 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Set Functions Under the Optimal Subset Oracle via Equivariant Variational Inference
Mar 03, 2022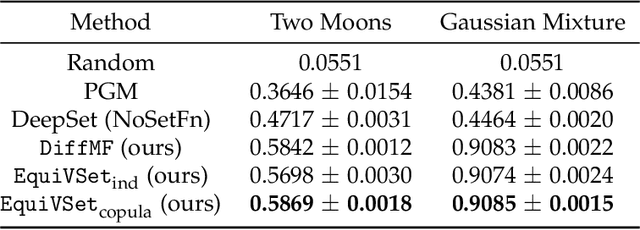
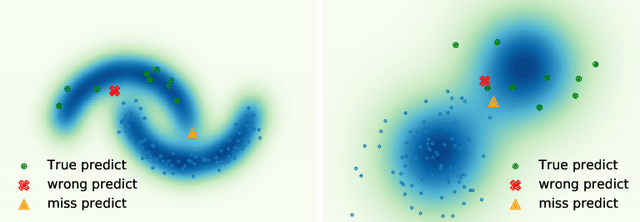
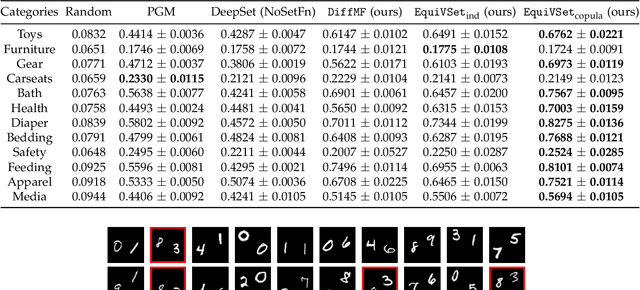

Learning set functions becomes increasingly more important in many applications like product recommendation and compound selection in AI-aided drug discovery. The majority of existing works study methodologies of set function learning under the function value oracle, which, however, requires expensive supervision signals. This renders it impractical for applications with only weak supervisions under the Optimal Subset (OS) oracle, the study of which is surprisingly overlooked. In this work, we present a principled yet practical maximum likelihood learning framework, termed as EquiVSet, that simultaneously meets the following desiderata of learning set functions under the OS oracle: i) permutation invariance of the set mass function being modeled; ii) permission of varying ground set; iii) fully differentiability; iv) minimum prior; and v) scalability. The main components of our framework involve: an energy-based treatment of the set mass function, DeepSet-style architectures to handle permutation invariance, mean-field variational inference, and its amortized variants. Although the framework is embarrassingly simple, empirical studies on three real-world applications (including Amazon product recommendation, set anomaly detection and compound selection for virtual screening) demonstrate that EquiVSet outperforms the baselines by a large margin.
Geometrically Equivariant Graph Neural Networks: A Survey
Feb 22, 2022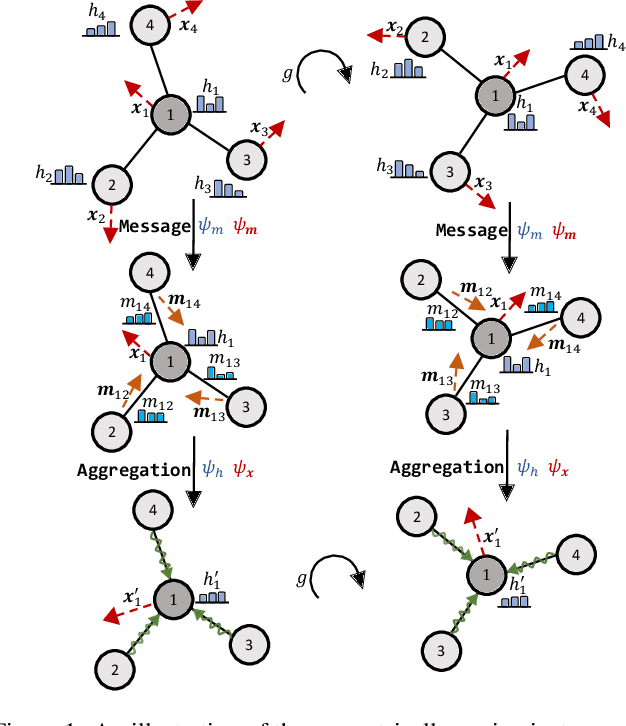
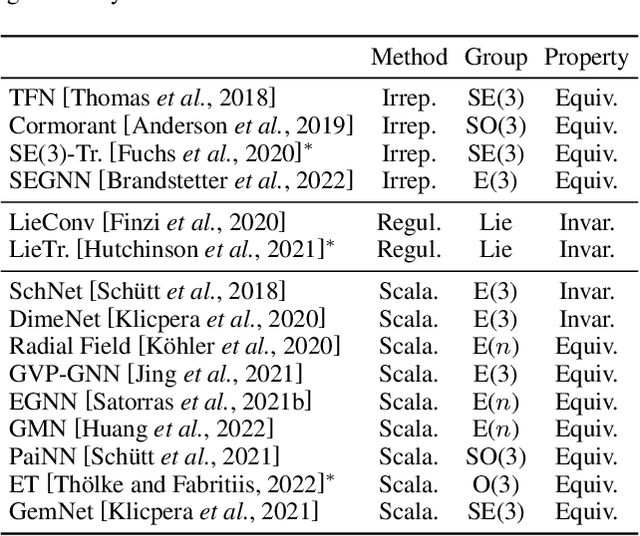
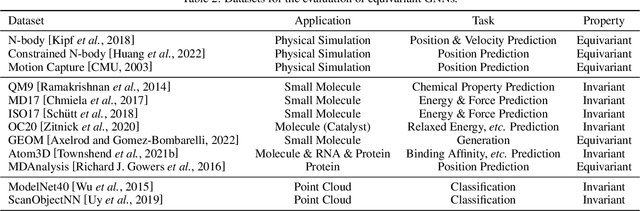
Many scientific problems require to process data in the form of geometric graphs. Unlike generic graph data, geometric graphs exhibit symmetries of translations, rotations, and/or reflections. Researchers have leveraged such inductive bias and developed geometrically equivariant Graph Neural Networks (GNNs) to better characterize the geometry and topology of geometric graphs. Despite fruitful achievements, it still lacks a survey to depict how equivariant GNNs are progressed, which in turn hinders the further development of equivariant GNNs. To this end, based on the necessary but concise mathematical preliminaries, we analyze and classify existing methods into three groups regarding how the message passing and aggregation in GNNs are represented. We also summarize the benchmarks as well as the related datasets to facilitate later researches for methodology development and experimental evaluation. The prospect for future potential directions is also provided.
Equivariant Graph Hierarchy-Based Neural Networks
Feb 22, 2022

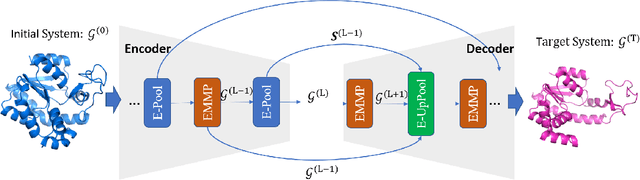
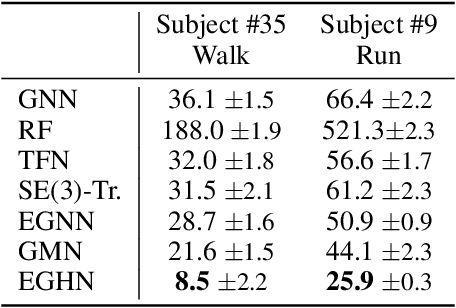
Equivariant Graph neural Networks (EGNs) are powerful in characterizing the dynamics of multi-body physical systems. Existing EGNs conduct flat message passing, which, yet, is unable to capture the spatial/dynamical hierarchy for complex systems particularly, limiting substructure discovery and global information fusion. In this paper, we propose Equivariant Hierarchy-based Graph Networks (EGHNs) which consist of the three key components: generalized Equivariant Matrix Message Passing (EMMP) , E-Pool and E-UpPool. In particular, EMMP is able to improve the expressivity of conventional equivariant message passing, E-Pool assigns the quantities of the low-level nodes into high-level clusters, while E-UpPool leverages the high-level information to update the dynamics of the low-level nodes. As their names imply, both E-Pool and E-UpPool are guaranteed to be equivariant to meet physic symmetry. Considerable experimental evaluations verify the effectiveness of our EGHN on several applications including multi-object dynamics simulation, motion capture, and protein dynamics modeling.
Transformer for Graphs: An Overview from Architecture Perspective
Feb 17, 2022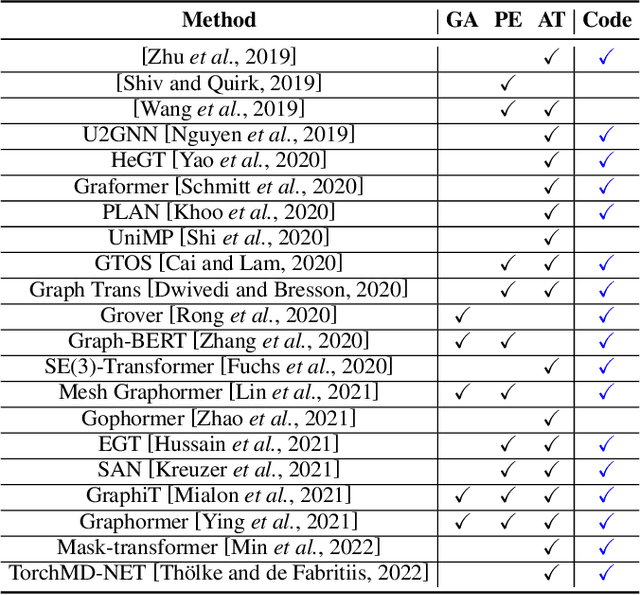
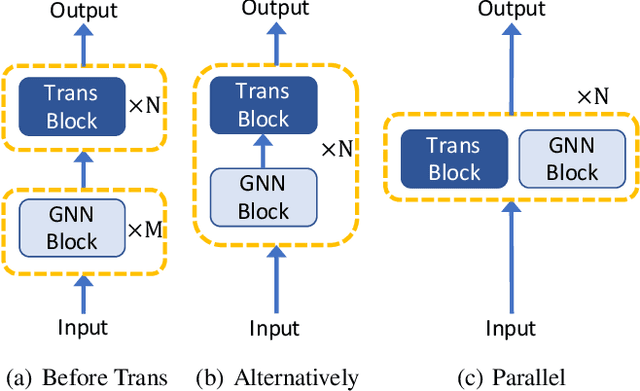
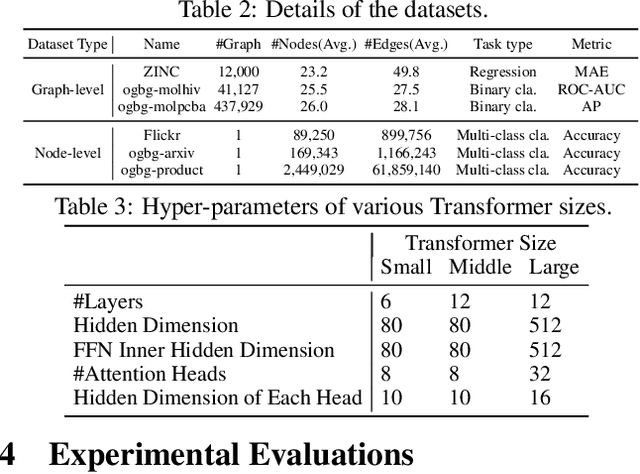
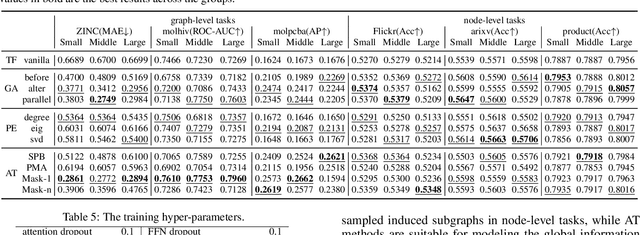
Recently, Transformer model, which has achieved great success in many artificial intelligence fields, has demonstrated its great potential in modeling graph-structured data. Till now, a great variety of Transformers has been proposed to adapt to the graph-structured data. However, a comprehensive literature review and systematical evaluation of these Transformer variants for graphs are still unavailable. It's imperative to sort out the existing Transformer models for graphs and systematically investigate their effectiveness on various graph tasks. In this survey, we provide a comprehensive review of various Graph Transformer models from the architectural design perspective. We first disassemble the existing models and conclude three typical ways to incorporate the graph information into the vanilla Transformer: 1) GNNs as Auxiliary Modules, 2) Improved Positional Embedding from Graphs, and 3) Improved Attention Matrix from Graphs. Furthermore, we implement the representative components in three groups and conduct a comprehensive comparison on various kinds of famous graph data benchmarks to investigate the real performance gain of each component. Our experiments confirm the benefits of current graph-specific modules on Transformer and reveal their advantages on different kinds of graph tasks.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022
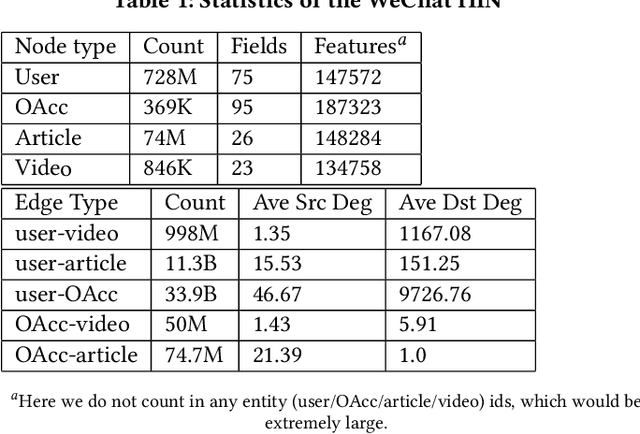
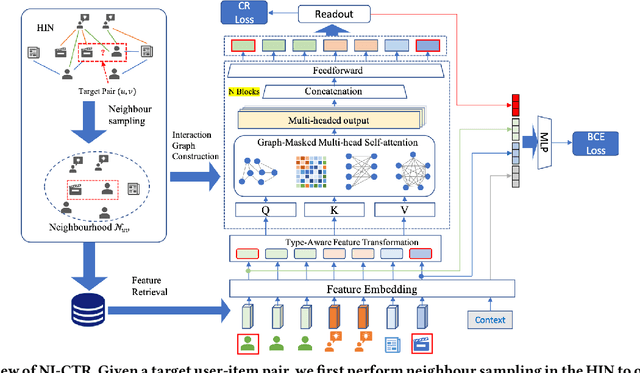
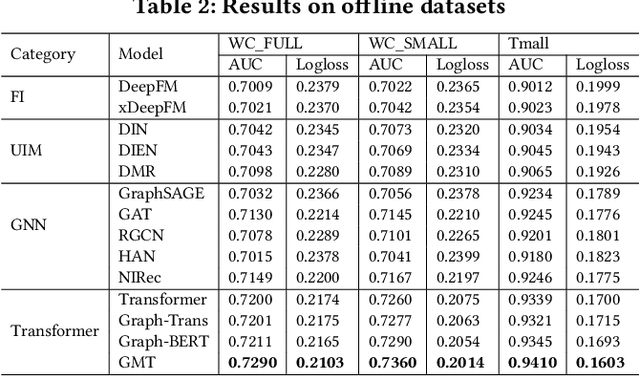
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022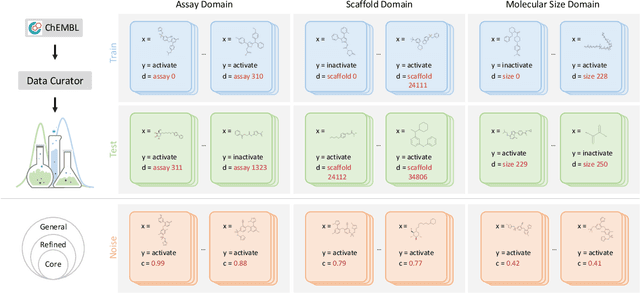

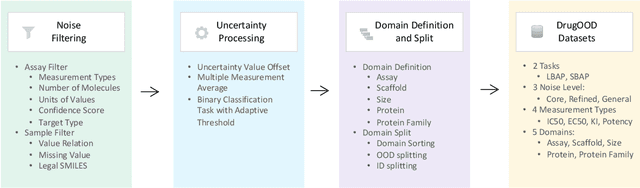
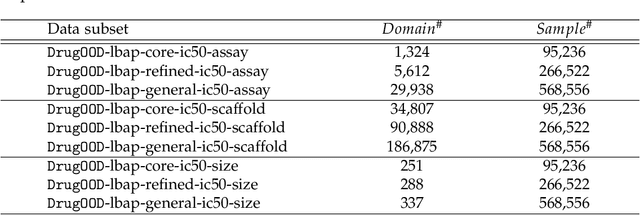
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
Towards the Explanation of Graph Neural Networks in Digital Pathology with Information Flows
Dec 18, 2021
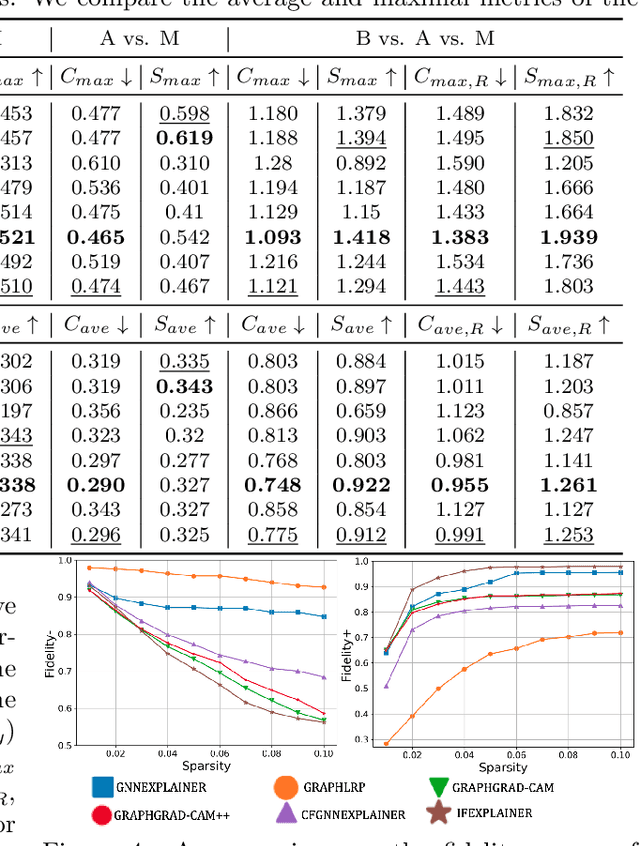

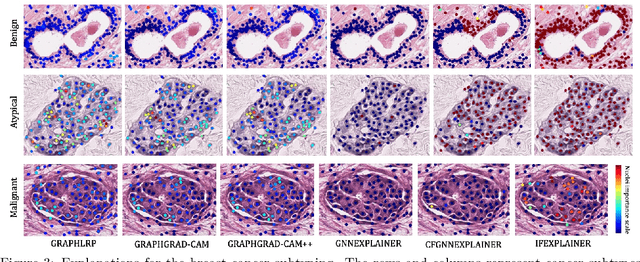
As Graph Neural Networks (GNNs) are widely adopted in digital pathology, there is increasing attention to developing explanation models (explainers) of GNNs for improved transparency in clinical decisions. Existing explainers discover an explanatory subgraph relevant to the prediction. However, such a subgraph is insufficient to reveal all the critical biological substructures for the prediction because the prediction will remain unchanged after removing that subgraph. Hence, an explanatory subgraph should be not only necessary for prediction, but also sufficient to uncover the most predictive regions for the explanation. Such explanation requires a measurement of information transferred from different input subgraphs to the predictive output, which we define as information flow. In this work, we address these key challenges and propose IFEXPLAINER, which generates a necessary and sufficient explanation for GNNs. To evaluate the information flow within GNN's prediction, we first propose a novel notion of predictiveness, named $f$-information, which is directional and incorporates the realistic capacity of the GNN model. Based on it, IFEXPLAINER generates the explanatory subgraph with maximal information flow to the prediction. Meanwhile, it minimizes the information flow from the input to the predictive result after removing the explanation. Thus, the produced explanation is necessarily important to the prediction and sufficient to reveal the most crucial substructures. We evaluate IFEXPLAINER to interpret GNN's predictions on breast cancer subtyping. Experimental results on the BRACS dataset show the superior performance of the proposed method.
Local Augmentation for Graph Neural Networks
Sep 08, 2021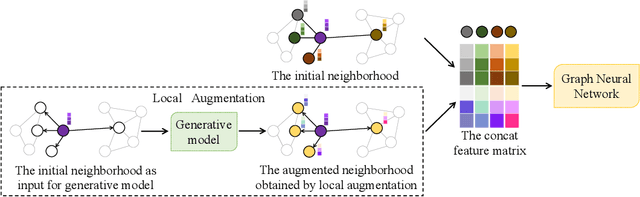
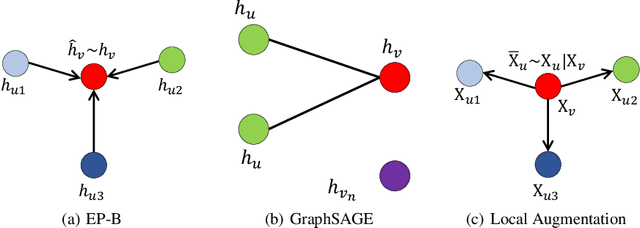

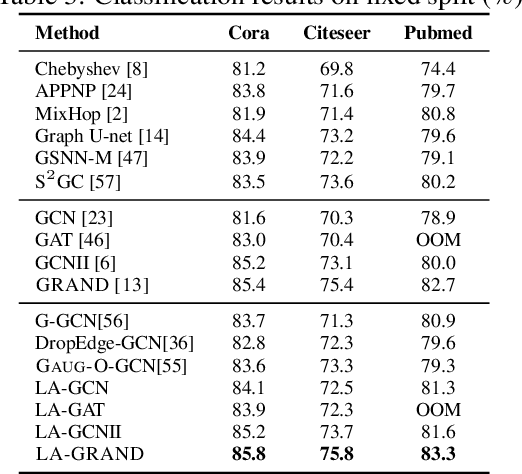
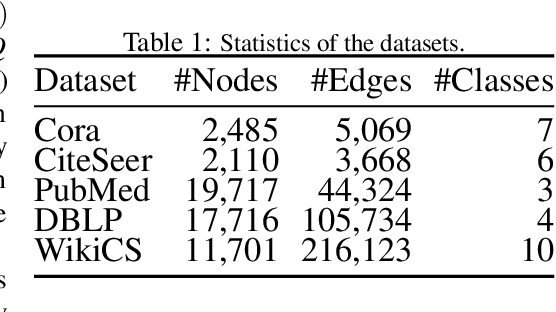
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
PI-GNN: A Novel Perspective on Semi-Supervised Node Classification against Noisy Labels
Jun 14, 2021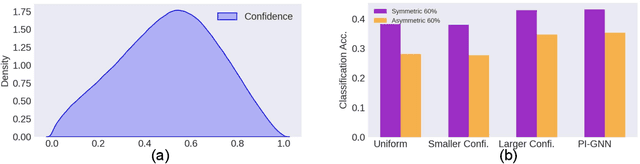
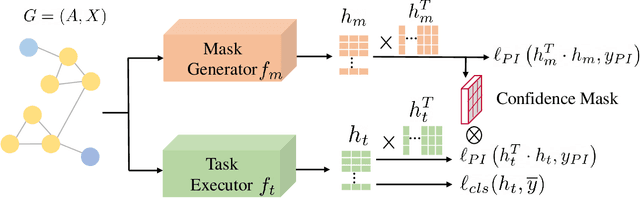
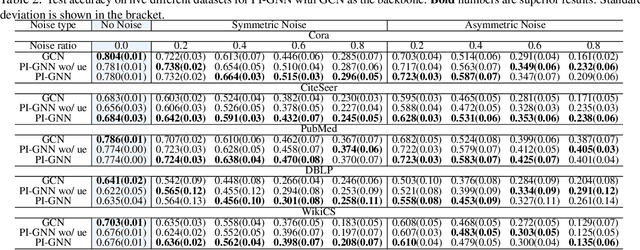
Semi-supervised node classification, as a fundamental problem in graph learning, leverages unlabeled nodes along with a small portion of labeled nodes for training. Existing methods rely heavily on high-quality labels, which, however, are expensive to obtain in real-world applications since certain noises are inevitably involved during the labeling process. It hence poses an unavoidable challenge for the learning algorithm to generalize well. In this paper, we propose a novel robust learning objective dubbed pairwise interactions (PI) for the model, such as Graph Neural Network (GNN) to combat noisy labels. Unlike classic robust training approaches that operate on the pointwise interactions between node and class label pairs, PI explicitly forces the embeddings for node pairs that hold a positive PI label to be close to each other, which can be applied to both labeled and unlabeled nodes. We design several instantiations for PI labels based on the graph structure and the node class labels, and further propose a new uncertainty-aware training technique to mitigate the negative effect of the sub-optimal PI labels. Extensive experiments on different datasets and GNN architectures demonstrate the effectiveness of PI, yielding a promising improvement over the state-of-the-art methods.
Energy-Based Learning for Cooperative Games, with Applications to Feature/Data/Model Valuations
Jun 05, 2021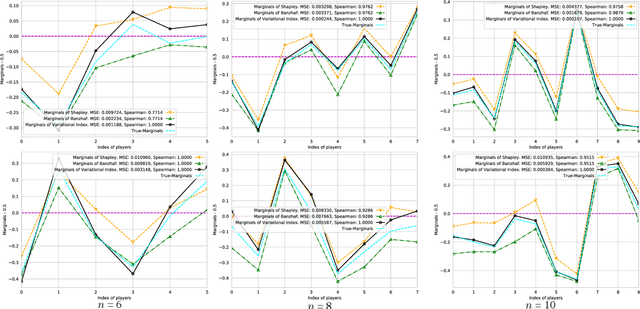
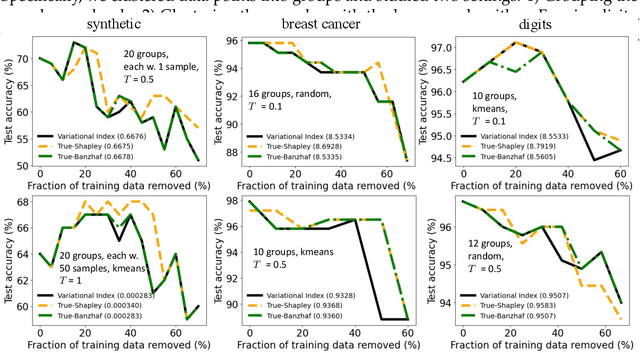
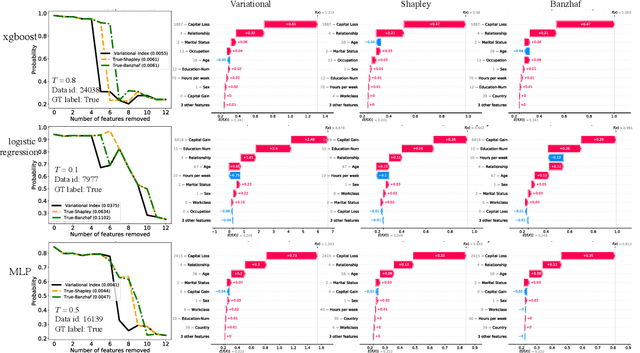
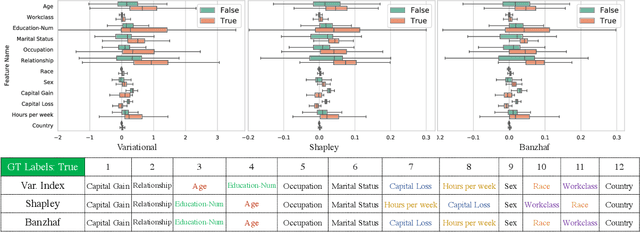
Valuation problems, such as attribution-based feature interpretation, data valuation and model valuation for ensembles, become increasingly more important in many machine learning applications. Such problems are commonly solved by well-known game-theoretic criteria, such as Shapley value or Banzhaf index. In this work, we present a novel energy-based treatment for cooperative games, with a theoretical justification by the maximum entropy framework. Surprisingly, by conducting variational inference of the energy-based model, we recover various game-theoretic valuation criteria, such as Shapley value and Banzhaf index, through conducting one-step gradient ascent for maximizing the mean-field ELBO objective. This observation also verifies the rationality of existing criteria, as they are all trying to decouple the correlations among the players through the mean-field approach. By running gradient ascent for multiple steps, we achieve a trajectory of the valuations, among which we define the valuation with the best conceivable decoupling error as the Variational Index. We experimentally demonstrate that the proposed Variational Index enjoys intriguing properties on certain synthetic and real-world valuation problems.