 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Dec 03, 2020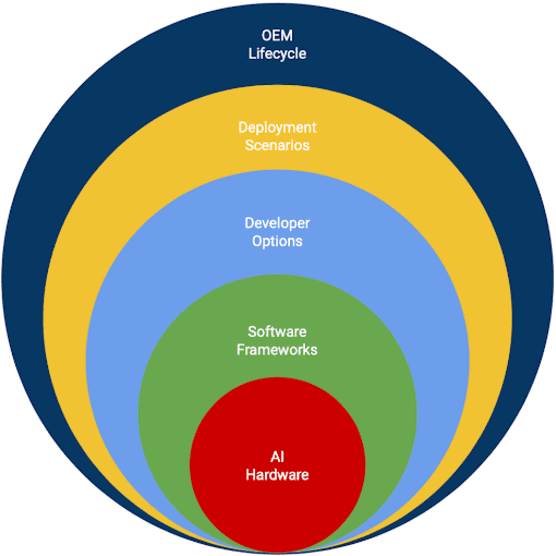

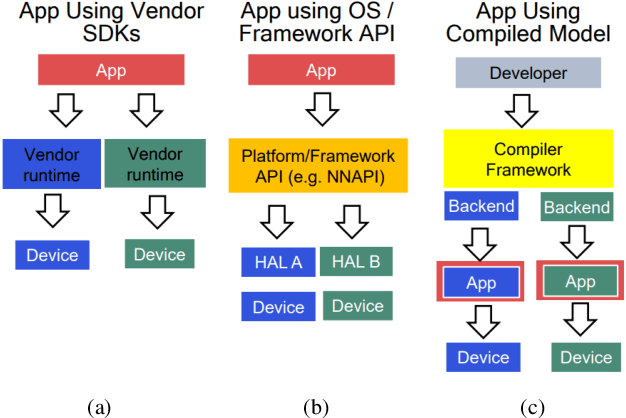
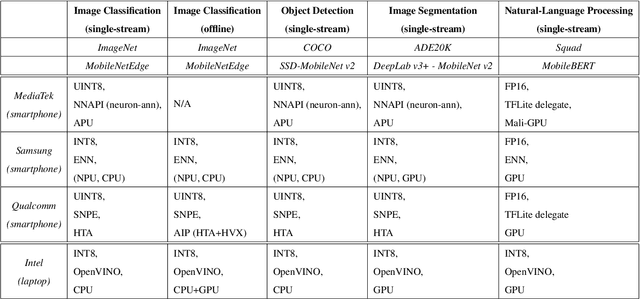
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.
TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems
Oct 20, 2020

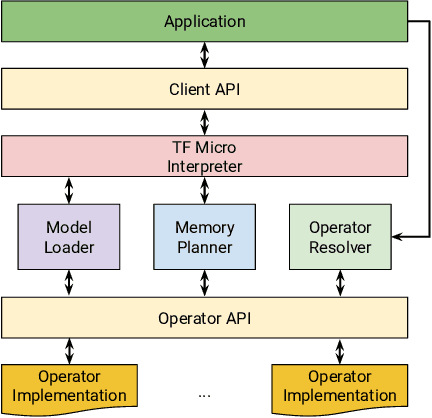
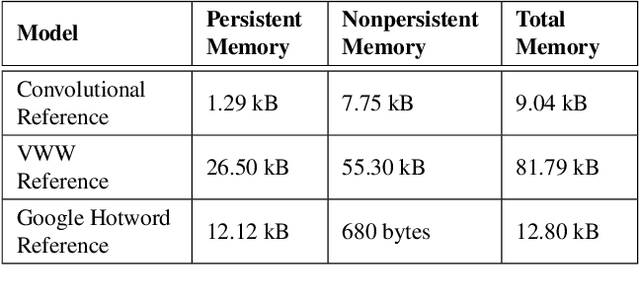
Deep learning inference on embedded devices is a burgeoning field with myriad applications because tiny embedded devices are omnipresent. But we must overcome major challenges before we can benefit from this opportunity. Embedded processors are severely resource constrained. Their nearest mobile counterparts exhibit at least a 100---1,000x difference in compute capability, memory availability, and power consumption. As a result, the machine-learning (ML) models and associated ML inference framework must not only execute efficiently but also operate in a few kilobytes of memory. Also, the embedded devices' ecosystem is heavily fragmented. To maximize efficiency, system vendors often omit many features that commonly appear in mainstream systems, including dynamic memory allocation and virtual memory, that allow for cross-platform interoperability. The hardware comes in many flavors (e.g., instruction-set architecture and FPU support, or lack thereof). We introduce TensorFlow Lite Micro (TF Micro), an open-source ML inference framework for running deep-learning models on embedded systems. TF Micro tackles the efficiency requirements imposed by embedded-system resource constraints and the fragmentation challenges that make cross-platform interoperability nearly impossible. The framework adopts a unique interpreter-based approach that provides flexibility while overcoming these challenges. This paper explains the design decisions behind TF Micro and describes its implementation details. Also, we present an evaluation to demonstrate its low resource requirement and minimal run-time performance overhead.
MLPerf Inference Benchmark
Nov 06, 2019
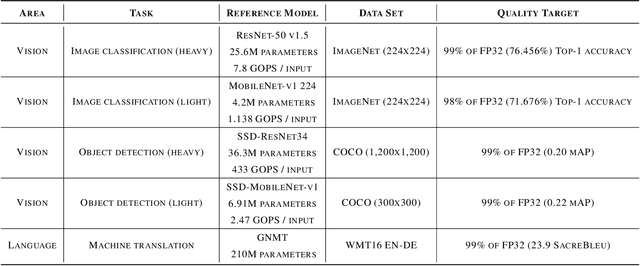
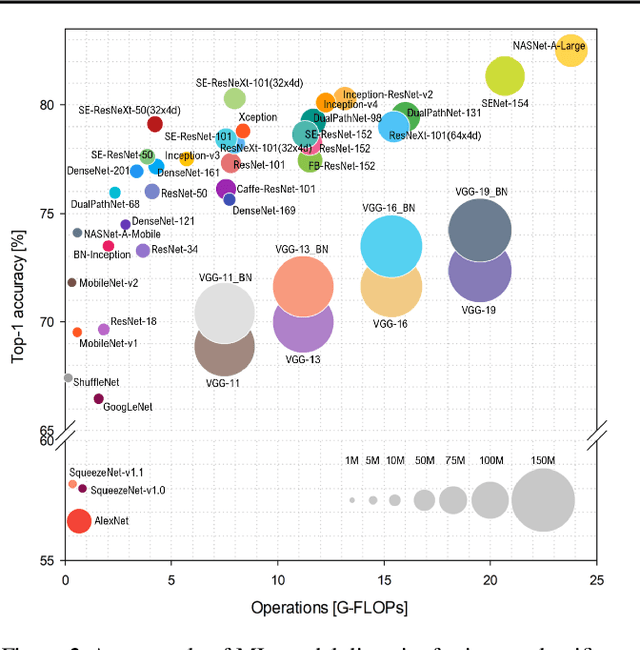
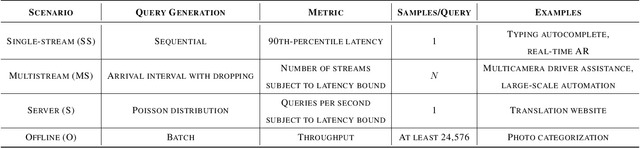
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.