 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Deep Generative Models for Approximation and Estimation of Distributions on Manifolds
Feb 25, 2023



Generative networks have experienced great empirical successes in distribution learning. Many existing experiments have demonstrated that generative networks can generate high-dimensional complex data from a low-dimensional easy-to-sample distribution. However, this phenomenon can not be justified by existing theories. The widely held manifold hypothesis speculates that real-world data sets, such as natural images and signals, exhibit low-dimensional geometric structures. In this paper, we take such low-dimensional data structures into consideration by assuming that data distributions are supported on a low-dimensional manifold. We prove statistical guarantees of generative networks under the Wasserstein-1 loss. We show that the Wasserstein-1 loss converges to zero at a fast rate depending on the intrinsic dimension instead of the ambient data dimension. Our theory leverages the low-dimensional geometric structures in data sets and justifies the practical power of generative networks. We require no smoothness assumptions on the data distribution which is desirable in practice.
HomoDistil: Homotopic Task-Agnostic Distillation of Pre-trained Transformers
Feb 19, 2023Knowledge distillation has been shown to be a powerful model compression approach to facilitate the deployment of pre-trained language models in practice. This paper focuses on task-agnostic distillation. It produces a compact pre-trained model that can be easily fine-tuned on various tasks with small computational costs and memory footprints. Despite the practical benefits, task-agnostic distillation is challenging. Since the teacher model has a significantly larger capacity and stronger representation power than the student model, it is very difficult for the student to produce predictions that match the teacher's over a massive amount of open-domain training data. Such a large prediction discrepancy often diminishes the benefits of knowledge distillation. To address this challenge, we propose Homotopic Distillation (HomoDistil), a novel task-agnostic distillation approach equipped with iterative pruning. Specifically, we initialize the student model from the teacher model, and iteratively prune the student's neurons until the target width is reached. Such an approach maintains a small discrepancy between the teacher's and student's predictions throughout the distillation process, which ensures the effectiveness of knowledge transfer. Extensive experiments demonstrate that HomoDistil achieves significant improvements on existing baselines.
Score Approximation, Estimation and Distribution Recovery of Diffusion Models on Low-Dimensional Data
Feb 14, 2023Diffusion models achieve state-of-the-art performance in various generation tasks. However, their theoretical foundations fall far behind. This paper studies score approximation, estimation, and distribution recovery of diffusion models, when data are supported on an unknown low-dimensional linear subspace. Our result provides sample complexity bounds for distribution estimation using diffusion models. We show that with a properly chosen neural network architecture, the score function can be both accurately approximated and efficiently estimated. Furthermore, the generated distribution based on the estimated score function captures the data geometric structures and converges to a close vicinity of the data distribution. The convergence rate depends on the subspace dimension, indicating that diffusion models can circumvent the curse of data ambient dimensionality.
Efficient Long Sequence Modeling via State Space Augmented Transformer
Dec 15, 2022



Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for $\underline{\textbf{S}}$tate s$\underline{\textbf{P}}$ace $\underline{\textbf{A}}$ugmente$\underline{\textbf{D}}$ Transform$\underline{\textbf{E}}$r. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
High Dimensional Binary Classification under Label Shift: Phase Transition and Regularization
Dec 08, 2022Label Shift has been widely believed to be harmful to the generalization performance of machine learning models. Researchers have proposed many approaches to mitigate the impact of the label shift, e.g., balancing the training data. However, these methods often consider the underparametrized regime, where the sample size is much larger than the data dimension. The research under the overparametrized regime is very limited. To bridge this gap, we propose a new asymptotic analysis of the Fisher Linear Discriminant classifier for binary classification with label shift. Specifically, we prove that there exists a phase transition phenomenon: Under certain overparametrized regime, the classifier trained using imbalanced data outperforms the counterpart with reduced balanced data. Moreover, we investigate the impact of regularization to the label shift: The aforementioned phase transition vanishes as the regularization becomes strong.
Less is More: Task-aware Layer-wise Distillation for Language Model Compression
Oct 05, 2022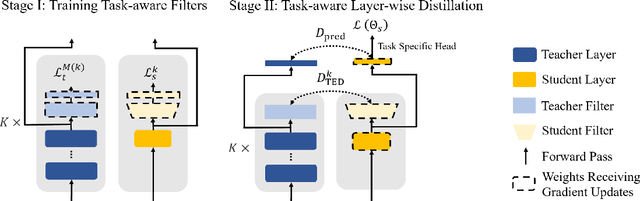
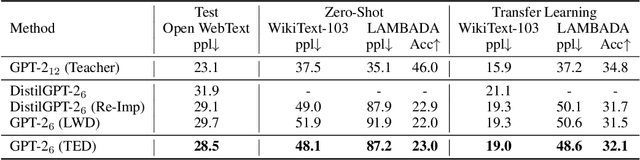
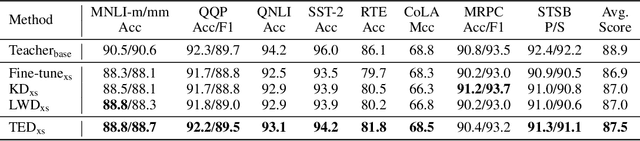
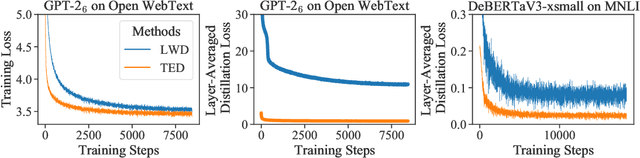
Layer-wise distillation is a powerful tool to compress large models (i.e. teacher models) into small ones (i.e., student models). The student distills knowledge from the teacher by mimicking the hidden representations of the teacher at every intermediate layer. However, layer-wise distillation is difficult. Since the student has a smaller model capacity than the teacher, it is often under-fitted. Furthermore, the hidden representations of the teacher contain redundant information that the student does not necessarily need for the target task's learning. To address these challenges, we propose a novel Task-aware layEr-wise Distillation (TED). TED designs task-aware filters to align the hidden representations of the student and the teacher at each layer. The filters select the knowledge that is useful for the target task from the hidden representations. As such, TED reduces the knowledge gap between the two models and helps the student to fit better on the target task. We evaluate TED in two scenarios: continual pre-training and fine-tuning. TED demonstrates significant and consistent improvements over existing distillation methods in both scenarios.
Context-Aware Query Rewriting for Improving Users' Search Experience on E-commerce Websites
Sep 24, 2022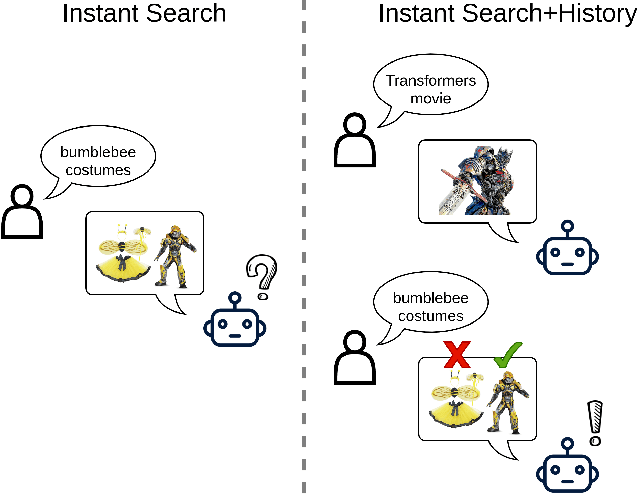
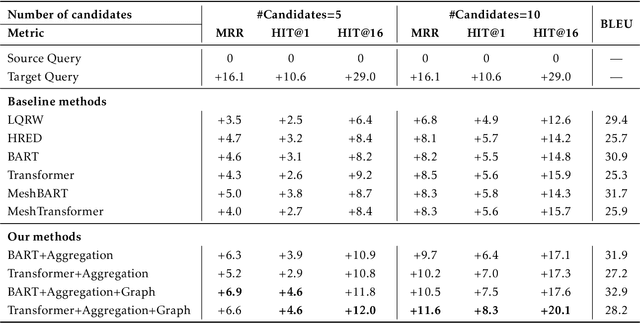
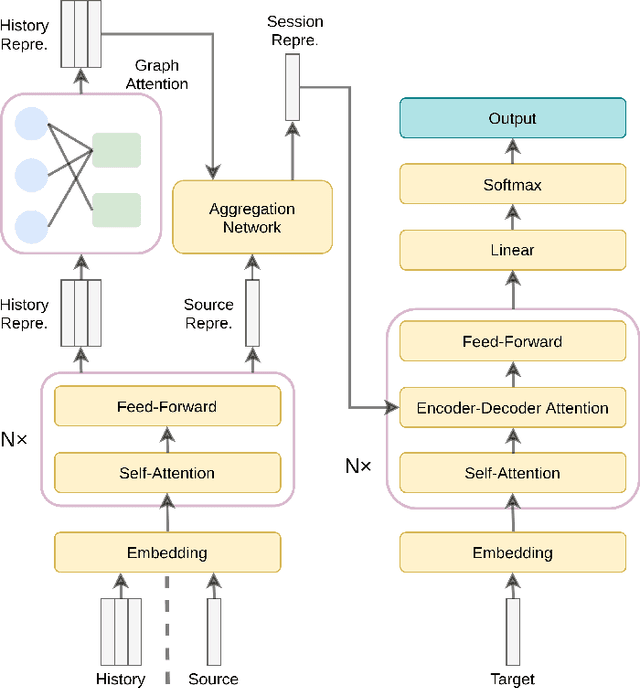
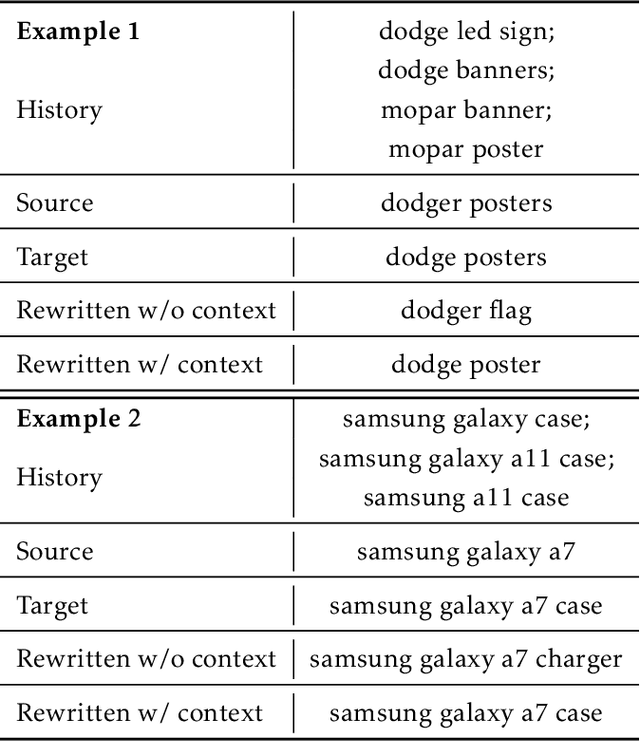
E-commerce queries are often short and ambiguous. Consequently, query understanding often uses query rewriting to disambiguate user-input queries. While using e-commerce search tools, users tend to enter multiple searches, which we call context, before purchasing. These history searches contain contextual insights about users' true shopping intents. Therefore, modeling such contextual information is critical to a better query rewriting model. However, existing query rewriting models ignore users' history behaviors and consider only the instant search query, which is often a short string offering limited information about the true shopping intent. We propose an end-to-end context-aware query rewriting model to bridge this gap, which takes the search context into account. Specifically, our model builds a session graph using the history search queries and their contained words. We then employ a graph attention mechanism that models cross-query relations and computes contextual information of the session. The model subsequently calculates session representations by combining the contextual information with the instant search query using an aggregation network. The session representations are then decoded to generate rewritten queries. Empirically, we demonstrate the superiority of our method to state-of-the-art approaches under various metrics. On in-house data from an online shopping platform, by introducing contextual information, our model achieves 11.6% improvement under the MRR (Mean Reciprocal Rank) metric and 20.1% improvement under the HIT@16 metric (a hit rate metric), in comparison with the best baseline method (Transformer-based model).
First-order Policy Optimization for Robust Markov Decision Process
Sep 21, 2022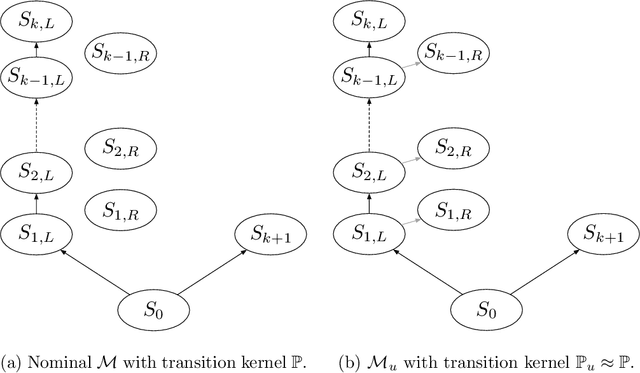
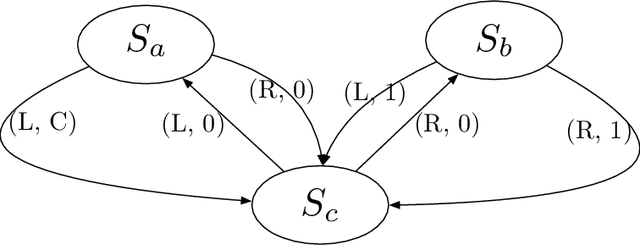
We consider the problem of solving robust Markov decision process (MDP), which involves a set of discounted, finite state, finite action space MDPs with uncertain transition kernels. The goal of planning is to find a robust policy that optimizes the worst-case values against the transition uncertainties, and thus encompasses the standard MDP planning as a special case. For $(\mathbf{s},\mathbf{a})$-rectangular uncertainty sets, we develop a policy-based first-order method, namely the robust policy mirror descent (RPMD), and establish an $\mathcal{O}(\log(1/\epsilon))$ and $\mathcal{O}(1/\epsilon)$ iteration complexity for finding an $\epsilon$-optimal policy, with two increasing-stepsize schemes. The prior convergence of RPMD is applicable to any Bregman divergence, provided the policy space has bounded radius measured by the divergence when centering at the initial policy. Moreover, when the Bregman divergence corresponds to the squared euclidean distance, we establish an $\mathcal{O}(\max \{1/\epsilon, 1/(\eta \epsilon^2)\})$ complexity of RPMD with any constant stepsize $\eta$. For a general class of Bregman divergences, a similar complexity is also established for RPMD with constant stepsizes, provided the uncertainty set satisfies the relative strong convexity. We further develop a stochastic variant, named SRPMD, when the first-order information is only available through online interactions with the nominal environment. For general Bregman divergences, we establish an $\mathcal{O}(1/\epsilon^2)$ and $\mathcal{O}(1/\epsilon^3)$ sample complexity with two increasing-stepsize schemes. For the euclidean Bregman divergence, we establish an $\mathcal{O}(1/\epsilon^3)$ sample complexity with constant stepsizes. To the best of our knowledge, all the aforementioned results appear to be new for policy-based first-order methods applied to the robust MDP problem.
DiP-GNN: Discriminative Pre-Training of Graph Neural Networks
Sep 15, 2022
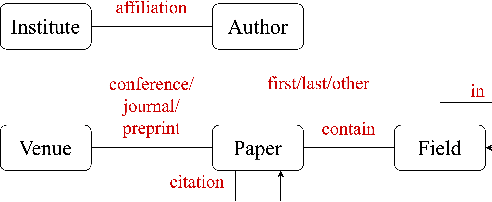
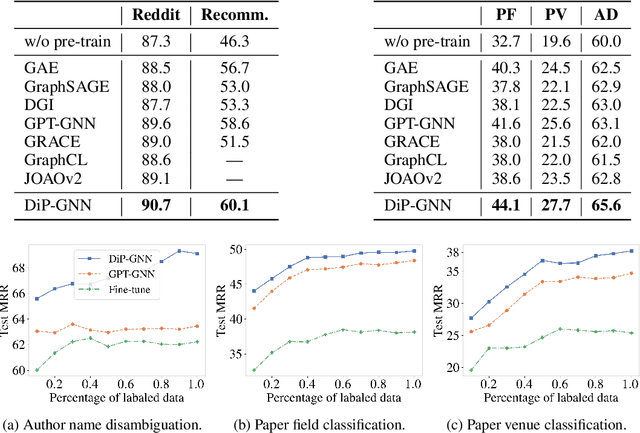
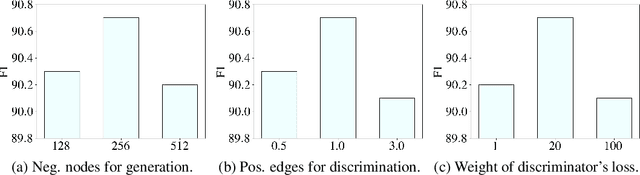
Graph neural network (GNN) pre-training methods have been proposed to enhance the power of GNNs. Specifically, a GNN is first pre-trained on a large-scale unlabeled graph and then fine-tuned on a separate small labeled graph for downstream applications, such as node classification. One popular pre-training method is to mask out a proportion of the edges, and a GNN is trained to recover them. However, such a generative method suffers from graph mismatch. That is, the masked graph inputted to the GNN deviates from the original graph. To alleviate this issue, we propose DiP-GNN (Discriminative Pre-training of Graph Neural Networks). Specifically, we train a generator to recover identities of the masked edges, and simultaneously, we train a discriminator to distinguish the generated edges from the original graph's edges. In our framework, the graph seen by the discriminator better matches the original graph because the generator can recover a proportion of the masked edges. Extensive experiments on large-scale homogeneous and heterogeneous graphs demonstrate the effectiveness of the proposed framework.
Differentially Private Estimation of Hawkes Process
Sep 15, 2022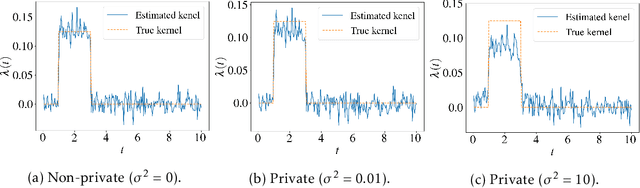

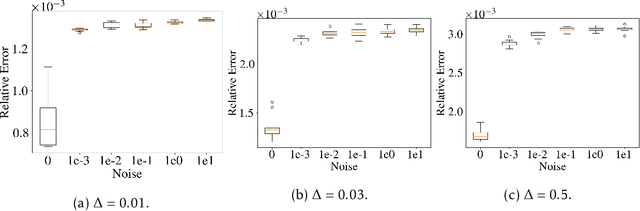
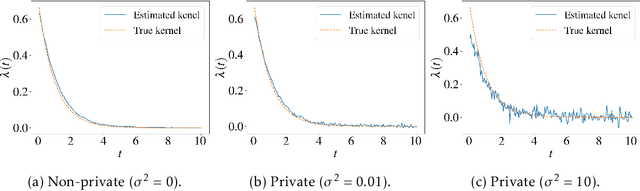
Point process models are of great importance in real world applications. In certain critical applications, estimation of point process models involves large amounts of sensitive personal data from users. Privacy concerns naturally arise which have not been addressed in the existing literature. To bridge this glaring gap, we propose the first general differentially private estimation procedure for point process models. Specifically, we take the Hawkes process as an example, and introduce a rigorous definition of differential privacy for event stream data based on a discretized representation of the Hawkes process. We then propose two differentially private optimization algorithms, which can efficiently estimate Hawkes process models with the desired privacy and utility guarantees under two different settings. Experiments are provided to back up our theoretical analysis.