 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Deep Research Evaluation with Agentic Metrics
Feb 21, 2026Deep Research Agents generate analyst-grade reports, yet evaluating them remains challenging due to the absence of a single ground truth and the multidimensional nature of research quality. Recent benchmarks propose distinct methodologies, yet they suffer from the Mirage of Synthesis, where strong surface-level fluency and citation alignment can obscure underlying factual and reasoning defects. We characterize this gap by introducing a taxonomy across four verticals that exposes a critical capability mismatch: static evaluators inherently lack the tool-use capabilities required to assess temporal validity and factual correctness. To address this, we propose DREAM (Deep Research Evaluation with Agentic Metrics), a framework that instantiates the principle of capability parity by making evaluation itself agentic. DREAM structures assessment through an evaluation protocol combining query-agnostic metrics with adaptive metrics generated by a tool-calling agent, enabling temporally aware coverage, grounded verification, and systematic reasoning probes. Controlled evaluations demonstrate DREAM is significantly more sensitive to factual and temporal decay than existing benchmarks, offering a scalable, reference-free evaluation paradigm.
TAP-VL: Text Layout-Aware Pre-training for Enriched Vision-Language Models
Nov 07, 2024



Vision-Language (VL) models have garnered considerable research interest; however, they still face challenges in effectively handling text within images. To address this limitation, researchers have developed two approaches. The first method involves utilizing external Optical Character Recognition (OCR) tools to extract textual information from images, which is then prepended to other textual inputs. The second strategy focuses on employing extremely high-resolution images to improve text recognition capabilities. In this paper, we focus on enhancing the first strategy by introducing a novel method, named TAP-VL, which treats OCR information as a distinct modality and seamlessly integrates it into any VL model. TAP-VL employs a lightweight transformer-based OCR module to receive OCR with layout information, compressing it into a short fixed-length sequence for input into the LLM. Initially, we conduct model-agnostic pretraining of the OCR module on unlabeled documents, followed by its integration into any VL architecture through brief fine-tuning. Extensive experiments demonstrate consistent performance improvements when applying TAP-VL to top-performing VL models, across scene-text and document-based VL benchmarks.
Enhancing Vision-Language Pre-training with Rich Supervisions
Mar 05, 2024



We propose Strongly Supervised pre-training with ScreenShots (S4) - a novel pre-training paradigm for Vision-Language Models using data from large-scale web screenshot rendering. Using web screenshots unlocks a treasure trove of visual and textual cues that are not present in using image-text pairs. In S4, we leverage the inherent tree-structured hierarchy of HTML elements and the spatial localization to carefully design 10 pre-training tasks with large scale annotated data. These tasks resemble downstream tasks across different domains and the annotations are cheap to obtain. We demonstrate that, compared to current screenshot pre-training objectives, our innovative pre-training method significantly enhances performance of image-to-text model in nine varied and popular downstream tasks - up to 76.1% improvements on Table Detection, and at least 1% on Widget Captioning.
Question Aware Vision Transformer for Multimodal Reasoning
Feb 08, 2024



Vision-Language (VL) models have gained significant research focus, enabling remarkable advances in multimodal reasoning. These architectures typically comprise a vision encoder, a Large Language Model (LLM), and a projection module that aligns visual features with the LLM's representation space. Despite their success, a critical limitation persists: the vision encoding process remains decoupled from user queries, often in the form of image-related questions. Consequently, the resulting visual features may not be optimally attuned to the query-specific elements of the image. To address this, we introduce QA-ViT, a Question Aware Vision Transformer approach for multimodal reasoning, which embeds question awareness directly within the vision encoder. This integration results in dynamic visual features focusing on relevant image aspects to the posed question. QA-ViT is model-agnostic and can be incorporated efficiently into any VL architecture. Extensive experiments demonstrate the effectiveness of applying our method to various multimodal architectures, leading to consistent improvement across diverse tasks and showcasing its potential for enhancing visual and scene-text understanding.
Towards Models that Can See and Read
Jan 18, 2023



Visual Question Answering (VQA) and Image Captioning (CAP), which are among the most popular vision-language tasks, have analogous scene-text versions that require reasoning from the text in the image. Despite the obvious resemblance between them, the two are treated independently, yielding task-specific methods that can either see or read, but not both. In this work, we conduct an in-depth analysis of this phenomenon and propose UniTNT, a Unified Text-Non-Text approach, which grants existing multimodal architectures scene-text understanding capabilities. Specifically, we treat scene-text information as an additional modality, fusing it with any pretrained encoder-decoder-based architecture via designated modules. Thorough experiments reveal that UniTNT leads to the first single model that successfully handles both task types. Moreover, we show that scene-text understanding capabilities can boost vision-language models' performance on VQA and CAP by up to 3.49% and 0.7 CIDEr, respectively.
CLIPTER: Looking at the Bigger Picture in Scene Text Recognition
Jan 18, 2023



Understanding the scene is often essential for reading text in real-world scenarios. However, current scene text recognizers operate on cropped text images, unaware of the bigger picture. In this work, we harness the representative power of recent vision-language models, such as CLIP, to provide the crop-based recognizer with scene, image-level information. Specifically, we obtain a rich representation of the entire image and fuse it with the recognizer word-level features via cross-attention. Moreover, a gated mechanism is introduced that gradually shifts to the context-enriched representation, enabling simply fine-tuning a pretrained recognizer. We implement our model-agnostic framework, named CLIPTER - CLIP Text Recognition, on several leading text recognizers and demonstrate consistent performance gains, achieving state-of-the-art results over multiple benchmarks. Furthermore, an in-depth analysis reveals improved robustness to out-of-vocabulary words and enhanced generalization in low-data regimes.
Out-of-Vocabulary Challenge Report
Sep 14, 2022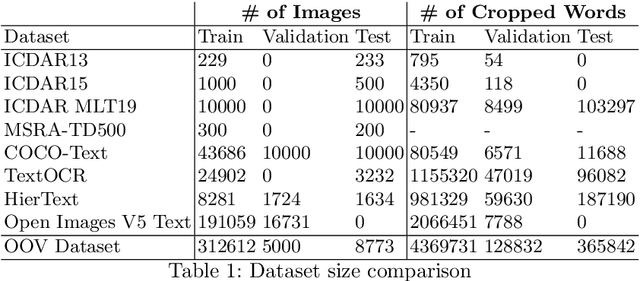
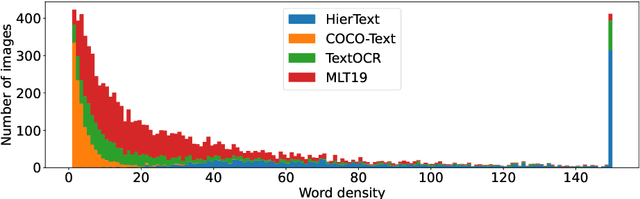

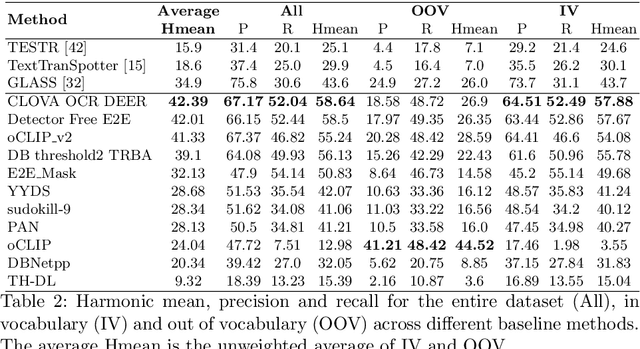
This paper presents final results of the Out-Of-Vocabulary 2022 (OOV) challenge. The OOV contest introduces an important aspect that is not commonly studied by Optical Character Recognition (OCR) models, namely, the recognition of unseen scene text instances at training time. The competition compiles a collection of public scene text datasets comprising of 326,385 images with 4,864,405 scene text instances, thus covering a wide range of data distributions. A new and independent validation and test set is formed with scene text instances that are out of vocabulary at training time. The competition was structured in two tasks, end-to-end and cropped scene text recognition respectively. A thorough analysis of results from baselines and different participants is presented. Interestingly, current state-of-the-art models show a significant performance gap under the newly studied setting. We conclude that the OOV dataset proposed in this challenge will be an essential area to be explored in order to develop scene text models that achieve more robust and generalized predictions.
TextAdaIN: Fine-Grained AdaIN for Robust Text Recognition
May 09, 2021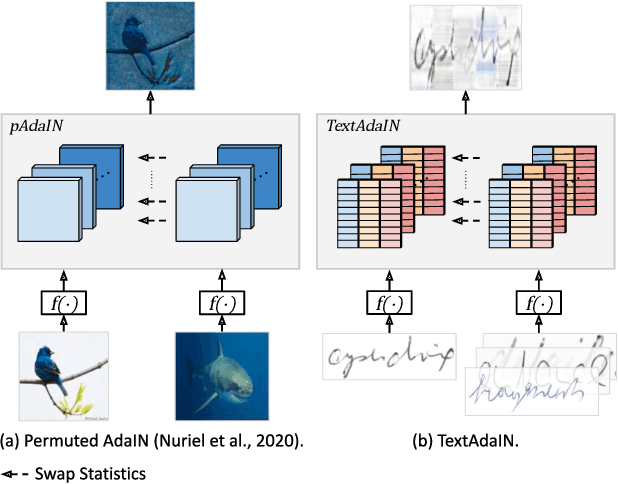
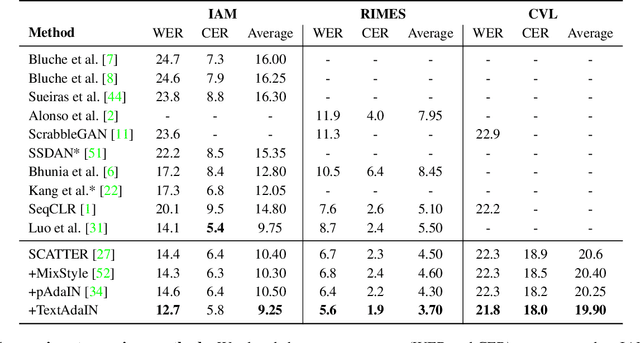

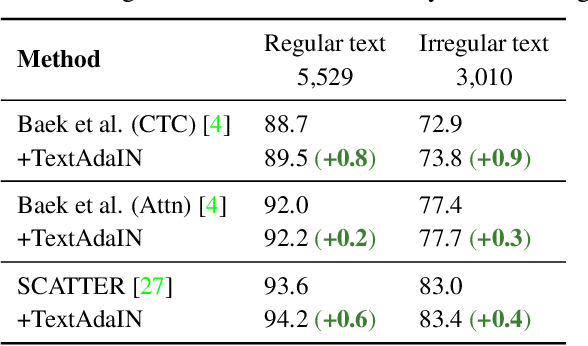
Leveraging the characteristics of convolutional layers, image classifiers are extremely effective. However, recent works have exposed that in many cases they immoderately rely on global image statistics that are easy to manipulate while preserving image semantics. In text recognition, we reveal that it is rather the local image statistics which the networks overly depend on. Motivated by this, we suggest an approach to regulate the reliance on local statistics that improves overall text recognition performance. Our method, termed TextAdaIN, creates local distortions in the feature map which prevent the network from overfitting to the local statistics. It does so by deliberately mismatching fine-grained feature statistics between samples in a mini-batch. Despite TextAdaIN's simplicity, extensive experiments show its effectiveness compared to other, more complicated methods. TextAdaIN achieves state-of-the-art results on standard handwritten text recognition benchmarks. Additionally, it generalizes to multiple architectures and to the domain of scene text recognition. Furthermore, we demonstrate that integrating TextAdaIN improves robustness towards image corruptions.
Permuted AdaIN: Enhancing the Representation of Local Cues in Image Classifiers
Oct 09, 2020
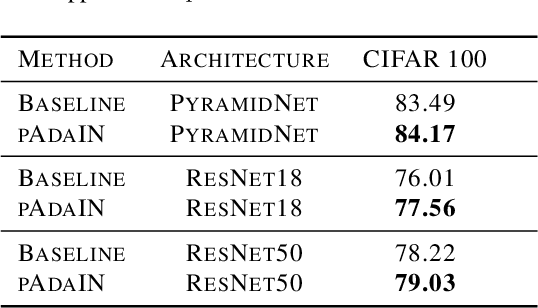
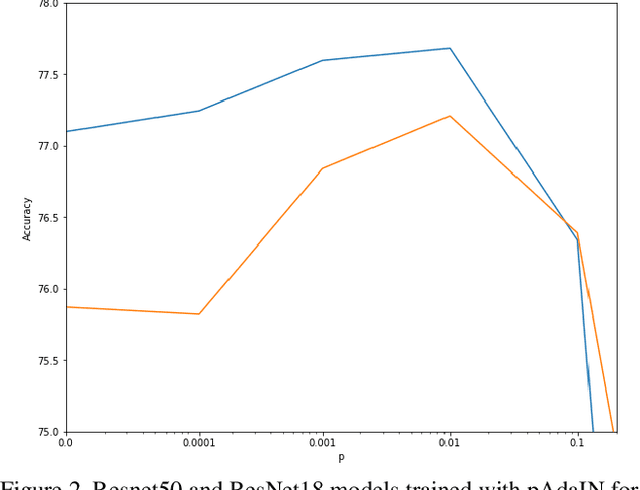
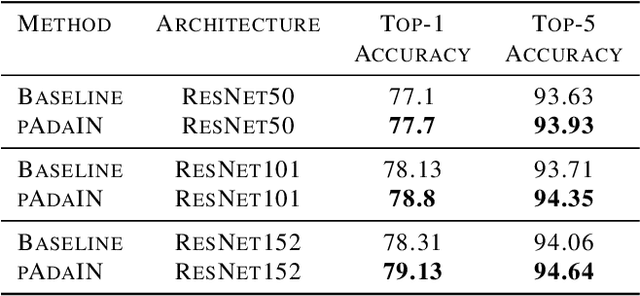
Recent work has shown that convolutional neural network classifiers overly rely on texture at the expense of shape cues, which adversely affects the classifier's performance in shifted domains. In this work, we make a similar but different distinction between local image cues, including shape and texture, and global image statistics. We provide a method that enhances the representation of local cues in the hidden layers of image classifiers. Our method, called Permuted Adaptive Instance Normalization (pAdaIN), samples a random permutation $\pi$ that rearranges the samples in a given batch. Adaptive Instance Normalization (AdaIN) is then applied between the activations of each (non-permuted) sample $i$ and the corresponding activations of the sample $\pi(i)$, thus swapping statistics between the samples of the batch. Since the global image statistics are distorted, this swapping procedure causes the network to rely on the local image cues. By choosing the random permutation with probability $p$ and the identity permutation otherwise, one can control the strength of this effect. With the correct choice of $p$, selected without considering the test data, our method consistently outperforms baseline methods in image classification, as well as in the setting of domain generalization.