 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocKD: Knowledge Distillation from LLMs for Open-World Document Understanding Models
Oct 04, 2024



Visual document understanding (VDU) is a challenging task that involves understanding documents across various modalities (text and image) and layouts (forms, tables, etc.). This study aims to enhance generalizability of small VDU models by distilling knowledge from LLMs. We identify that directly prompting LLMs often fails to generate informative and useful data. In response, we present a new framework (called DocKD) that enriches the data generation process by integrating external document knowledge. Specifically, we provide an LLM with various document elements like key-value pairs, layouts, and descriptions, to elicit open-ended answers. Our experiments show that DocKD produces high-quality document annotations and surpasses the direct knowledge distillation approach that does not leverage external document knowledge. Moreover, student VDU models trained with solely DocKD-generated data are not only comparable to those trained with human-annotated data on in-domain tasks but also significantly excel them on out-of-domain tasks.
RAVEN: Multitask Retrieval Augmented Vision-Language Learning
Jun 27, 2024



The scaling of large language models to encode all the world's knowledge in model parameters is unsustainable and has exacerbated resource barriers. Retrieval-Augmented Generation (RAG) presents a potential solution, yet its application to vision-language models (VLMs) is under explored. Existing methods focus on models designed for single tasks. Furthermore, they're limited by the need for resource intensive pre training, additional parameter requirements, unaddressed modality prioritization and lack of clear benefit over non-retrieval baselines. This paper introduces RAVEN, a multitask retrieval augmented VLM framework that enhances base VLMs through efficient, task specific fine-tuning. By integrating retrieval augmented samples without the need for additional retrieval-specific parameters, we show that the model acquires retrieval properties that are effective across multiple tasks. Our results and extensive ablations across retrieved modalities for the image captioning and VQA tasks indicate significant performance improvements compared to non retrieved baselines +1 CIDEr on MSCOCO, +4 CIDEr on NoCaps and nearly a +3\% accuracy on specific VQA question types. This underscores the efficacy of applying RAG approaches to VLMs, marking a stride toward more efficient and accessible multimodal learning.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation
Feb 14, 2023



In this work, instead of directly predicting the pixel-level segmentation masks, the problem of referring image segmentation is formulated as sequential polygon generation, and the predicted polygons can be later converted into segmentation masks. This is enabled by a new sequence-to-sequence framework, Polygon Transformer (PolyFormer), which takes a sequence of image patches and text query tokens as input, and outputs a sequence of polygon vertices autoregressively. For more accurate geometric localization, we propose a regression-based decoder, which predicts the precise floating-point coordinates directly, without any coordinate quantization error. In the experiments, PolyFormer outperforms the prior art by a clear margin, e.g., 5.40% and 4.52% absolute improvements on the challenging RefCOCO+ and RefCOCOg datasets. It also shows strong generalization ability when evaluated on the referring video segmentation task without fine-tuning, e.g., achieving competitive 61.5% J&F on the Ref-DAVIS17 dataset.
A Multimodal, Full-Surround Vehicular Testbed for Naturalistic Studies and Benchmarking: Design, Calibration and Deployment
Mar 20, 2018
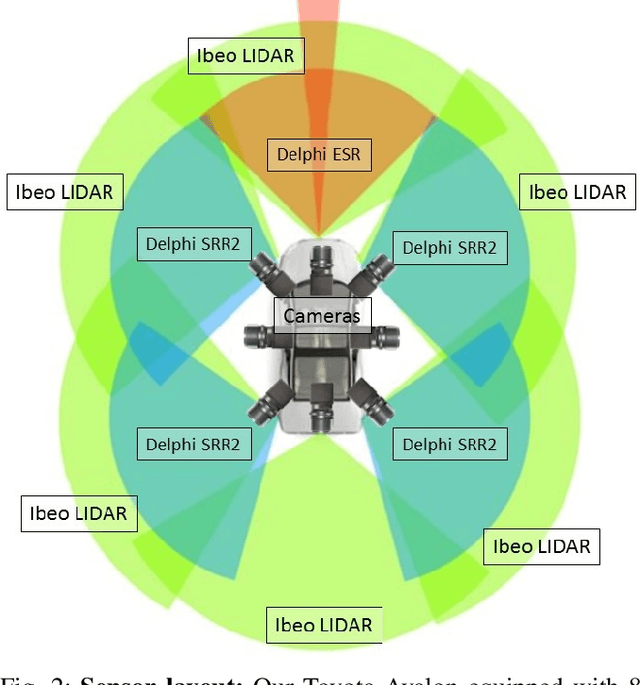

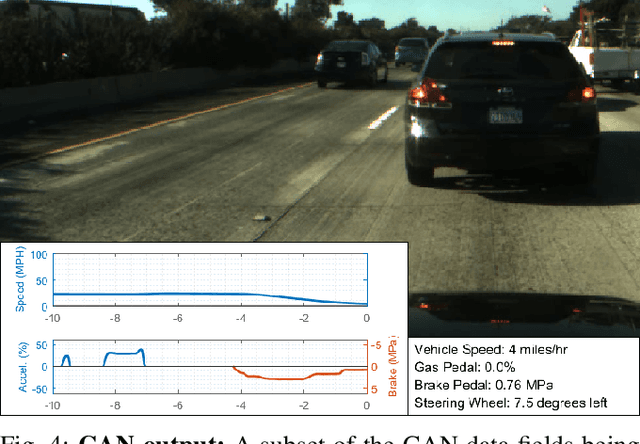
Recent progress in autonomous and semi-autonomous driving has been made possible in part through an assortment of sensors that provide the intelligent agent with an enhanced perception of its surroundings. It has been clear for quite some while now that for intelligent vehicles to function effectively in all situations and conditions, a fusion of different sensor technologies is essential. Consequently, the availability of synchronized multi-sensory data streams are necessary to promote the development of fusion based algorithms for low, mid and high level semantic tasks. In this paper, we provide a comprehensive description of LISA-A: our heavily sensorized, full-surround testbed capable of providing high quality data from a slew of synchronized and calibrated sensors such as cameras, LIDARs, radars, and the IMU/GPS. The vehicle has recorded over 100 hours of real world data for a very diverse set of weather, traffic and daylight conditions. All captured data is accurately calibrated and synchronized using timestamps, and stored safely in high performance servers mounted inside the vehicle itself. Details on the testbed instrumentation, sensor layout, sensor outputs, calibration and synchronization are described in this paper.