 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluWorld: A Controlled Benchmark for Hallucination via Reference World Models
May 19, 2026Hallucination remains a central failure mode of large language models, but existing benchmarks operationalize it inconsistently across summarization, question answering, retrieval-augmented generation, and agentic interaction. This fragmentation makes it unclear whether a mitigation that works in one setting reduces hallucinations across contexts. Current benchmarks either require human annotation and fixed references that may be memorized, or rely on observations in settings that are difficult to reproduce. To study root causes, we introduce HalluWorld, an extensible benchmark grounded in an explicit reference-world formulation: a model hallucinates when it produces an observable claim that is false with respect to this world. Building on this view, we construct synthetic and semi-synthetic environments in which the reference world is fully specified, the model's view is controlled, and hallucination labels are generated automatically. HalluWorld spans gridworlds, chess, and realistic terminal tasks, enabling controlled variation of world complexity, observability, temporal change, and source-conflict policy, and disentangling hallucinations into fine-grained error categories. We evaluate frontier and open-weight language models across these settings and find consistent patterns: perceptual hallucination on directly observed information is near-solved for frontier models, while multi-step state tracking and causal forward simulation remain difficult and are not generally solved by extended thinking. In the terminal setting, models also struggle with when to abstain. The uneven profile of failures across probe types and domains suggests that hallucinations arise from distinct failure modes rather than a single capability. Our results suggest that controlled reference worlds offer a scalable and reproducible path toward measuring and reducing hallucinations in modern language models.
To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
Apr 01, 2026Retrieval-augmented generation (RAG) improves language model (LM) performance by providing relevant context at test time for knowledge-intensive situations. However, the relationship between parametric knowledge acquired during pretraining and non-parametric knowledge accessed via retrieval remains poorly understood, especially under fixed data budgets. In this work, we systematically study the trade-off between pretraining corpus size and retrieval store size across a wide range of model and data scales. We train OLMo-2-based LMs ranging from 30M to 3B parameters on up to 100B tokens of DCLM data, while varying both pretraining data scale (1-150x the number of parameters) and retrieval store size (1-20x), and evaluate performance across a diverse suite of benchmarks spanning reasoning, scientific QA, and open-domain QA. We find that retrieval consistently improves performance over parametric-only baselines across model scales and introduce a three-dimensional scaling framework that models performance as a function of model size, pretraining tokens, and retrieval corpus size. This scaling manifold enables us to estimate optimal allocations of a fixed data budget between pretraining and retrieval, revealing that the marginal utility of retrieval depends strongly on model scale, task type, and the degree of pretraining saturation. Our results provide a quantitative foundation for understanding when and how retrieval should complement pretraining, offering practical guidance for allocating data resources in the design of scalable language modeling systems.
Baby Scale: Investigating Models Trained on Individual Children's Language Input
Mar 31, 2026Modern language models (LMs) must be trained on many orders of magnitude more words of training data than human children receive before they begin to produce useful behavior. Assessing the nature and origins of this "data gap" requires benchmarking LMs on human-scale datasets to understand how linguistic knowledge emerges from children's natural training data. Using transcripts from the BabyView dataset (videos from children ages 6-36 months), we investigate (1) scaling performance at child-scale data regimes, (2) variability in model performance across datasets from different children's experiences and linguistic predictors of dataset quality, and (3) relationships between model and child language learning outcomes. LMs trained on child data show acceptable scaling for grammar tasks, but lower scaling on semantic and world knowledge tasks than models trained on synthetic data; we also observe substantial variability on data from different children. Beyond dataset size, performance is most associated with a combination of distributional and interactional linguistic features, broadly consistent with what makes high-quality input for child language development. Finally, model likelihoods for individual words correlate with children's learning of those words, suggesting that properties of child-directed input may influence both model learning and human language development. Overall, understanding what properties make language data efficient for learning can enable more powerful small-scale language models while also shedding light on human language acquisition.
Bringing Up a Bilingual BabyLM: Investigating Multilingual Language Acquisition Using Small-Scale Models
Mar 31, 2026Multilingualism is incredibly common around the world, leading to many important theoretical and practical questions about how children learn multiple languages at once. For example, does multilingual acquisition lead to delays in learning? Are there better and worse ways to structure multilingual input? Many correlational studies address these questions, but it is surprisingly difficult to get definitive answers because children cannot be randomly assigned to be multilingual and data are typically not matched between languages. We use language model training as a method for simulating a variety of highly controlled exposure conditions, and create matched 100M-word mono- and bilingual datasets using synthetic data and machine translation. We train GPT-2 models on monolingual and bilingual data organized to reflect a range of exposure regimes, and evaluate their performance on perplexity, grammaticality, and semantic knowledge. Across model scales and measures, bilingual models perform similarly to monolingual models in one language, but show strong performance in the second language as well. These results suggest that there are no strong differences between different bilingual exposure regimes, and that bilingual input poses no in-principle challenges for agnostic statistical learners.
A Unified Definition of Hallucination, Or: It's the World Model, Stupid
Dec 25, 2025Despite numerous attempts to solve the issue of hallucination since the inception of neural language models, it remains a problem in even frontier large language models today. Why is this the case? We walk through definitions of hallucination used in the literature from a historical perspective up to the current day, and fold them into a single definition of hallucination, wherein different prior definitions focus on different aspects of our definition. At its core, we argue that hallucination is simply inaccurate (internal) world modeling, in a form where it is observable to the user (e.g., stating a fact which contradicts a knowledge base, or producing a summary which contradicts a known source). By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature. We argue that this unified view is useful because it forces evaluations to make clear their assumed "world" or source of truth, clarifies what should and should not be called hallucination (as opposed to planning or reward/incentive-related errors), and provides a common language to compare benchmarks and mitigation techniques. Building on this definition, we outline plans for a family of benchmarks in which hallucinations are defined as mismatches with synthetic but fully specified world models in different environments, and sketch out how these benchmarks can use such settings to stress-test and improve the world modeling components of language models.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Is Child-Directed Speech Effective Training Data for Language Models?
Aug 07, 2024



While high-performing language models are typically trained on hundreds of billions of words, human children become fluent language users with a much smaller amount of data. What are the features of the data they receive, and how do these features support language modeling objectives? To investigate this question, we train GPT-2 models on 29M words of English-language child-directed speech and a new matched, synthetic dataset (TinyDialogues), comparing to a heterogeneous blend of datasets from the BabyLM challenge. We evaluate both the syntactic and semantic knowledge of these models using developmentally-inspired evaluations. Through pretraining experiments, we test whether the global developmental ordering or the local discourse ordering of children's training data support high performance relative to other datasets. The local properties of the data affect model results, but somewhat surprisingly, global properties do not. Further, child language input is not uniquely valuable for training language models. These findings support the hypothesis that, rather than proceeding from better data, children's learning is instead substantially more efficient than current language modeling techniques.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024



Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?
CHARD: Clinical Health-Aware Reasoning Across Dimensions for Text Generation Models
Oct 09, 2022
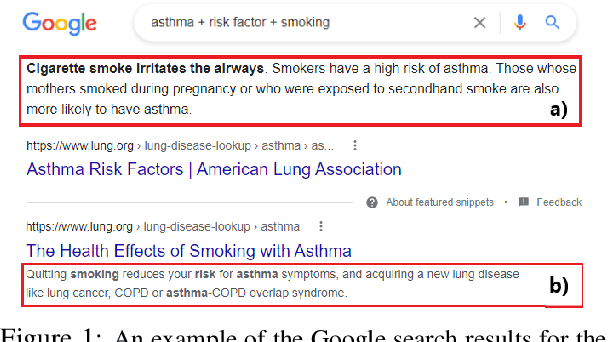
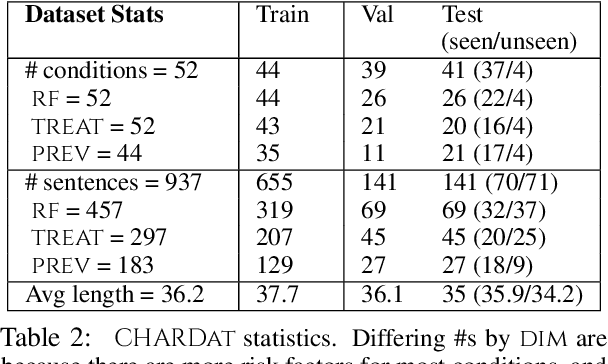
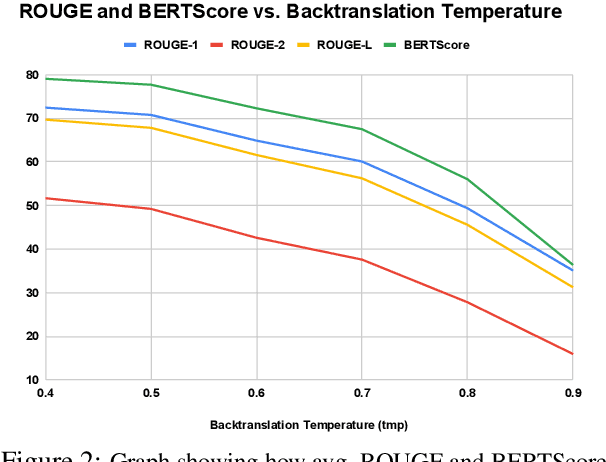
We motivate and introduce CHARD: Clinical Health-Aware Reasoning across Dimensions, to investigate the capability of text generation models to act as implicit clinical knowledge bases and generate free-flow textual explanations about various health-related conditions across several dimensions. We collect and present an associated dataset, CHARDat, consisting of explanations about 52 health conditions across three clinical dimensions. We conduct extensive experiments using BART and T5 along with data augmentation, and perform automatic, human, and qualitative analyses. We show that while our models can perform decently, CHARD is very challenging with strong potential for further exploration.
PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation
Sep 16, 2022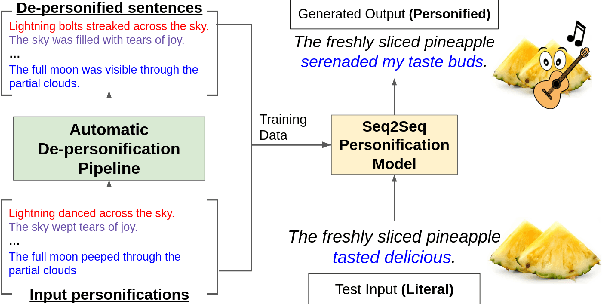
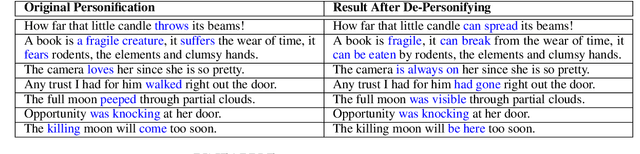
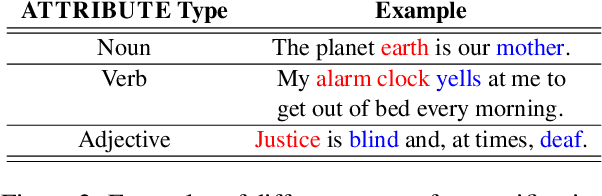
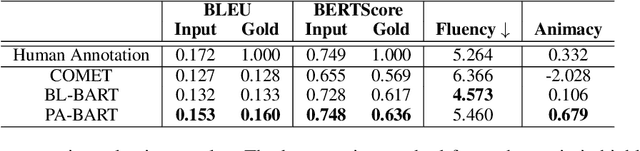
A personification is a figure of speech that endows inanimate entities with properties and actions typically seen as requiring animacy. In this paper, we explore the task of personification generation. To this end, we propose PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation. We curate a corpus of personifications called PersonifCorp, together with automatically generated de-personified literalizations of these personifications. We demonstrate the usefulness of this parallel corpus by training a seq2seq model to personify a given literal input. Both automatic and human evaluations show that fine-tuning with PersonifCorp leads to significant gains in personification-related qualities such as animacy and interestingness. A detailed qualitative analysis also highlights key strengths and imperfections of PINEAPPLE over baselines, demonstrating a strong ability to generate diverse and creative personifications that enhance the overall appeal of a sentence.