 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Visual Relationship Detection with Vision and Language Models
Mar 16, 2023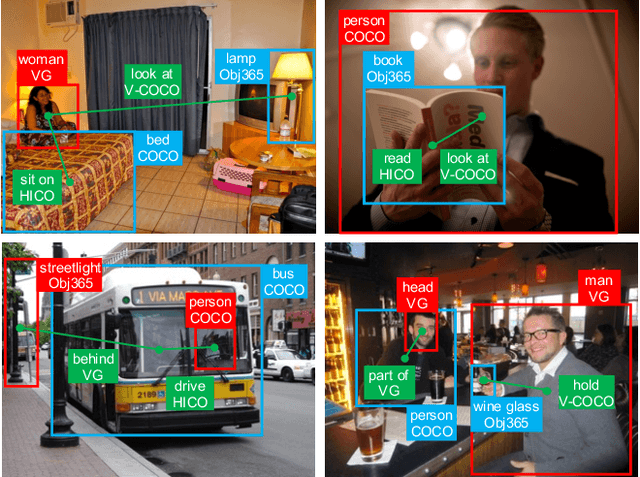
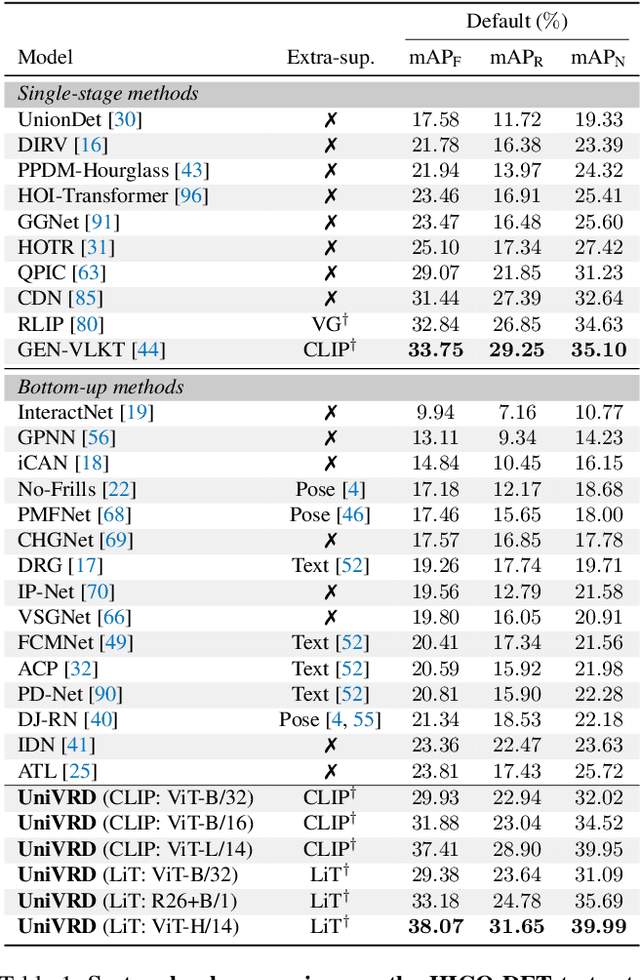
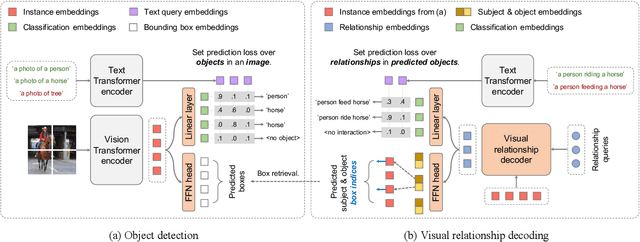
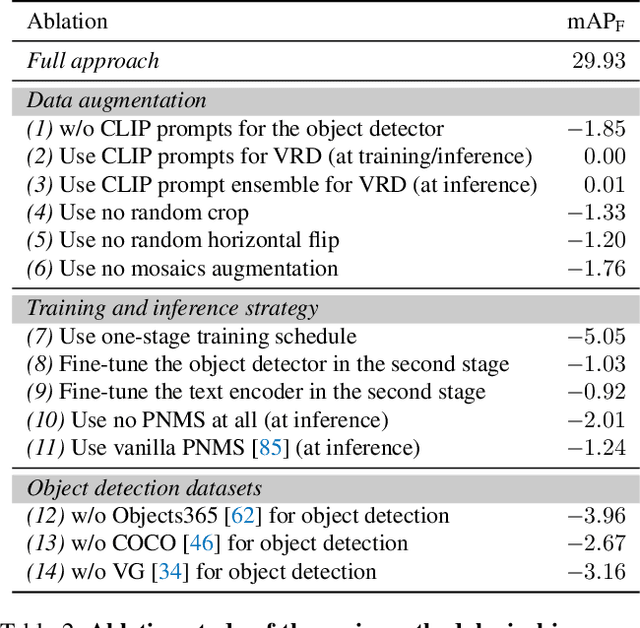
This work focuses on training a single visual relationship detector predicting over the union of label spaces from multiple datasets. Merging labels spanning different datasets could be challenging due to inconsistent taxonomies. The issue is exacerbated in visual relationship detection when second-order visual semantics are introduced between pairs of objects. To address this challenge, we propose UniVRD, a novel bottom-up method for Unified Visual Relationship Detection by leveraging vision and language models (VLMs). VLMs provide well-aligned image and text embeddings, where similar relationships are optimized to be close to each other for semantic unification. Our bottom-up design enables the model to enjoy the benefit of training with both object detection and visual relationship datasets. Empirical results on both human-object interaction detection and scene-graph generation demonstrate the competitive performance of our model. UniVRD achieves 38.07 mAP on HICO-DET, outperforming the current best bottom-up HOI detector by 60% relatively. More importantly, we show that our unified detector performs as well as dataset-specific models in mAP, and achieves further improvements when we scale up the model.
CluCDD:Contrastive Dialogue Disentanglement via Clustering
Feb 16, 2023A huge number of multi-participant dialogues happen online every day, which leads to difficulty in understanding the nature of dialogue dynamics for both humans and machines. Dialogue disentanglement aims at separating an entangled dialogue into detached sessions, thus increasing the readability of long disordered dialogue. Previous studies mainly focus on message-pair classification and clustering in two-step methods, which cannot guarantee the whole clustering performance in a dialogue. To address this challenge, we propose a simple yet effective model named CluCDD, which aggregates utterances by contrastive learning. More specifically, our model pulls utterances in the same session together and pushes away utterances in different ones. Then a clustering method is adopted to generate predicted clustering labels. Comprehensive experiments conducted on the Movie Dialogue dataset and IRC dataset demonstrate that our model achieves a new state-of-the-art result.
BDMMT: Backdoor Sample Detection for Language Models through Model Mutation Testing
Jan 25, 2023



Deep neural networks (DNNs) and natural language processing (NLP) systems have developed rapidly and have been widely used in various real-world fields. However, they have been shown to be vulnerable to backdoor attacks. Specifically, the adversary injects a backdoor into the model during the training phase, so that input samples with backdoor triggers are classified as the target class. Some attacks have achieved high attack success rates on the pre-trained language models (LMs), but there have yet to be effective defense methods. In this work, we propose a defense method based on deep model mutation testing. Our main justification is that backdoor samples are much more robust than clean samples if we impose random mutations on the LMs and that backdoors are generalizable. We first confirm the effectiveness of model mutation testing in detecting backdoor samples and select the most appropriate mutation operators. We then systematically defend against three extensively studied backdoor attack levels (i.e., char-level, word-level, and sentence-level) by detecting backdoor samples. We also make the first attempt to defend against the latest style-level backdoor attacks. We evaluate our approach on three benchmark datasets (i.e., IMDB, Yelp, and AG news) and three style transfer datasets (i.e., SST-2, Hate-speech, and AG news). The extensive experimental results demonstrate that our approach can detect backdoor samples more efficiently and accurately than the three state-of-the-art defense approaches.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022



Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.
LERT: A Linguistically-motivated Pre-trained Language Model
Nov 10, 2022Pre-trained Language Model (PLM) has become a representative foundation model in the natural language processing field. Most PLMs are trained with linguistic-agnostic pre-training tasks on the surface form of the text, such as the masked language model (MLM). To further empower the PLMs with richer linguistic features, in this paper, we aim to propose a simple but effective way to learn linguistic features for pre-trained language models. We propose LERT, a pre-trained language model that is trained on three types of linguistic features along with the original MLM pre-training task, using a linguistically-informed pre-training (LIP) strategy. We carried out extensive experiments on ten Chinese NLU tasks, and the experimental results show that LERT could bring significant improvements over various comparable baselines. Furthermore, we also conduct analytical experiments in various linguistic aspects, and the results prove that the design of LERT is valid and effective. Resources are available at https://github.com/ymcui/LERT
An Empirical Study on Clustering Pretrained Embeddings: Is Deep Strictly Better?
Nov 09, 2022Recent research in clustering face embeddings has found that unsupervised, shallow, heuristic-based methods -- including $k$-means and hierarchical agglomerative clustering -- underperform supervised, deep, inductive methods. While the reported improvements are indeed impressive, experiments are mostly limited to face datasets, where the clustered embeddings are highly discriminative or well-separated by class (Recall@1 above 90% and often nearing ceiling), and the experimental methodology seemingly favors the deep methods. We conduct a large-scale empirical study of 17 clustering methods across three datasets and obtain several robust findings. Notably, deep methods are surprisingly fragile for embeddings with more uncertainty, where they match or even perform worse than shallow, heuristic-based methods. When embeddings are highly discriminative, deep methods do outperform the baselines, consistent with past results, but the margin between methods is much smaller than previously reported. We believe our benchmarks broaden the scope of supervised clustering methods beyond the face domain and can serve as a foundation on which these methods could be improved. To enable reproducibility, we include all necessary details in the appendices, and plan to release the code.
MALUNet: A Multi-Attention and Light-weight UNet for Skin Lesion Segmentation
Nov 03, 2022Recently, some pioneering works have preferred applying more complex modules to improve segmentation performances. However, it is not friendly for actual clinical environments due to limited computing resources. To address this challenge, we propose a light-weight model to achieve competitive performances for skin lesion segmentation at the lowest cost of parameters and computational complexity so far. Briefly, we propose four modules: (1) DGA consists of dilated convolution and gated attention mechanisms to extract global and local feature information; (2) IEA, which is based on external attention to characterize the overall datasets and enhance the connection between samples; (3) CAB is composed of 1D convolution and fully connected layers to perform a global and local fusion of multi-stage features to generate attention maps at channel axis; (4) SAB, which operates on multi-stage features by a shared 2D convolution to generate attention maps at spatial axis. We combine four modules with our U-shape architecture and obtain a light-weight medical image segmentation model dubbed as MALUNet. Compared with UNet, our model improves the mIoU and DSC metrics by 2.39% and 1.49%, respectively, with a 44x and 166x reduction in the number of parameters and computational complexity. In addition, we conduct comparison experiments on two skin lesion segmentation datasets (ISIC2017 and ISIC2018). Experimental results show that our model achieves state-of-the-art in balancing the number of parameters, computational complexity and segmentation performances. Code is available at https://github.com/JCruan519/MALUNet.
Deep Multimodal Fusion for Generalizable Person Re-identification
Nov 02, 2022Person re-identification plays a significant role in realistic scenarios due to its various applications in public security and video surveillance. Recently, leveraging the supervised or semi-unsupervised learning paradigms, which benefits from the large-scale datasets and strong computing performance, has achieved a competitive performance on a specific target domain. However, when Re-ID models are directly deployed in a new domain without target samples, they always suffer from considerable performance degradation and poor domain generalization. To address this challenge, in this paper, we propose DMF, a Deep Multimodal Fusion network for the general scenarios on person re-identification task, where rich semantic knowledge is introduced to assist in feature representation learning during the pre-training stage. On top of it, a multimodal fusion strategy is introduced to translate the data of different modalities into the same feature space, which can significantly boost generalization capability of Re-ID model. In the fine-tuning stage, a realistic dataset is adopted to fine-tine the pre-trained model for distribution alignment with real-world. Comprehensive experiments on benchmarks demonstrate that our proposed method can significantly outperform previous domain generalization or meta-learning methods. Our source code will also be publicly available at https://github.com/JeremyXSC/DMF.
MEW-UNet: Multi-axis representation learning in frequency domain for medical image segmentation
Oct 25, 2022Recently, Visual Transformer (ViT) has been widely used in various fields of computer vision due to applying self-attention mechanism in the spatial domain to modeling global knowledge. Especially in medical image segmentation (MIS), many works are devoted to combining ViT and CNN, and even some works directly utilize pure ViT-based models. However, recent works improved models in the aspect of spatial domain while ignoring the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) for MIS based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input feature and assigns the external weight in the frequency domain, which is generated by our Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets and achieve state-of-the-art performances. In particular, on the Synapse dataset, our method outperforms MT-UNet by 10.15mm in terms of HD95. Code is available at https://github.com/JCruan519/MEW-UNet.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
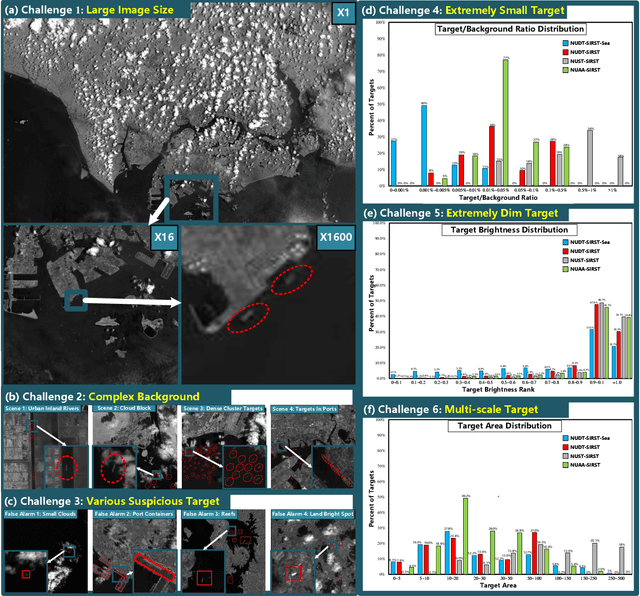
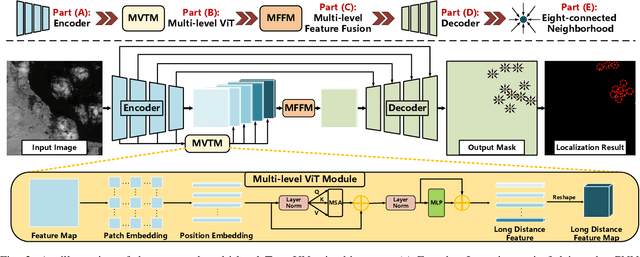
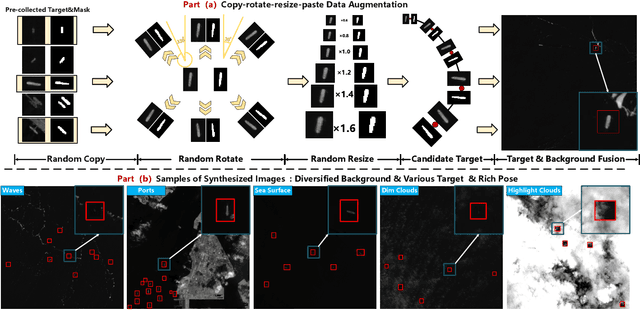
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.