 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards GUI Agents: Vision-Language Diffusion Models for GUI Grounding
Mar 27, 2026Autoregressive (AR) vision-language models (VLMs) have long dominated multimodal understanding, reasoning, and graphical user interface (GUI) grounding. Recently, discrete diffusion vision-language models (DVLMs) have shown strong performance in multimodal reasoning, offering bidirectional attention, parallel token generation, and iterative refinement. However, their potential for GUI grounding remains unexplored. In this work, we evaluate whether discrete DVLMs can serve as a viable alternative to AR models for GUI grounding. We adapt LLaDA-V for single-turn action and bounding-box prediction, framing the task as text generation from multimodal input. To better capture the hierarchical structure of bounding-box geometry, we propose a hybrid masking schedule that combines linear and deterministic masking, improving grounding accuracy by up to 6.1 points in Step Success Rate (SSR) over the GUI-adapted LLaDA-V trained with linear masking. Evaluations on four datasets spanning web, desktop, and mobile interfaces show that the adapted diffusion model with hybrid masking consistently outperforms the linear-masked variant and performs competitively with autoregressive counterparts despite limited pretraining. Systematic ablations reveal that increasing diffusion steps, generation length, and block length improves accuracy but also increases latency, with accuracy plateauing beyond a certain number of diffusion steps. Expanding the training data with diverse GUI domains further reduces latency by about 1.3 seconds and improves grounding accuracy by an average of 20 points across benchmarks. These results demonstrate that discrete DVLMs are a promising modeling framework for GUI grounding and represent an important step toward diffusion-based GUI agents.
Towards Differential Relational Privacy and its use in Question Answering
Mar 30, 2022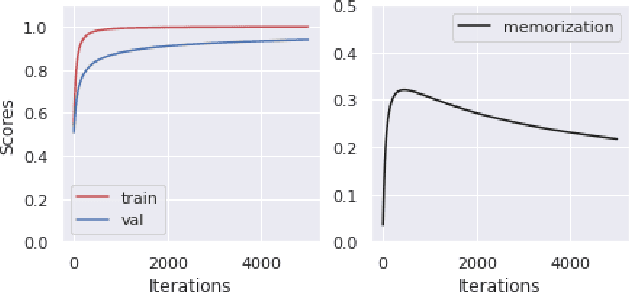

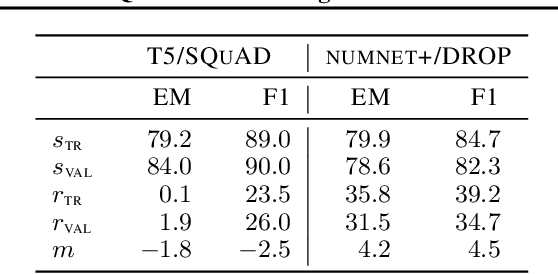
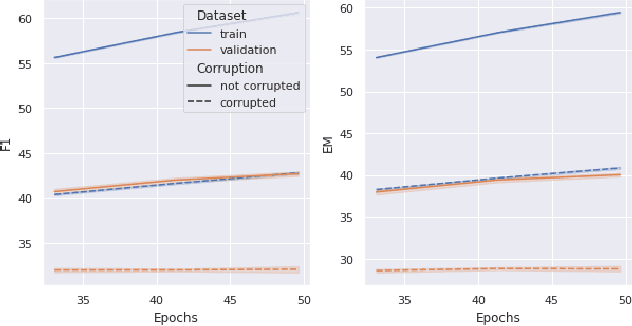
Memorization of the relation between entities in a dataset can lead to privacy issues when using a trained model for question answering. We introduce Relational Memorization (RM) to understand, quantify and control this phenomenon. While bounding general memorization can have detrimental effects on the performance of a trained model, bounding RM does not prevent effective learning. The difference is most pronounced when the data distribution is long-tailed, with many queries having only few training examples: Impeding general memorization prevents effective learning, while impeding only relational memorization still allows learning general properties of the underlying concepts. We formalize the notion of Relational Privacy (RP) and, inspired by Differential Privacy (DP), we provide a possible definition of Differential Relational Privacy (DrP). These notions can be used to describe and compute bounds on the amount of RM in a trained model. We illustrate Relational Privacy concepts in experiments with large-scale models for Question Answering.