 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Investigating Robustness of Dialog Models to Popular Figurative Language Constructs
Oct 01, 2021
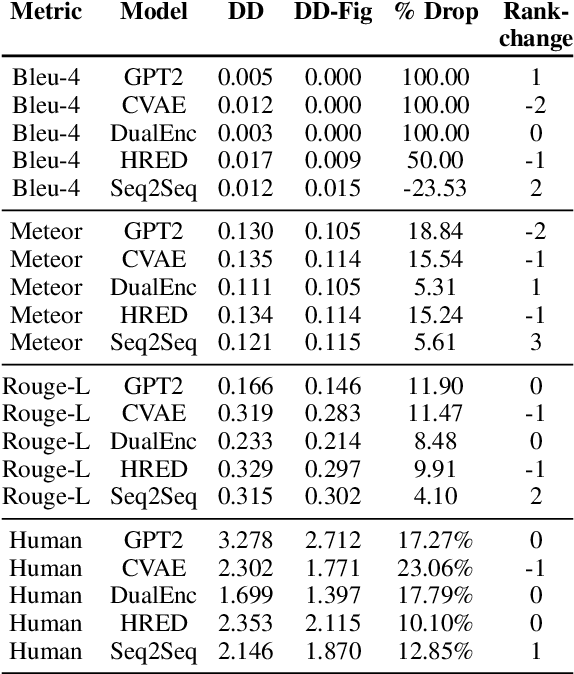
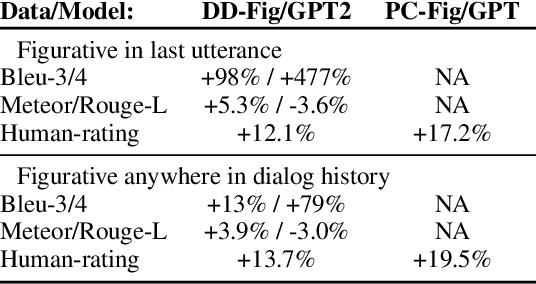

Humans often employ figurative language use in communication, including during interactions with dialog systems. Thus, it is important for real-world dialog systems to be able to handle popular figurative language constructs like metaphor and simile. In this work, we analyze the performance of existing dialog models in situations where the input dialog context exhibits use of figurative language. We observe large gaps in handling of figurative language when evaluating the models on two open domain dialog datasets. When faced with dialog contexts consisting of figurative language, some models show very large drops in performance compared to contexts without figurative language. We encourage future research in dialog modeling to separately analyze and report results on figurative language in order to better test model capabilities relevant to real-world use. Finally, we propose lightweight solutions to help existing models become more robust to figurative language by simply using an external resource to translate figurative language to literal (non-figurative) forms while preserving the meaning to the best extent possible.
Coarse2Fine: Fine-grained Text Classification on Coarsely-grained Annotated Data
Sep 22, 2021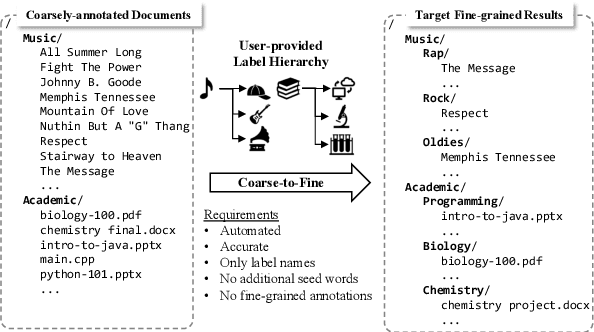


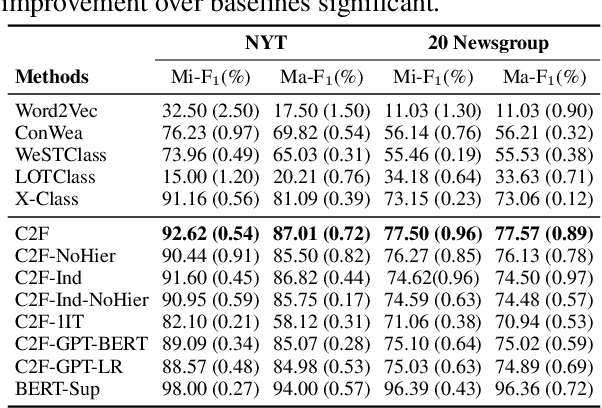
Existing text classification methods mainly focus on a fixed label set, whereas many real-world applications require extending to new fine-grained classes as the number of samples per label increases. To accommodate such requirements, we introduce a new problem called coarse-to-fine grained classification, which aims to perform fine-grained classification on coarsely annotated data. Instead of asking for new fine-grained human annotations, we opt to leverage label surface names as the only human guidance and weave in rich pre-trained generative language models into the iterative weak supervision strategy. Specifically, we first propose a label-conditioned finetuning formulation to attune these generators for our task. Furthermore, we devise a regularization objective based on the coarse-fine label constraints derived from our problem setting, giving us even further improvements over the prior formulation. Our framework uses the fine-tuned generative models to sample pseudo-training data for training the classifier, and bootstraps on real unlabeled data for model refinement. Extensive experiments and case studies on two real-world datasets demonstrate superior performance over SOTA zero-shot classification baselines.
Retrieve, Caption, Generate: Visual Grounding for Enhancing Commonsense in Text Generation Models
Sep 08, 2021
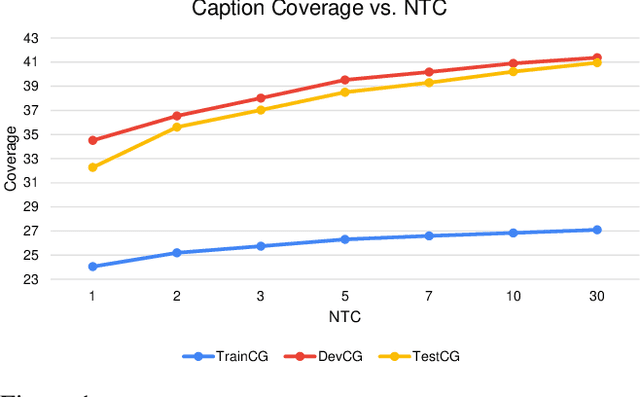
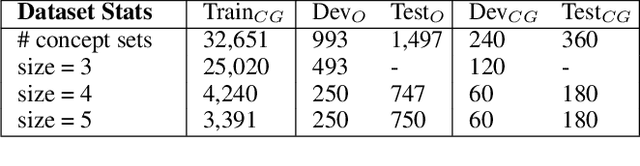
We investigate the use of multimodal information contained in images as an effective method for enhancing the commonsense of Transformer models for text generation. We perform experiments using BART and T5 on concept-to-text generation, specifically the task of generative commonsense reasoning, or CommonGen. We call our approach VisCTG: Visually Grounded Concept-to-Text Generation. VisCTG involves captioning images representing appropriate everyday scenarios, and using these captions to enrich and steer the generation process. Comprehensive evaluation and analysis demonstrate that VisCTG noticeably improves model performance while successfully addressing several issues of the baseline generations, including poor commonsense, fluency, and specificity.
SAPPHIRE: Approaches for Enhanced Concept-to-Text Generation
Aug 15, 2021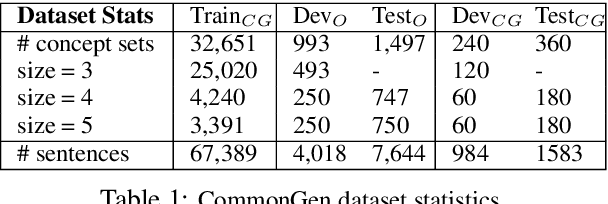
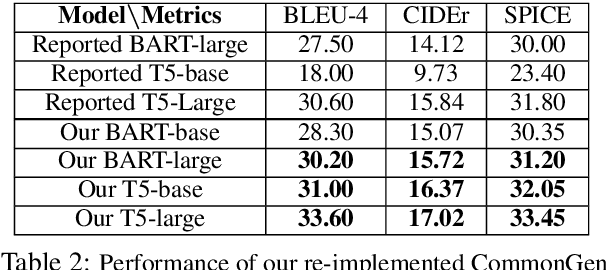
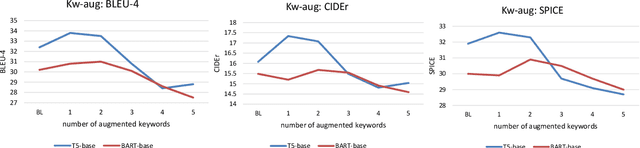
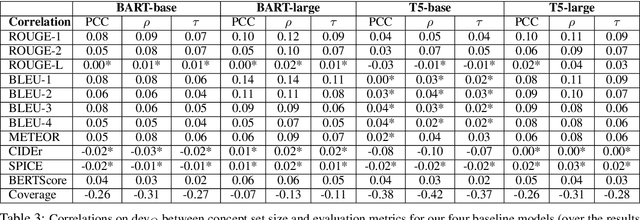
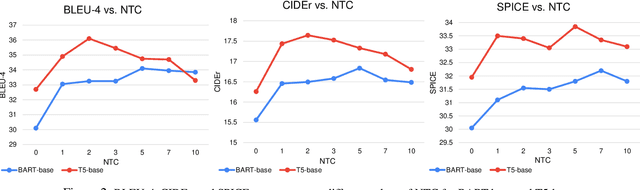
We motivate and propose a suite of simple but effective improvements for concept-to-text generation called SAPPHIRE: Set Augmentation and Post-hoc PHrase Infilling and REcombination. We demonstrate their effectiveness on generative commonsense reasoning, a.k.a. the CommonGen task, through experiments using both BART and T5 models. Through extensive automatic and human evaluation, we show that SAPPHIRE noticeably improves model performance. An in-depth qualitative analysis illustrates that SAPPHIRE effectively addresses many issues of the baseline model generations, including lack of commonsense, insufficient specificity, and poor fluency.
Automatic Construction of Evaluation Suites for Natural Language Generation Datasets
Jun 16, 2021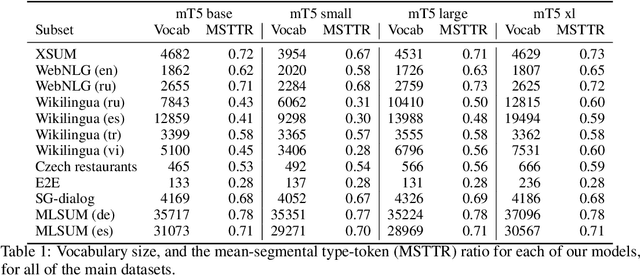
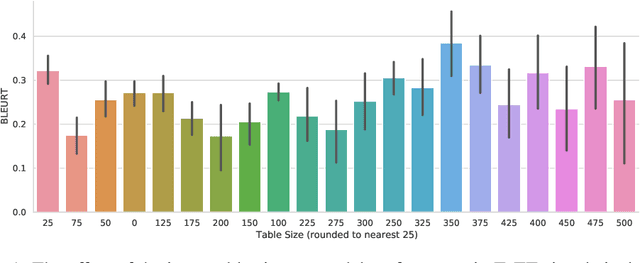
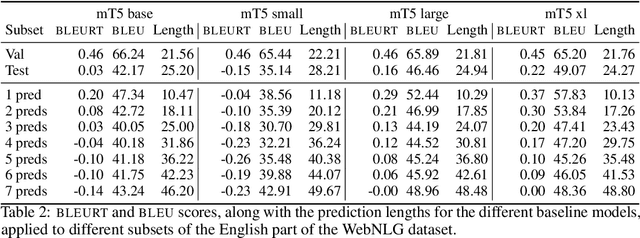
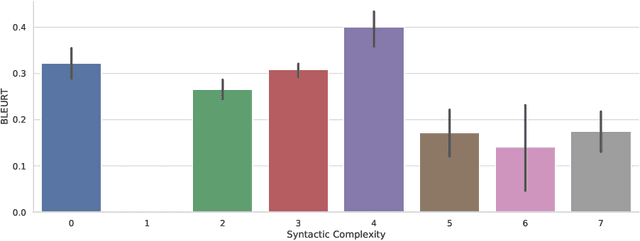
Machine learning approaches applied to NLP are often evaluated by summarizing their performance in a single number, for example accuracy. Since most test sets are constructed as an i.i.d. sample from the overall data, this approach overly simplifies the complexity of language and encourages overfitting to the head of the data distribution. As such, rare language phenomena or text about underrepresented groups are not equally included in the evaluation. To encourage more in-depth model analyses, researchers have proposed the use of multiple test sets, also called challenge sets, that assess specific capabilities of a model. In this paper, we develop a framework based on this idea which is able to generate controlled perturbations and identify subsets in text-to-scalar, text-to-text, or data-to-text settings. By applying this framework to the GEM generation benchmark, we propose an evaluation suite made of 80 challenge sets, demonstrate the kinds of analyses that it enables and shed light onto the limits of current generation models.
Improving Automated Evaluation of Open Domain Dialog via Diverse Reference Augmentation
Jun 05, 2021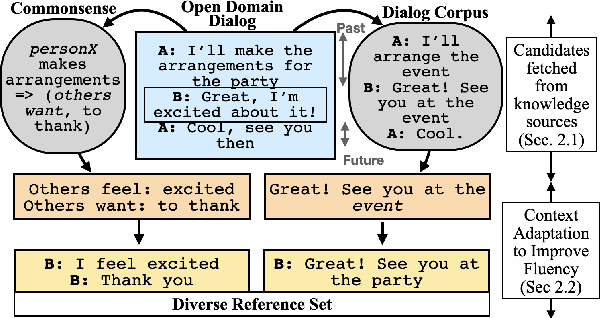



Multiple different responses are often plausible for a given open domain dialog context. Prior work has shown the importance of having multiple valid reference responses for meaningful and robust automated evaluations. In such cases, common practice has been to collect more human written references. However, such collection can be expensive, time consuming, and not easily scalable. Instead, we propose a novel technique for automatically expanding a human generated reference to a set of candidate references. We fetch plausible references from knowledge sources, and adapt them so that they are more fluent in context of the dialog instance in question. More specifically, we use (1) a commonsense knowledge base to elicit a large number of plausible reactions given the dialog history (2) relevant instances retrieved from dialog corpus, using similar past as well as future contexts. We demonstrate that our automatically expanded reference sets lead to large improvements in correlations of automated metrics with human ratings of system outputs for DailyDialog dataset.
A Survey of Data Augmentation Approaches for NLP
May 29, 2021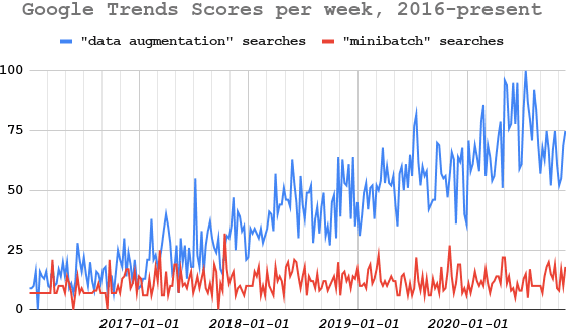
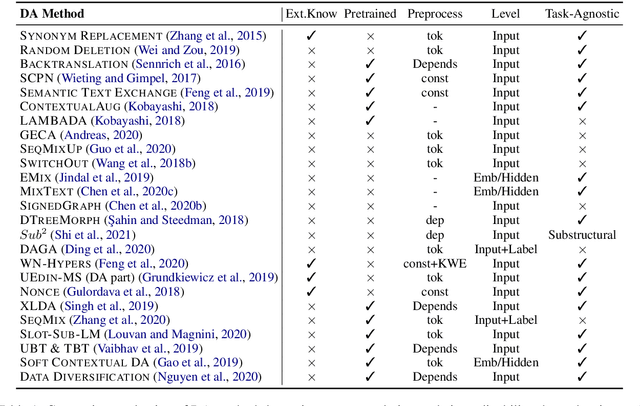
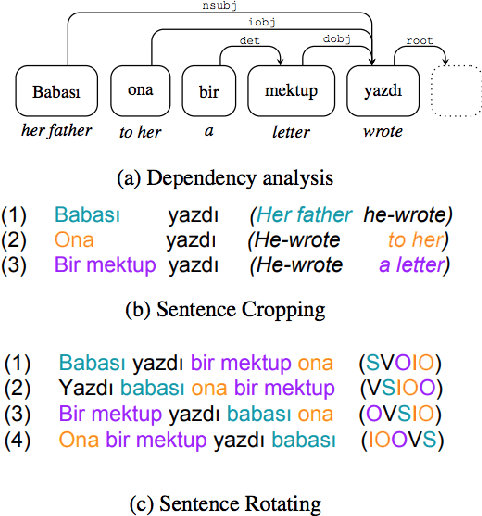
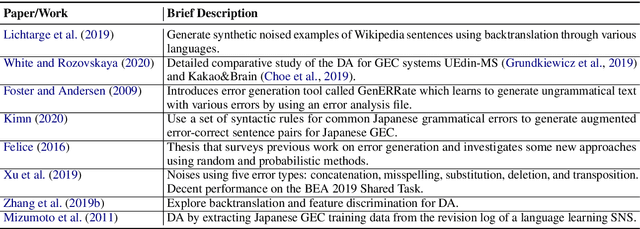
Data augmentation has recently seen increased interest in NLP due to more work in low-resource domains, new tasks, and the popularity of large-scale neural networks that require large amounts of training data. Despite this recent upsurge, this area is still relatively underexplored, perhaps due to the challenges posed by the discrete nature of language data. In this paper, we present a comprehensive and unifying survey of data augmentation for NLP by summarizing the literature in a structured manner. We first introduce and motivate data augmentation for NLP, and then discuss major methodologically representative approaches. Next, we highlight techniques that are used for popular NLP applications and tasks. We conclude by outlining current challenges and directions for future research. Overall, our paper aims to clarify the landscape of existing literature in data augmentation for NLP and motivate additional work in this area. We also present a GitHub repository with a paper list that will be continuously updated at https://github.com/styfeng/DataAug4NLP
NAREOR: The Narrative Reordering Problem
Apr 14, 2021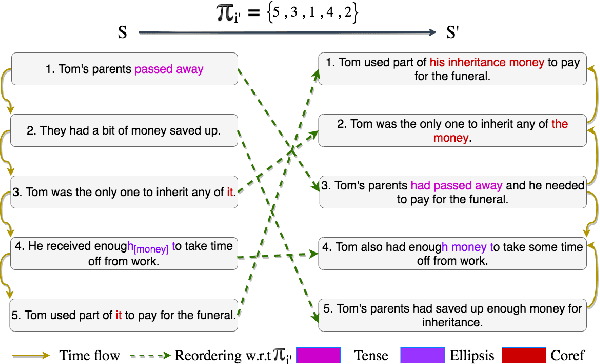

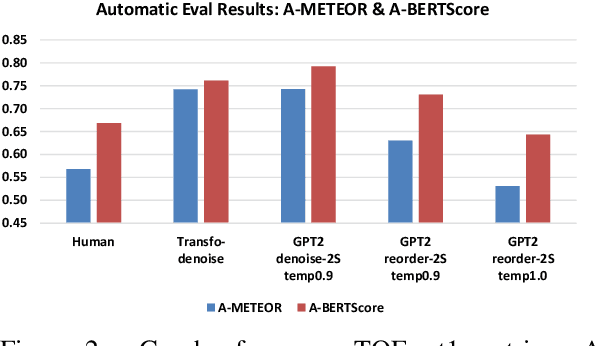
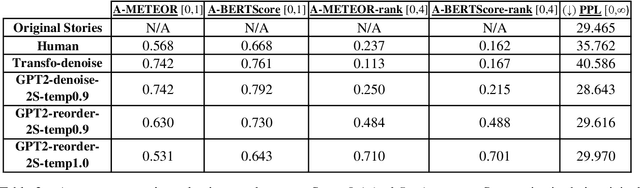
We propose the task of Narrative Reordering(NAREOR) which involves rewriting a given story in a different narrative order while preserving its plot, semantic, and temporal aspects. We present a dataset, NAREORC, with over 1000 human rewritings of stories within ROCStories in non-linear orders, and conduct a detailed analysis of it. Further, we propose novel initial task-specific training methods and evaluation metrics. We perform experiments on NAREORC using GPT-2 and Transformer models and conduct an extensive human evaluation. We demonstrate that NAREOR is a challenging task with potential for further exploration.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.