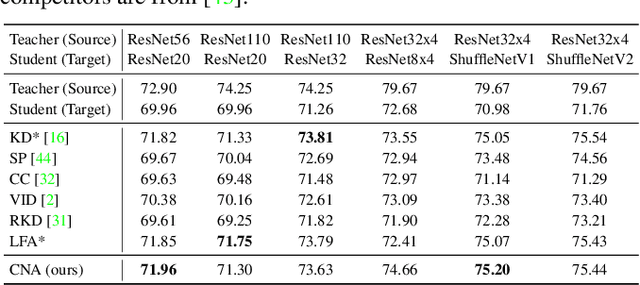
We present Contrastive Neighborhood Alignment (CNA), a manifold learning approach to maintain the topology of learned features whereby data points that are mapped to nearby representations by the source (teacher) model are also mapped to neighbors by the target (student) model. The target model aims to mimic the local structure of the source representation space using a contrastive loss. CNA is an unsupervised learning algorithm that does not require ground-truth labels for the individual samples. CNA is illustrated in three scenarios: manifold learning, where the model maintains the local topology of the original data in a dimension-reduced space; model distillation, where a small student model is trained to mimic a larger teacher; and legacy model update, where an older model is replaced by a more powerful one. Experiments show that CNA is able to capture the manifold in a high-dimensional space and improves performance compared to the competing methods in their domains.
Visual Composite Set Detection Using Part-and-Sum Transformers
May 05, 2021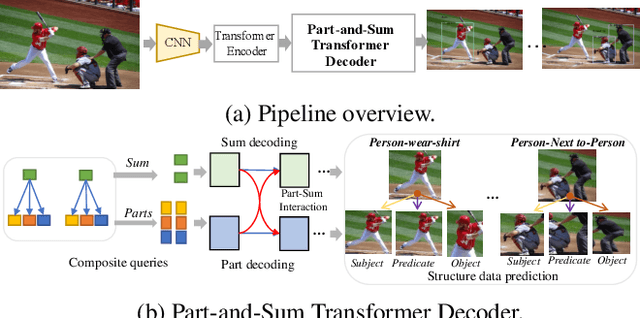

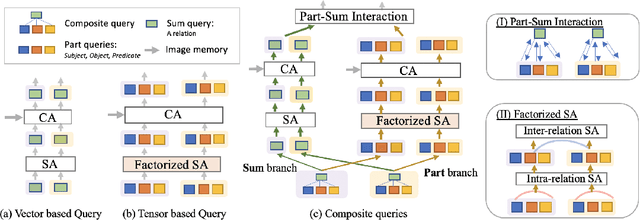

Computer vision applications such as visual relationship detection and human-object interaction can be formulated as a composite (structured) set detection problem in which both the parts (subject, object, and predicate) and the sum (triplet as a whole) are to be detected in a hierarchical fashion. In this paper, we present a new approach, denoted Part-and-Sum detection Transformer (PST), to perform end-to-end composite set detection. Different from existing Transformers in which queries are at a single level, we simultaneously model the joint part and sum hypotheses/interactions with composite queries and attention modules. We explicitly incorporate sum queries to enable better modeling of the part-and-sum relations that are absent in the standard Transformers. Our approach also uses novel tensor-based part queries and vector-based sum queries, and models their joint interaction. We report experiments on two vision tasks, visual relationship detection, and human-object interaction, and demonstrate that PST achieves state-of-the-art results among single-stage models, while nearly matching the results of custom-designed two-stage models.