 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecFed: Accelerating Federated LLM Inference with Speculative Decoding and Compressed Transmission
Apr 28, 2026Federated inference enhances LLM performance in edge computing through weighted averaging of distributed model predictions. However, autoregressive LLM inference requires frequent full-model forward passes across workers, severely limiting decoding throughput. Distributed deployment further aggravates this due to a communication bottleneck: each worker must transmit full token probability distributions per draft token, dominating end-to-end latency. To address these challenges, we introduce speculative decoding to enable parallel LLM processing and propose a top-K compressed transmission scheme with two server-side reconstruction strategies. We theoretically analyze the robustness of our method in terms of local reconstruction error, aggregation bias, and acceptance-rate bias, and derive corresponding bounds. Experiments demonstrate that our scheme achieves high generation fidelity while significantly reducing communication overhead.
From Specialist to Large Models: A Paradigm Evolution Towards Semantic-Aware MIMO
Feb 25, 2026The sixth generation (6G) network is expected to deploy larger multiple-input multiple-output (MIMO) arrays to support massive connectivity, which will increase overhead and latency at the physical layer. Meanwhile, emerging 6G demands such as immersive communications and environmental sensing pose challenges to traditional signal processing. To address these issues, we propose the ``semantic-aware MIMO'' paradigm, which leverages specialist models and large models to perceive, utilize, and fuse the inherent semantics of channels and sources for improved performance. Moreover, for representative MIMO physical-layer tasks, e.g., random access activity detection, channel feedback, and precoding, we design specialist models that exploit channel and source semantics for better performance. Additionally, in view of the more diversified functions of 6G MIMO, we further explore large models as a scalable solution for multi-task semantic-aware MIMO and review recent advances along with their advantages and limitations. Finally, we discuss the challenges, insights, and prospects of the evolution of specialist models and large models empowered semantic-aware MIMO paradigms.
Wireless Channel Foundation Model with Embedded Noise-Plus-Interference Suppression Structure
Sep 19, 2025Wireless channel foundation model (WCFM) is a task-agnostic AI model that is pretrained on large-scale wireless channel datasets to learn a universal channel feature representation that can be used for a wide range of downstream tasks related to communications and sensing. While existing works on WCFM have demonstrated its great potentials in various tasks including beam prediction, channel prediction, localization, etc, the models are all trained using perfect (i.e., error-free and complete) channel information state (CSI) data which are generated with simulation tools. However, in practical systems where the WCFM is deployed, perfect CSI is not available. Instead, channel estimation needs to be first performed based on pilot signals over a subset of the resource elements (REs) to acquire a noisy version of the CSI (termed as degraded CSI), which significantly differs from the perfect CSI in some real-world environments with severe noise and interference. As a result, the feature representation generated by the WCFM is unable to reflect the characteristics of the true channel, yielding performance degradation in downstream tasks. To address this issue, in this paper we propose an enhanced wireless channel foundation model architecture with noise-plus-interference (NPI) suppression capability. In our approach, coarse estimates of the CSIs are first obtained. With these information, two projection matrices are computed to extract the NPI terms in the received signals, which are further processed by a NPI estimation and subtraction module. Finally, the resultant signal is passed through a CSI completion network to get a clean version of the CSI, which is used for feature extraction. Simulation results demonstrated that compared to the state-of-the-art solutions, WCFM with NPI suppression structure achieves improved performance on channel prediction task.
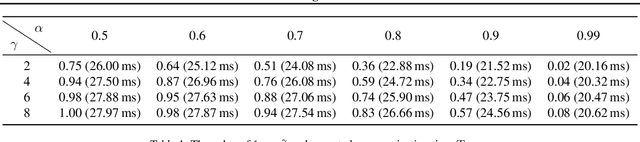
Communication-Efficient Collaborative LLM Inference via Distributed Speculative Decoding
Sep 04, 2025



Speculative decoding is an emerging technique that accelerates large language model (LLM) inference by allowing a smaller draft model to predict multiple tokens in advance, which are then verified or corrected by a larger target model. In AI-native radio access networks (AI-RAN), this paradigm is well-suited for collaborative inference between resource-constrained end devices and more capable edge servers or base stations (BSs). However, existing distributed speculative decoding requires transmitting the full vocabulary probability distribution from the draft model on the device to the target model at the BS, which leads to prohibitive uplink communication overhead. To address this issue, we propose a ``Top-K Sparse Logits Transmission (TK-SLT)`` scheme, where the draft model transmits only the top-K token raw probabilities and the corresponding token indices instead of the entire distribution. This approach significantly reduces bandwidth consumption while maintaining inference performance. We further derive an analytical expression for the optimal draft length that maximizes inference throughput, and provide a theoretical analysis of the achievable speedup ratio under TK-SLT. Experimental results validate both the efficiency and effectiveness of the proposed method.
DSSD: Efficient Edge-Device Deployment and Collaborative Inference via Distributed Split Speculative Decoding
Jul 16, 2025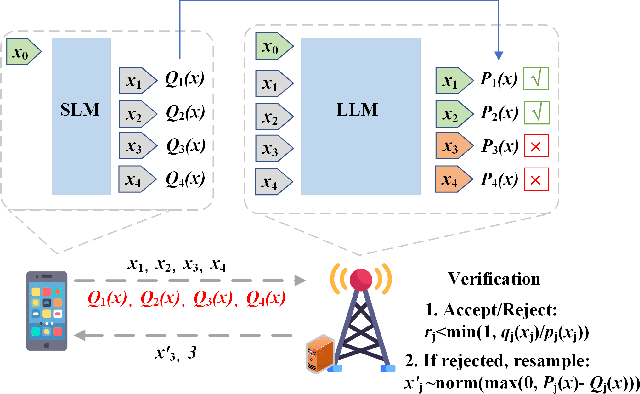
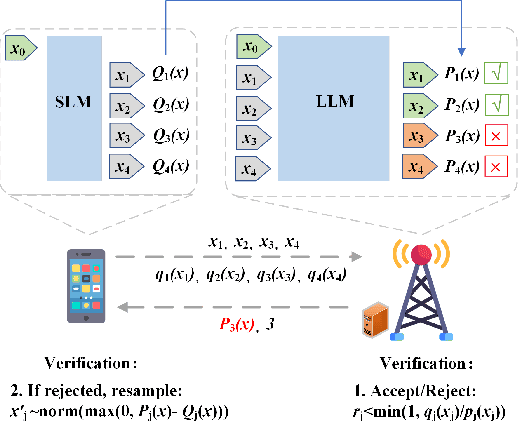
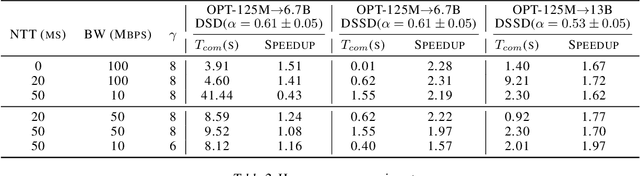
Large language models (LLMs) have transformed natural language processing but face critical deployment challenges in device-edge systems due to resource limitations and communication overhead. To address these issues, collaborative frameworks have emerged that combine small language models (SLMs) on devices with LLMs at the edge, using speculative decoding (SD) to improve efficiency. However, existing solutions often trade inference accuracy for latency or suffer from high uplink transmission costs when verifying candidate tokens. In this paper, we propose Distributed Split Speculative Decoding (DSSD), a novel architecture that not only preserves the SLM-LLM split but also partitions the verification phase between the device and edge. In this way, DSSD replaces the uplink transmission of multiple vocabulary distributions with a single downlink transmission, significantly reducing communication latency while maintaining inference quality. Experiments show that our solution outperforms current methods, and codes are at: https://github.com/JasonNing96/DSSD-Efficient-Edge-Computing
Wireless Large AI Model: Shaping the AI-Native Future of 6G and Beyond
Apr 20, 2025The emergence of sixth-generation and beyond communication systems is expected to fundamentally transform digital experiences through introducing unparalleled levels of intelligence, efficiency, and connectivity. A promising technology poised to enable this revolutionary vision is the wireless large AI model (WLAM), characterized by its exceptional capabilities in data processing, inference, and decision-making. In light of these remarkable capabilities, this paper provides a comprehensive survey of WLAM, elucidating its fundamental principles, diverse applications, critical challenges, and future research opportunities. We begin by introducing the background of WLAM and analyzing the key synergies with wireless networks, emphasizing the mutual benefits. Subsequently, we explore the foundational characteristics of WLAM, delving into their unique relevance in wireless environments. Then, the role of WLAM in optimizing wireless communication systems across various use cases and the reciprocal benefits are systematically investigated. Furthermore, we discuss the integration of WLAM with emerging technologies, highlighting their potential to enable transformative capabilities and breakthroughs in wireless communication. Finally, we thoroughly examine the high-level challenges hindering the practical implementation of WLAM and discuss pivotal future research directions.
EdgePrompt: A Distributed Key-Value Inference Framework for LLMs in 6G Networks
Apr 16, 2025As sixth-generation (6G) networks advance, large language models (LLMs) are increasingly integrated into 6G infrastructure to enhance network management and intelligence. However, traditional LLMs architecture struggle to meet the stringent latency and security requirements of 6G, especially as the increasing in sequence length leads to greater task complexity. This paper proposes Edge-Prompt, a cloud-edge collaborative framework based on a hierarchical attention splicing mechanism. EdgePrompt employs distributed key-value (KV) pair optimization techniques to accelerate inference and adapt to network conditions. Additionally, to reduce the risk of data leakage, EdgePrompt incorporates a privacy preserving strategy by isolating sensitive information during processing. Experiments on public dataset show that EdgePrompt effectively improves the inference throughput and reduces the latency, which provides a reliable solution for LLMs deployment in 6G environments.
MergeQuant: Accurate 4-bit Static Quantization of Large Language Models by Channel-wise Calibration
Mar 07, 2025Quantization has been widely used to compress and accelerate inference of large language models (LLMs). Existing methods focus on exploring the per-token dynamic calibration to ensure both inference acceleration and model accuracy under 4-bit quantization. However, in autoregressive generation inference of long sequences, the overhead of repeated dynamic quantization and dequantization steps becomes considerably expensive. In this work, we propose MergeQuant, an accurate and efficient per-channel static quantization framework. MergeQuant integrates the per-channel quantization steps with the corresponding scalings and linear mappings through a Quantization Step Migration (QSM) method, thereby eliminating the quantization overheads before and after matrix multiplication. Furthermore, in view of the significant differences between the different channel ranges, we propose dimensional reconstruction and adaptive clipping to address the non-uniformity of quantization scale factors and redistribute the channel variations to the subsequent modules to balance the parameter distribution under QSM. Within the static quantization setting of W4A4, MergeQuant reduces the accuracy gap on zero-shot tasks compared to FP16 baseline to 1.3 points on Llama-2-70B model. On Llama-2-7B model, MergeQuant achieves up to 1.77x speedup in decoding, and up to 2.06x speedup in end-to-end compared to FP16 baseline.
WirelessGPT: A Generative Pre-trained Multi-task Learning Framework for Wireless Communication
Feb 08, 2025



This paper introduces WirelessGPT, a pioneering foundation model specifically designed for multi-task learning in wireless communication and sensing. Specifically, WirelessGPT leverages large-scale wireless channel datasets for unsupervised pretraining and extracting universal channel representations, which captures complex spatiotemporal dependencies. In fact,this task-agnostic design adapts WirelessGPT seamlessly to a wide range of downstream tasks, using a unified representation with minimal fine-tuning. By unifying communication and sensing functionalities, WirelessGPT addresses the limitations of task-specific models, offering a scalable and efficient solution for integrated sensing and communication (ISAC). With an initial parameter size of around 80 million, WirelessGPT demonstrates significant improvements over conventional methods and smaller AI models, reducing reliance on large-scale labeled data. As the first foundation model capable of supporting diverse tasks across different domains, WirelessGPT establishes a new benchmark, paving the way for future advancements in multi-task wireless systems.
TSBP: Improving Object Detection in Histology Images via Test-time Self-guided Bounding-box Propagation
Sep 25, 2024



A global threshold (e.g., 0.5) is often applied to determine which bounding boxes should be included in the final results for an object detection task. A higher threshold reduces false positives but may result in missing a significant portion of true positives. A lower threshold can increase detection recall but may also result in more false positives. Because of this, using a preset global threshold (e.g., 0.5) applied to all the bounding box candidates may lead to suboptimal solutions. In this paper, we propose a Test-time Self-guided Bounding-box Propagation (TSBP) method, leveraging Earth Mover's Distance (EMD) to enhance object detection in histology images. TSBP utilizes bounding boxes with high confidence to influence those with low confidence, leveraging visual similarities between them. This propagation mechanism enables bounding boxes to be selected in a controllable, explainable, and robust manner, which surpasses the effectiveness of using simple thresholds and uncertainty calibration methods. Importantly, TSBP does not necessitate additional labeled samples for model training or parameter estimation, unlike calibration methods. We conduct experiments on gland detection and cell detection tasks in histology images. The results show that our proposed TSBP significantly improves detection outcomes when working in conjunction with state-of-the-art deep learning-based detection networks. Compared to other methods such as uncertainty calibration, TSBP yields more robust and accurate object detection predictions while using no additional labeled samples. The code is available at https://github.com/jwhgdeu/TSBP.