 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Non-rigid Structure-from-Motion: A Sequence-to-Sequence Translation Perspective
Apr 10, 2022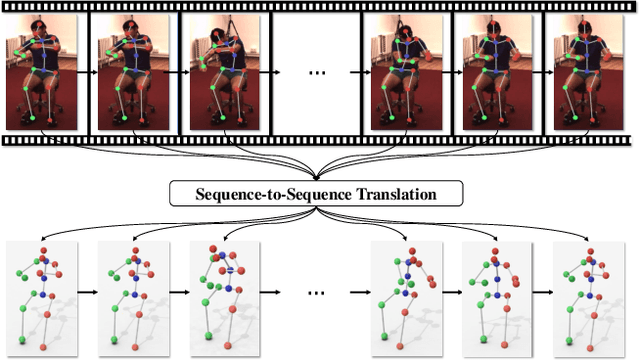
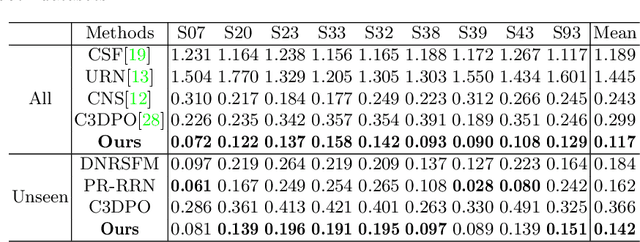
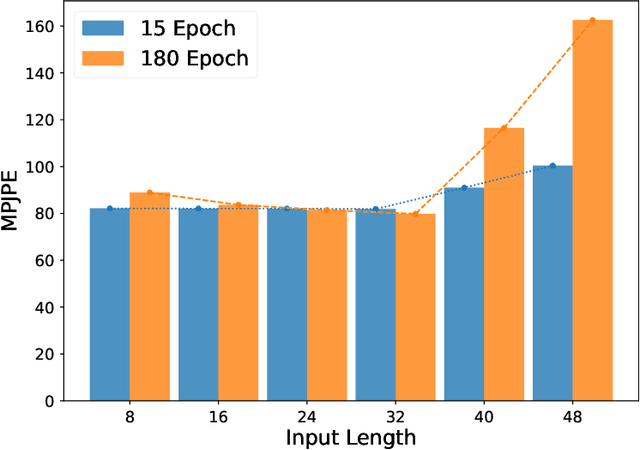
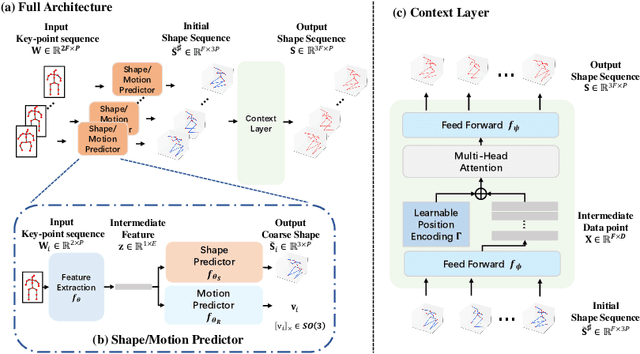
Directly regressing the non-rigid shape and camera pose from the individual 2D frame is ill-suited to the Non-Rigid Structure-from-Motion (NRSfM) problem. This frame-by-frame 3D reconstruction pipeline overlooks the inherent spatial-temporal nature of NRSfM, i.e., reconstructing the whole 3D sequence from the input 2D sequence. In this paper, we propose to model deep NRSfM from a sequence-to-sequence translation perspective, where the input 2D frame sequence is taken as a whole to reconstruct the deforming 3D non-rigid shape sequence. First, we apply a shape-motion predictor to estimate the initial non-rigid shape and camera motion from a single frame. Then we propose a context modeling module to model camera motions and complex non-rigid shapes. To tackle the difficulty in enforcing the global structure constraint within the deep framework, we propose to impose the union-of-subspace structure by replacing the self-expressiveness layer with multi-head attention and delayed regularizers, which enables end-to-end batch-wise training. Experimental results across different datasets such as Human3.6M, CMU Mocap and InterHand prove the superiority of our framework. The code will be made publicly available
Non-Linear Reinforcement Learning in Large Action Spaces: Structural Conditions and Sample-efficiency of Posterior Sampling
Mar 15, 2022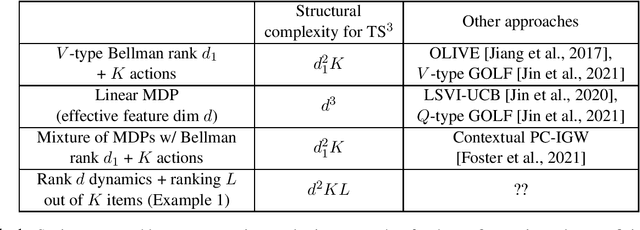
Provably sample-efficient Reinforcement Learning (RL) with rich observations and function approximation has witnessed tremendous recent progress, particularly when the underlying function approximators are linear. In this linear regime, computationally and statistically efficient methods exist where the potentially infinite state and action spaces can be captured through a known feature embedding, with the sample complexity scaling with the (intrinsic) dimension of these features. When the action space is finite, significantly more sophisticated results allow non-linear function approximation under appropriate structural constraints on the underlying RL problem, permitting for instance, the learning of good features instead of assuming access to them. In this work, we present the first result for non-linear function approximation which holds for general action spaces under a linear embeddability condition, which generalizes all linear and finite action settings. We design a novel optimistic posterior sampling strategy, TS^3 for such problems, and show worst case sample complexity guarantees that scale with a rank parameter of the RL problem, the linear embedding dimension introduced in this work and standard measures of the function class complexity.
RC-MVSNet: Unsupervised Multi-View Stereo with Neural Rendering
Mar 14, 2022
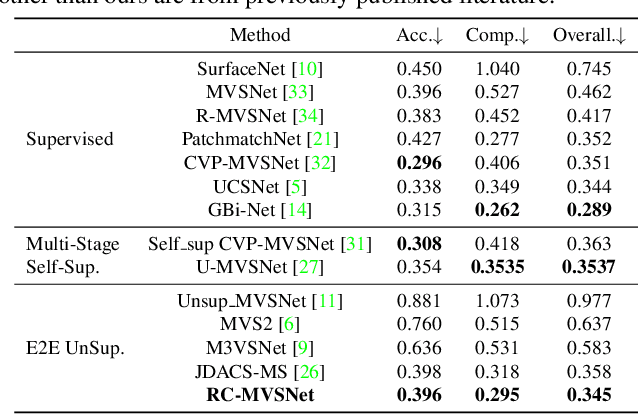
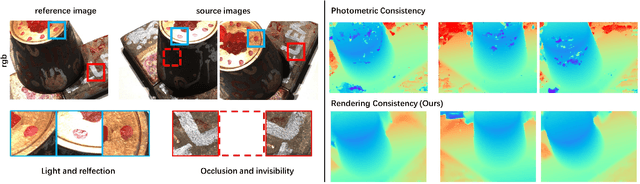
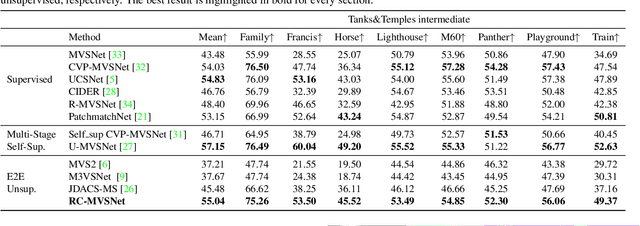
Finding accurate correspondences among different views is the Achilles' heel of unsupervised Multi-View Stereo (MVS). Existing methods are built upon the assumption that corresponding pixels share similar photometric features. However, multi-view images in real scenarios observe non-Lambertian surfaces and experience occlusions. In this work, we propose a novel approach with neural rendering (RC-MVSNet) to solve such ambiguity issues of correspondences among views. Specifically, we impose a depth rendering consistency loss to constrain the geometry features close to the object surface to alleviate occlusions. Concurrently, we introduce a reference view synthesis loss to generate consistent supervision, even for non-Lambertian surfaces. Extensive experiments on DTU and Tanks\&Temples benchmarks demonstrate that our RC-MVSNet approach achieves state-of-the-art performance over unsupervised MVS frameworks and competitive performance to many supervised methods.The trained models and code will be released at https://github.com/Boese0601/RC-MVSNet.
Reconfigurable Intelligent Surface Assisted OFDM Relaying: Subcarrier Matching with Balanced SNR
Mar 03, 2022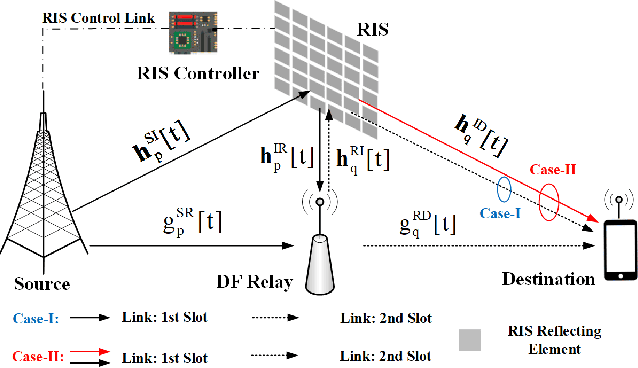
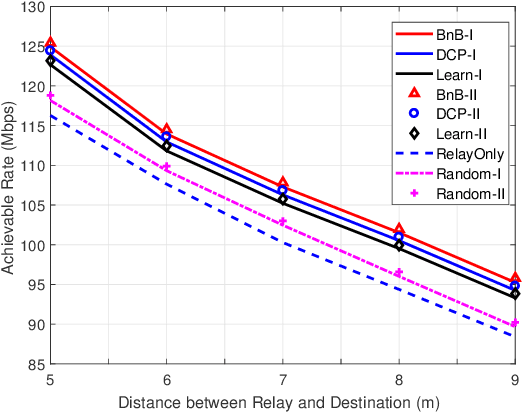
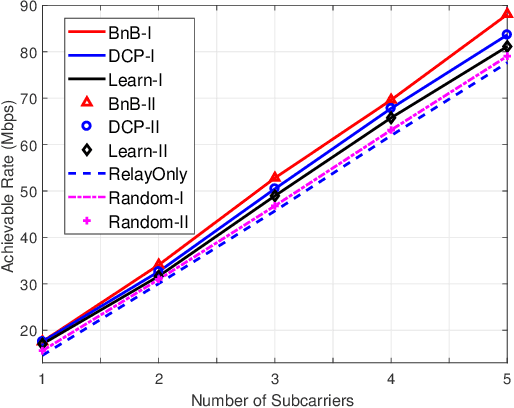
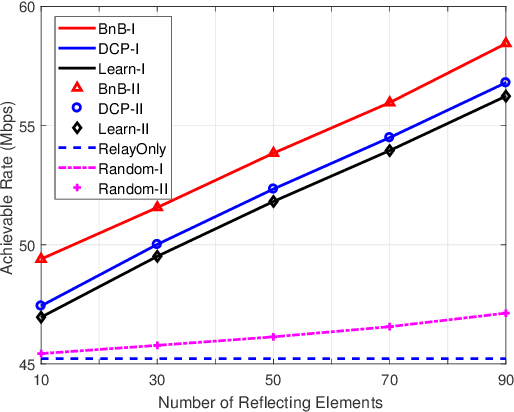
Reconfigurable intelligent surface (RIS) is a promising solution to enhance the performance of wireless communications via reconfiguring the wireless propagation environment. In this paper, we investigate the joint design of RIS passive beamforming and subcarrier matching in RIS-assisted orthogonal frequency division multiplexing (OFDM) dual-hop relaying systems under two cases, depending on the presence of the RIS reflected link from the source to the destination in the first hop. Accordingly, we formulate a mixed-integer nonlinear programming (MINIP) problem to maximize the sum achievable rate over all subcarriers by jointly optimizing the RIS passive beamforming and subcarrier matching. To solve this challenging problem, we first develop a branch-and-bound (BnB)-based alternating optimization algorithm to obtain a near-optimal solution by alternatively optimizing the subcarrier matching by the BnB method and the RIS passive beamforming by using semidefinite relaxation techniques. Then, a low-complexity difference-of-convex penalty-based algorithm is proposed to reduce the computation complexity in the BnB method. To further reduce the computational complexity, we utilize the learning-to-optimize approach to learn the joint design obtained from optimization techniques, which is more amenable to practical implementations. Lastly, computer simulations are presented to evaluate the performance of the proposed algorithms in the two cases. Simulation results demonstrate that the RIS-assisted OFDM relaying system achieves sustainable achievable rate gain as compared to that without RIS, and that with random passive beamforming, since RIS passive beamforming can be leveraged to recast the subcarrier matching among different subcarriers and balance the signal-to-noise ratio within each subcarrier pair.
Pessimistic Minimax Value Iteration: Provably Efficient Equilibrium Learning from Offline Datasets
Feb 15, 2022
We study episodic two-player zero-sum Markov games (MGs) in the offline setting, where the goal is to find an approximate Nash equilibrium (NE) policy pair based on a dataset collected a priori. When the dataset does not have uniform coverage over all policy pairs, finding an approximate NE involves challenges in three aspects: (i) distributional shift between the behavior policy and the optimal policy, (ii) function approximation to handle large state space, and (iii) minimax optimization for equilibrium solving. We propose a pessimism-based algorithm, dubbed as pessimistic minimax value iteration (PMVI), which overcomes the distributional shift by constructing pessimistic estimates of the value functions for both players and outputs a policy pair by solving NEs based on the two value functions. Furthermore, we establish a data-dependent upper bound on the suboptimality which recovers a sublinear rate without the assumption on uniform coverage of the dataset. We also prove an information-theoretical lower bound, which suggests that the data-dependent term in the upper bound is intrinsic. Our theoretical results also highlight a notion of "relative uncertainty", which characterizes the necessary and sufficient condition for achieving sample efficiency in offline MGs. To the best of our knowledge, we provide the first nearly minimax optimal result for offline MGs with function approximation.
Achieving Minimax Rates in Pool-Based Batch Active Learning
Feb 11, 2022We consider a batch active learning scenario where the learner adaptively issues batches of points to a labeling oracle. Sampling labels in batches is highly desirable in practice due to the smaller number of interactive rounds with the labeling oracle (often human beings). However, batch active learning typically pays the price of a reduced adaptivity, leading to suboptimal results. In this paper we propose a solution which requires a careful trade off between the informativeness of the queried points and their diversity. We theoretically investigate batch active learning in the practically relevant scenario where the unlabeled pool of data is available beforehand (pool-based active learning). We analyze a novel stage-wise greedy algorithm and show that, as a function of the label complexity, the excess risk of this algorithm operating in the realizable setting for which we prove matches the known minimax rates in standard statistical learning settings. Our results also exhibit a mild dependence on the batch size. These are the first theoretical results that employ careful trade offs between informativeness and diversity to rigorously quantify the statistical performance of batch active learning in the pool-based scenario.
Minimax Regret Optimization for Robust Machine Learning under Distribution Shift
Feb 11, 2022In this paper, we consider learning scenarios where the learned model is evaluated under an unknown test distribution which potentially differs from the training distribution (i.e. distribution shift). The learner has access to a family of weight functions such that the test distribution is a reweighting of the training distribution under one of these functions, a setting typically studied under the name of Distributionally Robust Optimization (DRO). We consider the problem of deriving regret bounds in the classical learning theory setting, and require that the resulting regret bounds hold uniformly for all potential test distributions. We show that the DRO formulation does not guarantee uniformly small regret under distribution shift. We instead propose an alternative method called Minimax Regret Optimization (MRO), and show that under suitable conditions this method achieves uniformly low regret across all test distributions. We also adapt our technique to have stronger guarantees when the test distributions are heterogeneous in their similarity to the training data. Given the widespead optimization of worst case risks in current approaches to robust machine learning, we believe that MRO can be a strong alternative to address distribution shift scenarios.
Secure Rate-Splitting for the MIMO Broadcast Channel with Imperfect CSIT and a Jammer
Jan 23, 2022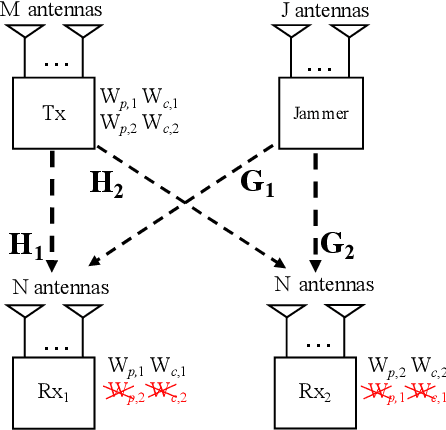
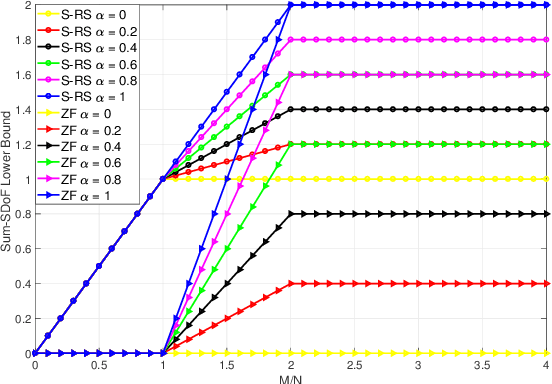
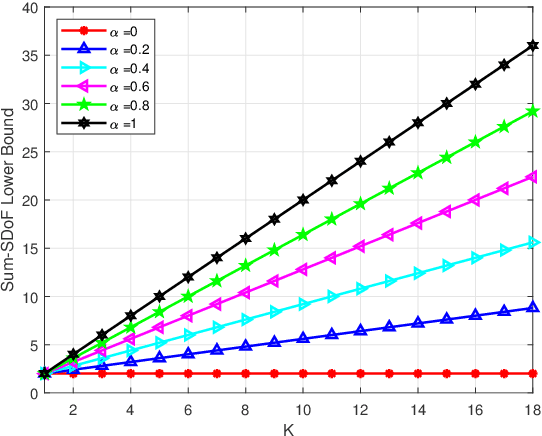
In this paper, we investigate the secure rate-splitting for the two-user multiple-input multiple-output (MIMO) broadcast channel with imperfect channel state information at the transmitter (CSIT) and a multiple-antenna jammer, where each receiver has equal number of antennas and the jammer has perfect channel state information (CSI). Specifically, we design the secure rate-splitting multiple-access in this scenario, where the security of splitted private and common messages is ensured by precoder design with joint nulling and aligning the leakage information, regarding to different antenna configurations. As a result, we show that the sum-secure degrees-of-freedom (SDoF) achieved by secure rate-splitting outperforms that by conventional zero-forcing. Therefore, we validate the superiority of rate-splitting for the secure purpose in the two-user MIMO broadcast channel with imperfect CSIT and a jammer.
Black-box Prompt Learning for Pre-trained Language Models
Jan 21, 2022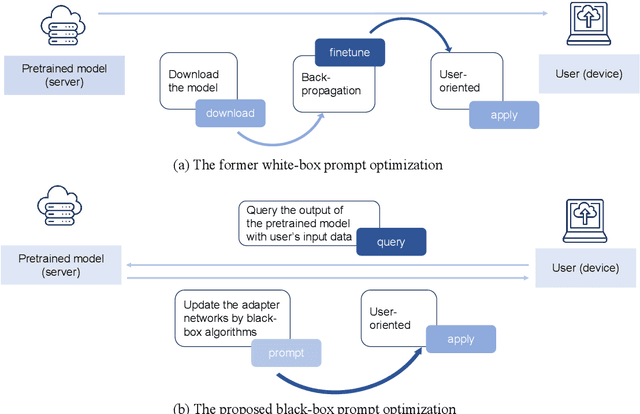
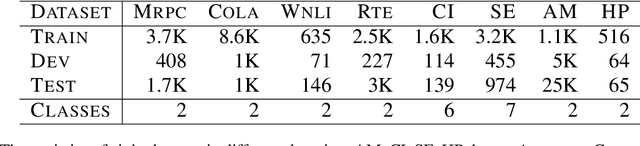
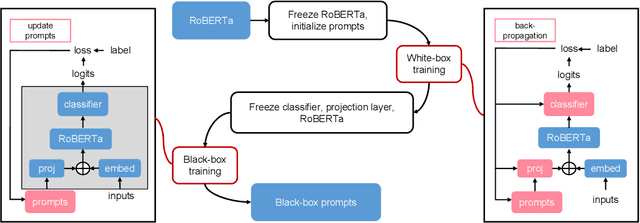
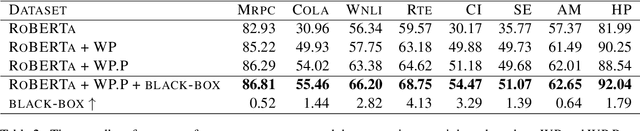
Domain-specific fine-tuning strategies for large pre-trained models received vast attention in recent years. In previously studied settings, the model architectures and parameters are tunable or at least visible, which we refer to as white-box settings. This work considers a new scenario, where we do not have access to a pre-trained model, except for its outputs given inputs, and we call this problem black-box fine-tuning. To illustrate our approach, we first introduce the black-box setting formally on text classification, where the pre-trained model is not only frozen but also invisible. We then propose our solution black-box prompt, a new technique in the prompt-learning family, which can leverage the knowledge learned by pre-trained models from the pre-training corpus. Our experiments demonstrate that the proposed method achieved the state-of-the-art performance on eight datasets. Further analyses on different human-designed objectives, prompt lengths, and intuitive explanations demonstrate the robustness and flexibility of our method.
A Novel Multi-Task Learning Method for Symbolic Music Emotion Recognition
Jan 15, 2022


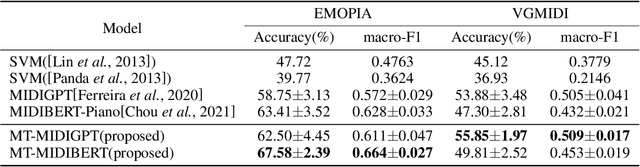
Symbolic Music Emotion Recognition(SMER) is to predict music emotion from symbolic data, such as MIDI and MusicXML. Previous work mainly focused on learning better representation via (mask) language model pre-training but ignored the intrinsic structure of the music, which is extremely important to the emotional expression of music. In this paper, we present a simple multi-task framework for SMER, which incorporates the emotion recognition task with other emotion-related auxiliary tasks derived from the intrinsic structure of the music. The results show that our multi-task framework can be adapted to different models. Moreover, the labels of auxiliary tasks are easy to be obtained, which means our multi-task methods do not require manually annotated labels other than emotion. Conducting on two publicly available datasets (EMOPIA and VGMIDI), the experiments show that our methods perform better in SMER task. Specifically, accuracy has been increased by 4.17 absolute point to 67.58 in EMOPIA dataset, and 1.97 absolute point to 55.85 in VGMIDI dataset. Ablation studies also show the effectiveness of multi-task methods designed in this paper.