 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSniffy Bug: A Fully Autonomous Swarm of Gas-Seeking Nano Quadcopters in Cluttered Environments
Jul 12, 2021


Nano quadcopters are ideal for gas source localization (GSL) as they are safe, agile and inexpensive. However, their extremely restricted sensors and computational resources make GSL a daunting challenge. In this work, we propose a novel bug algorithm named `Sniffy Bug', which allows a fully autonomous swarm of gas-seeking nano quadcopters to localize a gas source in an unknown, cluttered and GPS-denied environments. The computationally efficient, mapless algorithm foresees in the avoidance of obstacles and other swarm members, while pursuing desired waypoints. The waypoints are first set for exploration, and, when a single swarm member has sensed the gas, by a particle swarm optimization-based procedure. We evolve all the parameters of the bug (and PSO) algorithm, using our novel simulation pipeline, `AutoGDM'. It builds on and expands open source tools in order to enable fully automated end-to-end environment generation and gas dispersion modeling, allowing for learning in simulation. Flight tests show that Sniffy Bug with evolved parameters outperforms manually selected parameters in cluttered, real-world environments.
MLPerf Tiny Benchmark
Jun 28, 2021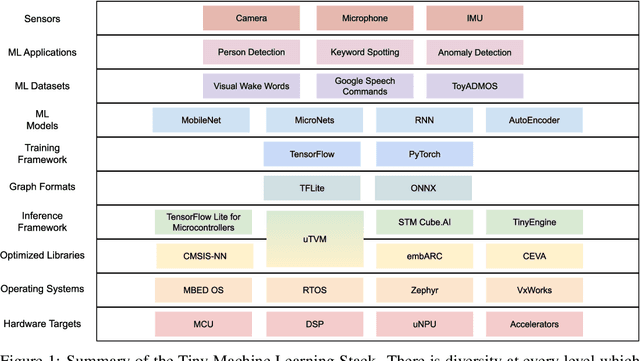
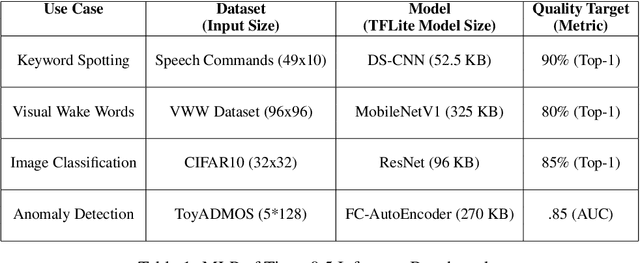
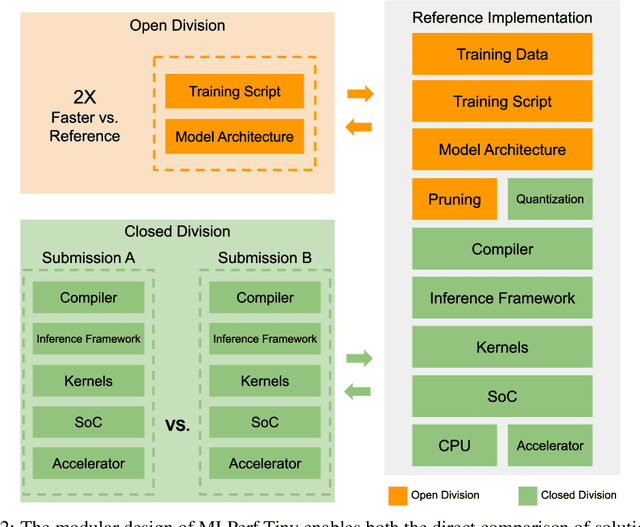
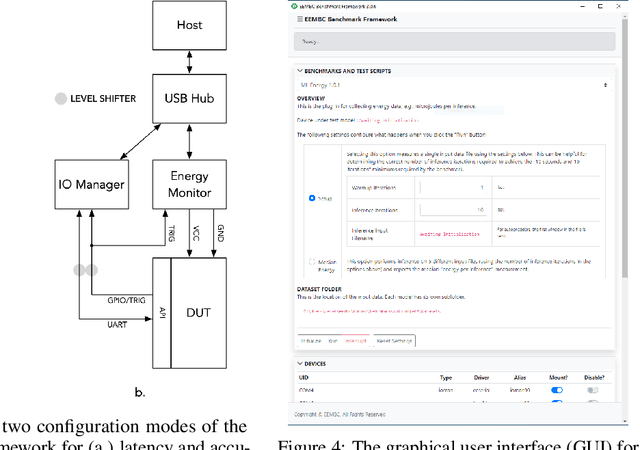
Advancements in ultra-low-power tiny machine learning (TinyML) systems promise to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted and easily reproducible benchmark for these systems. To meet this need, we present MLPerf Tiny, the first industry-standard benchmark suite for ultra-low-power tiny machine learning systems. The benchmark suite is the collaborative effort of more than 50 organizations from industry and academia and reflects the needs of the community. MLPerf Tiny measures the accuracy, latency, and energy of machine learning inference to properly evaluate the tradeoffs between systems. Additionally, MLPerf Tiny implements a modular design that enables benchmark submitters to show the benefits of their product, regardless of where it falls on the ML deployment stack, in a fair and reproducible manner. The suite features four benchmarks: keyword spotting, visual wake words, image classification, and anomaly detection.
Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix
Jun 10, 2021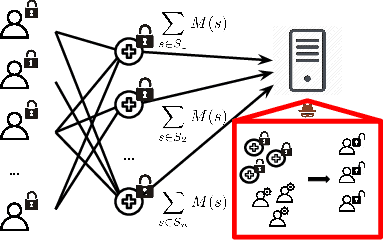
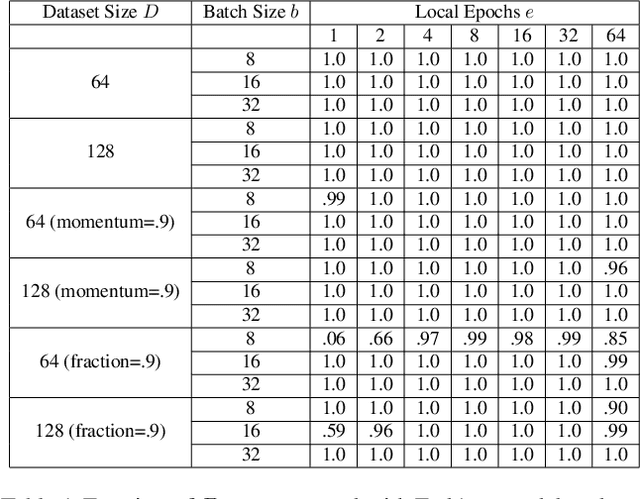
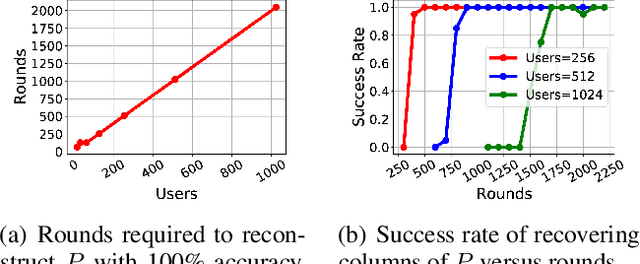

We show that aggregated model updates in federated learning may be insecure. An untrusted central server may disaggregate user updates from sums of updates across participants given repeated observations, enabling the server to recover privileged information about individual users' private training data via traditional gradient inference attacks. Our method revolves around reconstructing participant information (e.g: which rounds of training users participated in) from aggregated model updates by leveraging summary information from device analytics commonly used to monitor, debug, and manage federated learning systems. Our attack is parallelizable and we successfully disaggregate user updates on settings with up to thousands of participants. We quantitatively and qualitatively demonstrate significant improvements in the capability of various inference attacks on the disaggregated updates. Our attack enables the attribution of learned properties to individual users, violating anonymity, and shows that a determined central server may undermine the secure aggregation protocol to break individual users' data privacy in federated learning.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021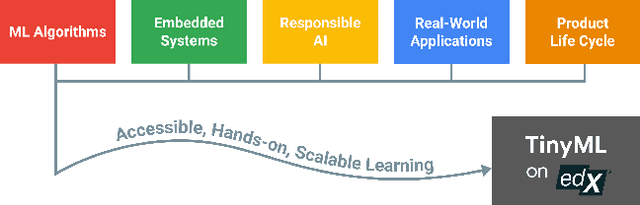
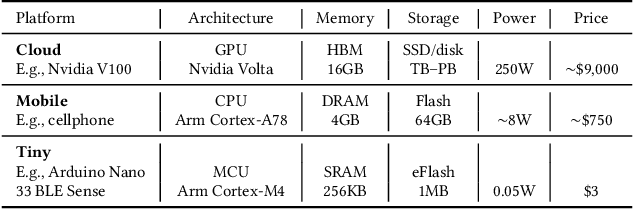

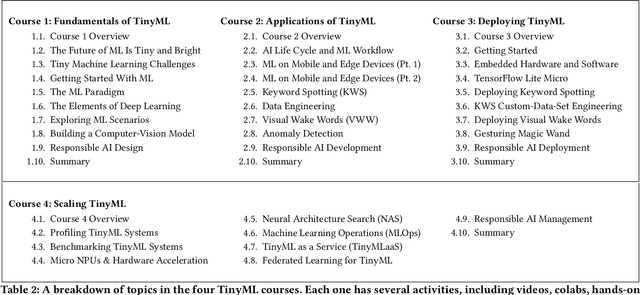
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
MAVFI: An End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles
May 27, 2021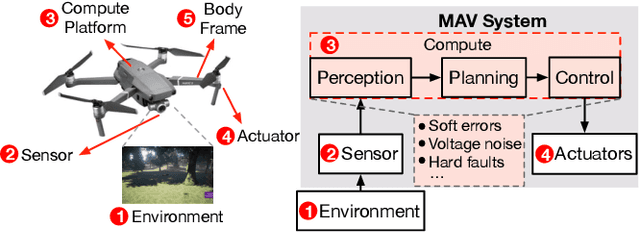

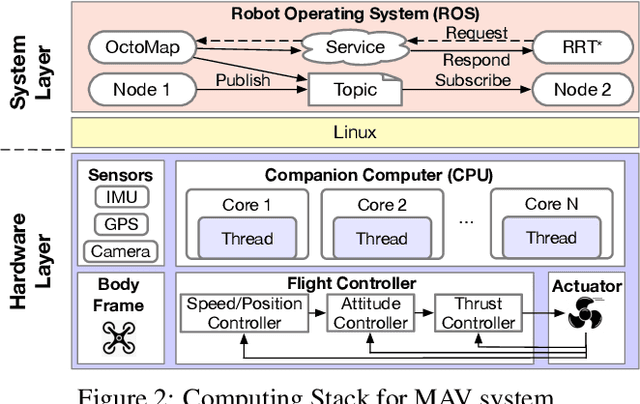
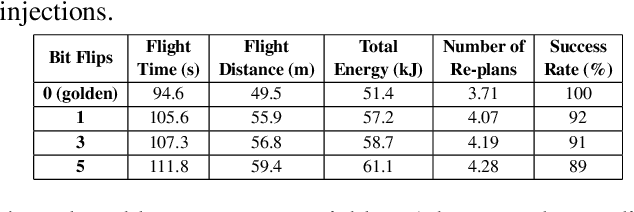
Reliability and safety are critical in autonomous machine services, such as autonomous vehicles and aerial drones. In this paper, we first present an open-source Micro Aerial Vehicles (MAVs) reliability analysis framework, MAVFI, to characterize transient fault's impacts on the end-to-end flight metrics, e.g., flight time, success rate. Based on our framework, it is observed that the end-to-end fault tolerance analysis is essential for characterizing system reliability. We demonstrate the planning and control stages are more vulnerable to transient faults than the visual perception stage in the common "Perception-Planning-Control (PPC)" compute pipeline. Furthermore, to improve the reliability of the MAV system, we propose two low overhead anomaly-based transient fault detection and recovery schemes based on Gaussian statistical models and autoencoder neural networks. We validate our anomaly fault protection schemes with a variety of simulated photo-realistic environments on both Intel i9 CPU and ARM Cortex-A57 on Nvidia TX2 platform. It is demonstrated that the autoencoder-based scheme can improve the system reliability by 100% recovering failure cases with less than 0.0062% computational overhead in best-case scenarios. In addition, MAVFI framework can be used for other ROS-based cyber-physical applications and is open-sourced at https://github.com/harvard-edge/MAVBench/tree/mavfi
Few-Shot Keyword Spotting in Any Language
Apr 22, 2021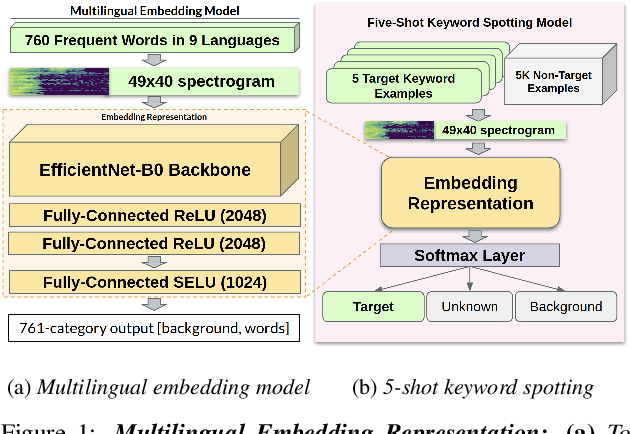
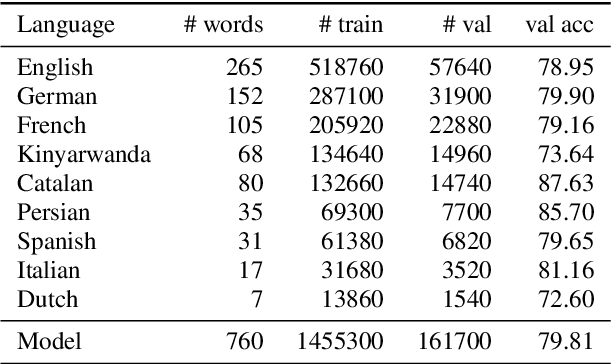
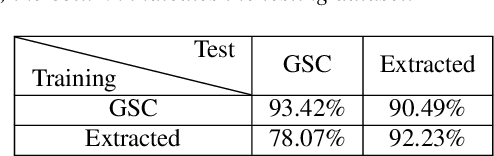
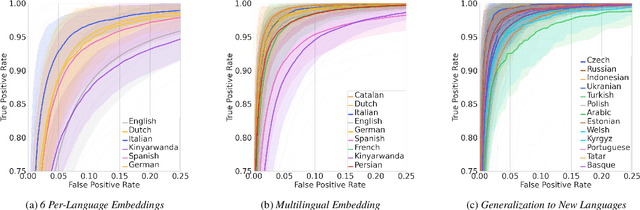
We introduce a few-shot transfer learning method for keyword spotting in any language. Leveraging open speech corpora in nine languages, we automate the extraction of a large multilingual keyword bank and use it to train an embedding model. With just five training examples, we fine-tune the embedding model for keyword spotting and achieve an average F1 score of 0.75 on keyword classification for 180 new keywords unseen by the embedding model in these nine languages. This embedding model also generalizes to new languages. We achieve an average F1 score of 0.65 on 5-shot models for 260 keywords sampled across 13 new languages unseen by the embedding model. We investigate streaming accuracy for our 5-shot models in two contexts: keyword spotting and keyword search. Across 440 keywords in 22 languages, we achieve an average streaming keyword spotting accuracy of 85.2% with a false acceptance rate of 1.2%, and observe promising initial results on keyword search.
RL-Scope: Cross-Stack Profiling for Deep Reinforcement Learning Workloads
Mar 04, 2021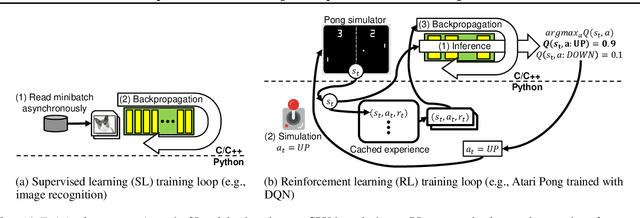


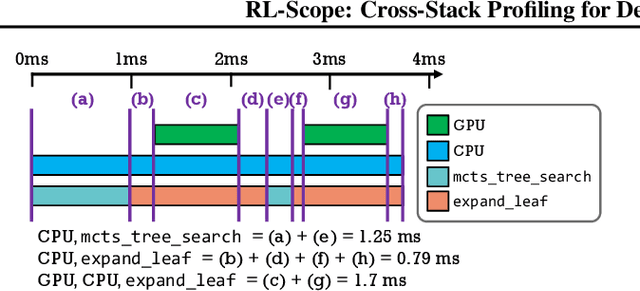
Deep reinforcement learning (RL) has made groundbreaking advancements in robotics, data center management and other applications. Unfortunately, system-level bottlenecks in RL workloads are poorly understood; we observe fundamental structural differences in RL workloads that make them inherently less GPU-bound than supervised learning (SL). To explain where training time is spent in RL workloads, we propose RL-Scope, a cross-stack profiler that scopes low-level CPU/GPU resource usage to high-level algorithmic operations, and provides accurate insights by correcting for profiling overhead. Using RL-Scope, we survey RL workloads across its major dimensions including ML backend, RL algorithm, and simulator. For ML backends, we explain a $2.3\times$ difference in runtime between equivalent PyTorch and TensorFlow algorithm implementations, and identify a bottleneck rooted in overly abstracted algorithm implementations. For RL algorithms and simulators, we show that on-policy algorithms are at least $3.5\times$ more simulation-bound than off-policy algorithms. Finally, we profile a scale-up workload and demonstrate that GPU utilization metrics reported by commonly used tools dramatically inflate GPU usage, whereas RL-Scope reports true GPU-bound time. RL-Scope is an open-source tool available at https://github.com/UofT-EcoSystem/rlscope .
Data Engineering for Everyone
Feb 23, 2021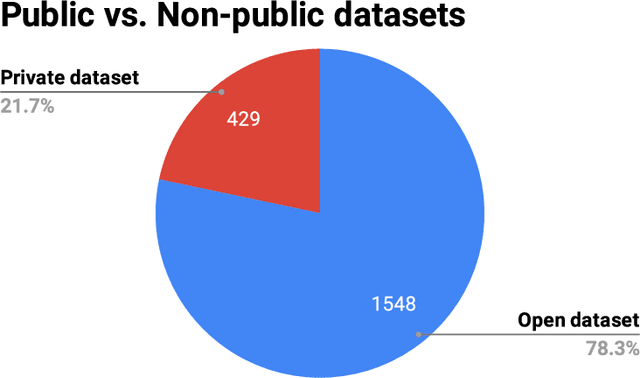
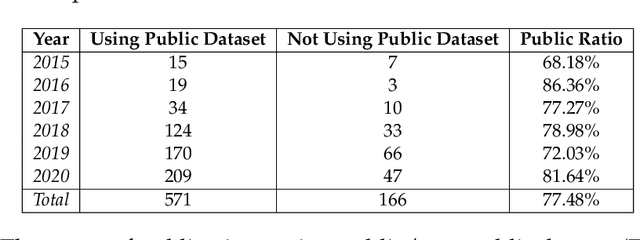
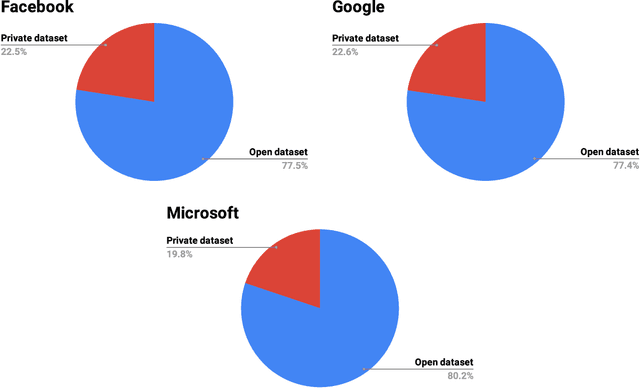
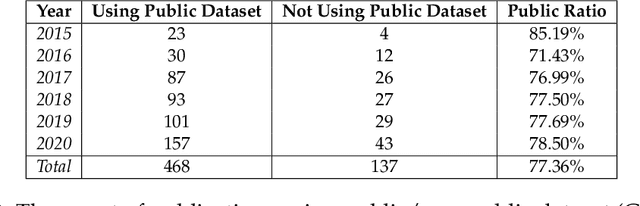
Data engineering is one of the fastest-growing fields within machine learning (ML). As ML becomes more common, the appetite for data grows more ravenous. But ML requires more data than individual teams of data engineers can readily produce, which presents a severe challenge to ML deployment at scale. Much like the software-engineering revolution, where mass adoption of open-source software replaced the closed, in-house development model for infrastructure code, there is a growing need to enable rapid development and open contribution to massive machine learning data sets. This article shows that open-source data sets are the rocket fuel for research and innovation at even some of the largest AI organizations. Our analysis of nearly 2000 research publications from Facebook, Google and Microsoft over the past five years shows the widespread use and adoption of open data sets. Open data sets that are easily accessible to the public are vital to accelerating ML innovation for everyone. But such open resources are scarce in the wild. So, what if we are able to accelerate data-set creation via automatic data set generation tools?
Machine Learning-Based Automated Design Space Exploration for Autonomous Aerial Robots
Feb 05, 2021
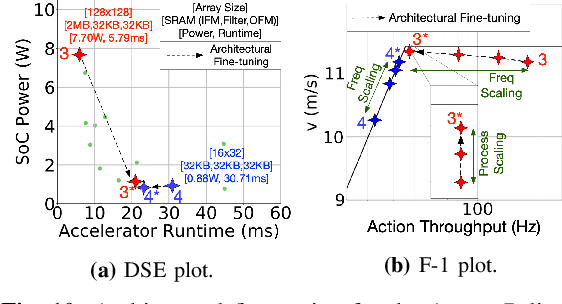
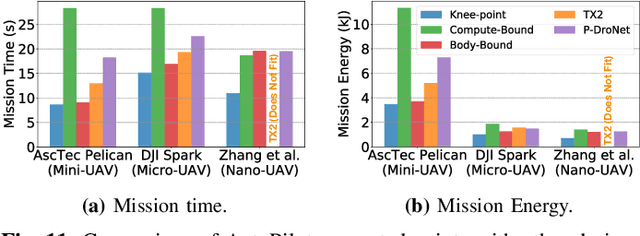

Building domain-specific architectures for autonomous aerial robots is challenging due to a lack of systematic methodology for designing onboard compute. We introduce a novel performance model called the F-1 roofline to help architects understand how to build a balanced computing system for autonomous aerial robots considering both its cyber (sensor rate, compute performance) and physical components (body-dynamics) that affect the performance of the machine. We use F-1 to characterize commonly used learning-based autonomy algorithms with onboard platforms to demonstrate the need for cyber-physical co-design. To navigate the cyber-physical design space automatically, we subsequently introduce AutoPilot. This push-button framework automates the co-design of cyber-physical components for aerial robots from a high-level specification guided by the F-1 model. AutoPilot uses Bayesian optimization to automatically co-design the autonomy algorithm and hardware accelerator while considering various cyber-physical parameters to generate an optimal design under different task level complexities for different robots and sensor framerates. As a result, designs generated by AutoPilot, on average, lower mission time up to 2x over baseline approaches, conserving battery energy.
MLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Dec 03, 2020

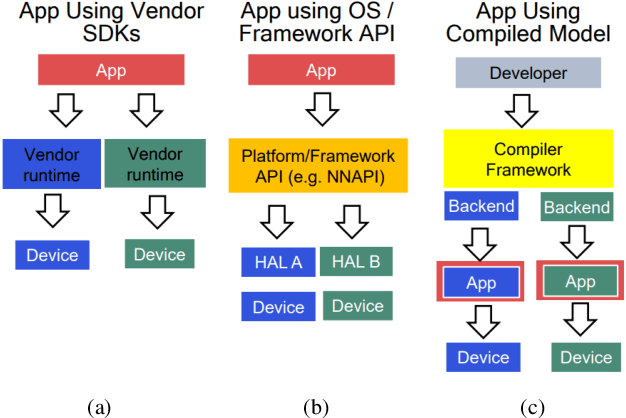
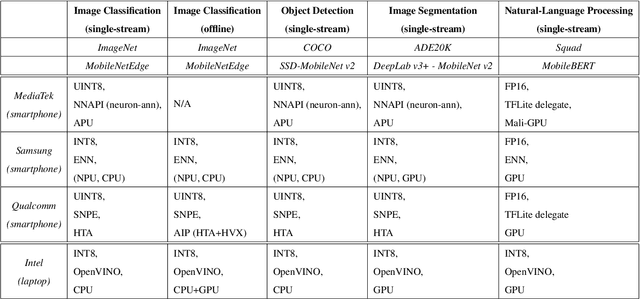
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.