 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecFed: Accelerating Federated LLM Inference with Speculative Decoding and Compressed Transmission
Apr 28, 2026Federated inference enhances LLM performance in edge computing through weighted averaging of distributed model predictions. However, autoregressive LLM inference requires frequent full-model forward passes across workers, severely limiting decoding throughput. Distributed deployment further aggravates this due to a communication bottleneck: each worker must transmit full token probability distributions per draft token, dominating end-to-end latency. To address these challenges, we introduce speculative decoding to enable parallel LLM processing and propose a top-K compressed transmission scheme with two server-side reconstruction strategies. We theoretically analyze the robustness of our method in terms of local reconstruction error, aggregation bias, and acceptance-rate bias, and derive corresponding bounds. Experiments demonstrate that our scheme achieves high generation fidelity while significantly reducing communication overhead.
DSSD: Efficient Edge-Device Deployment and Collaborative Inference via Distributed Split Speculative Decoding
Jul 16, 2025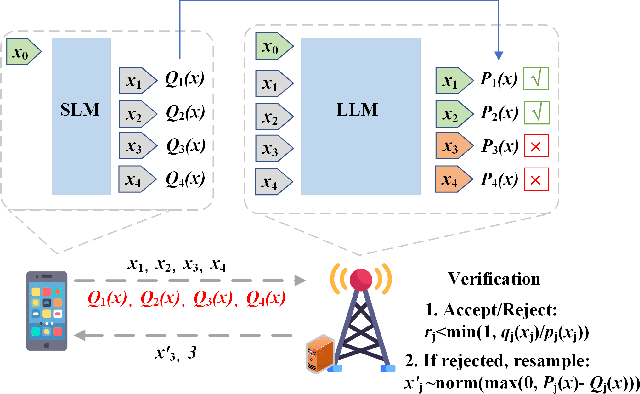
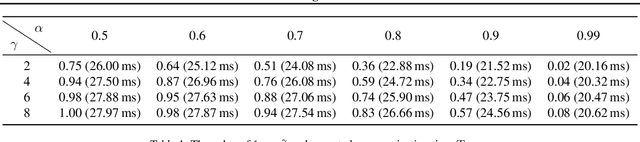
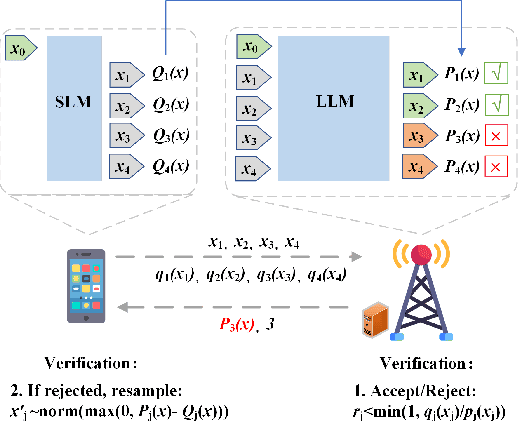
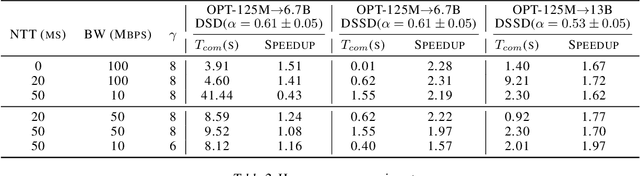
Large language models (LLMs) have transformed natural language processing but face critical deployment challenges in device-edge systems due to resource limitations and communication overhead. To address these issues, collaborative frameworks have emerged that combine small language models (SLMs) on devices with LLMs at the edge, using speculative decoding (SD) to improve efficiency. However, existing solutions often trade inference accuracy for latency or suffer from high uplink transmission costs when verifying candidate tokens. In this paper, we propose Distributed Split Speculative Decoding (DSSD), a novel architecture that not only preserves the SLM-LLM split but also partitions the verification phase between the device and edge. In this way, DSSD replaces the uplink transmission of multiple vocabulary distributions with a single downlink transmission, significantly reducing communication latency while maintaining inference quality. Experiments show that our solution outperforms current methods, and codes are at: https://github.com/JasonNing96/DSSD-Efficient-Edge-Computing
EdgePrompt: A Distributed Key-Value Inference Framework for LLMs in 6G Networks
Apr 16, 2025As sixth-generation (6G) networks advance, large language models (LLMs) are increasingly integrated into 6G infrastructure to enhance network management and intelligence. However, traditional LLMs architecture struggle to meet the stringent latency and security requirements of 6G, especially as the increasing in sequence length leads to greater task complexity. This paper proposes Edge-Prompt, a cloud-edge collaborative framework based on a hierarchical attention splicing mechanism. EdgePrompt employs distributed key-value (KV) pair optimization techniques to accelerate inference and adapt to network conditions. Additionally, to reduce the risk of data leakage, EdgePrompt incorporates a privacy preserving strategy by isolating sensitive information during processing. Experiments on public dataset show that EdgePrompt effectively improves the inference throughput and reduces the latency, which provides a reliable solution for LLMs deployment in 6G environments.