 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Nested Transformers
May 26, 2021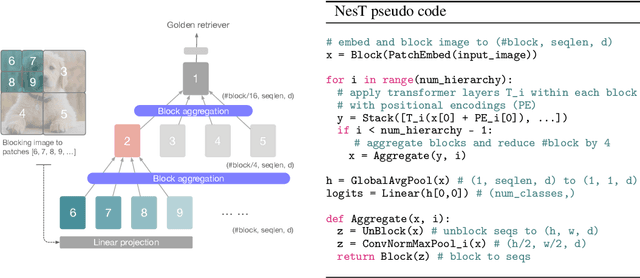
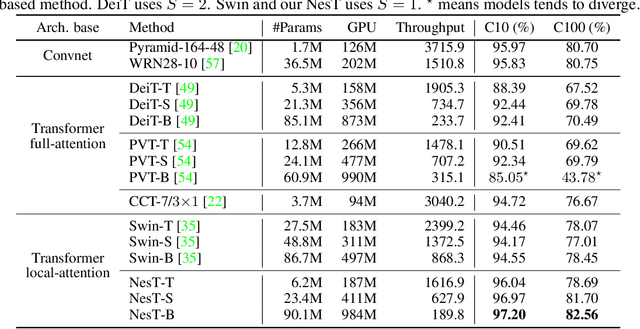
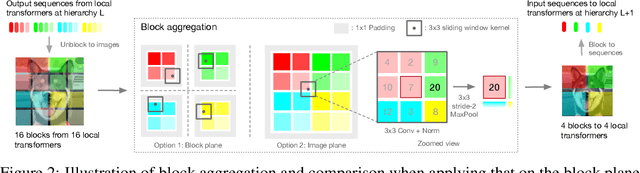
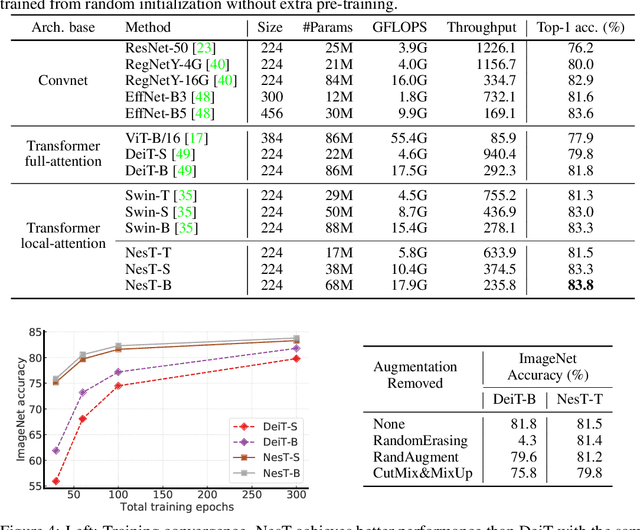
Although hierarchical structures are popular in recent vision transformers, they require sophisticated designs and massive datasets to work well. In this work, we explore the idea of nesting basic local transformers on non-overlapping image blocks and aggregating them in a hierarchical manner. We find that the block aggregation function plays a critical role in enabling cross-block non-local information communication. This observation leads us to design a simplified architecture with minor code changes upon the original vision transformer and obtains improved performance compared to existing methods. Our empirical results show that the proposed method NesT converges faster and requires much less training data to achieve good generalization. For example, a NesT with 68M parameters trained on ImageNet for 100/300 epochs achieves $82.3\%/83.8\%$ accuracy evaluated on $224\times 224$ image size, outperforming previous methods with up to $57\%$ parameter reduction. Training a NesT with 6M parameters from scratch on CIFAR10 achieves $96\%$ accuracy using a single GPU, setting a new state of the art for vision transformers. Beyond image classification, we extend the key idea to image generation and show NesT leads to a strong decoder that is 8$\times$ faster than previous transformer based generators. Furthermore, we also propose a novel method for visually interpreting the learned model.
Revisiting Hierarchical Approach for Persistent Long-Term Video Prediction
Apr 14, 2021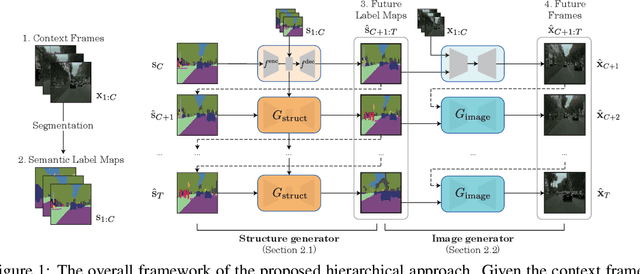
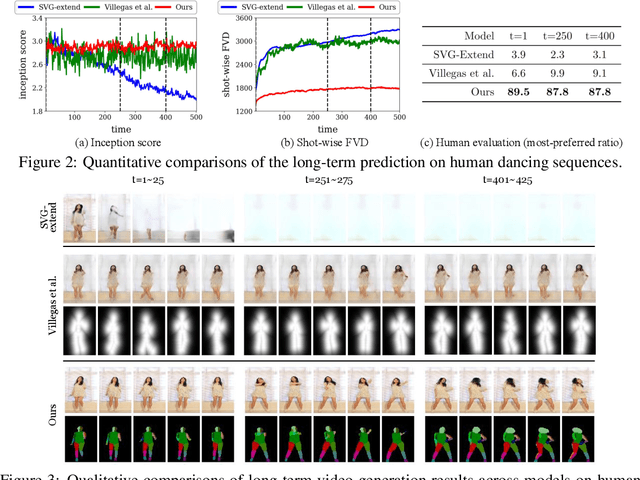
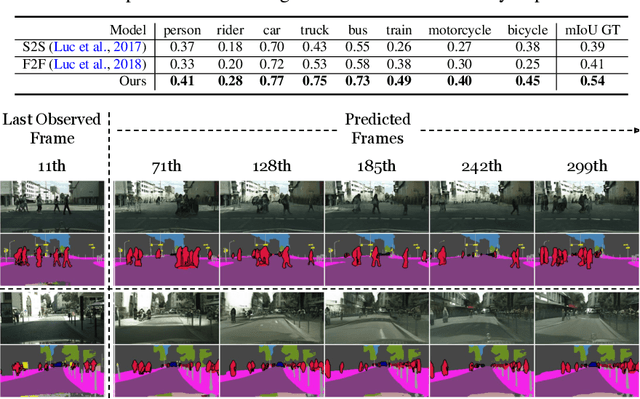
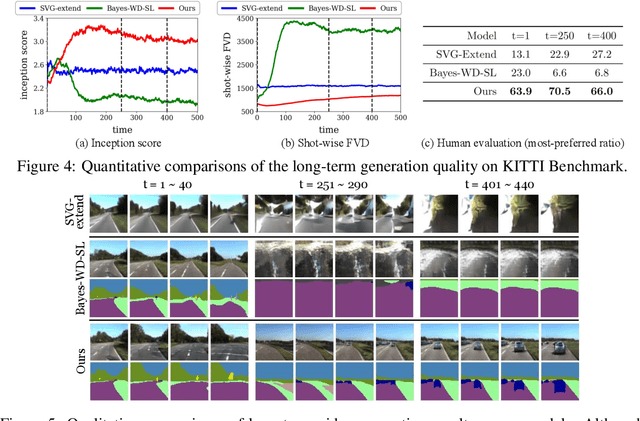
Learning to predict the long-term future of video frames is notoriously challenging due to inherent ambiguities in the distant future and dramatic amplifications of prediction error through time. Despite the recent advances in the literature, existing approaches are limited to moderately short-term prediction (less than a few seconds), while extrapolating it to a longer future quickly leads to destruction in structure and content. In this work, we revisit hierarchical models in video prediction. Our method predicts future frames by first estimating a sequence of semantic structures and subsequently translating the structures to pixels by video-to-video translation. Despite the simplicity, we show that modeling structures and their dynamics in the discrete semantic structure space with a stochastic recurrent estimator leads to surprisingly successful long-term prediction. We evaluate our method on three challenging datasets involving car driving and human dancing, and demonstrate that it can generate complicated scene structures and motions over a very long time horizon (i.e., thousands frames), setting a new standard of video prediction with orders of magnitude longer prediction time than existing approaches. Full videos and codes are available at https://1konny.github.io/HVP/.
Big Self-Supervised Models Advance Medical Image Classification
Jan 13, 2021
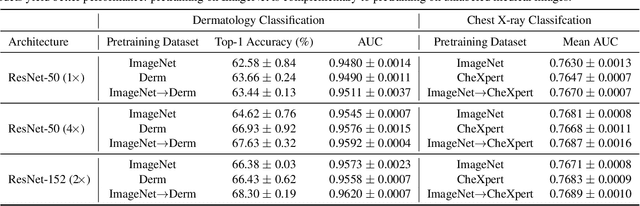
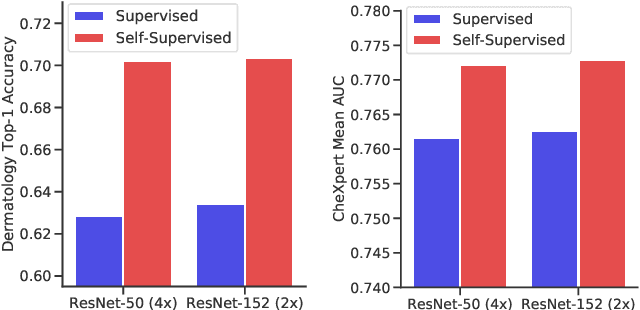
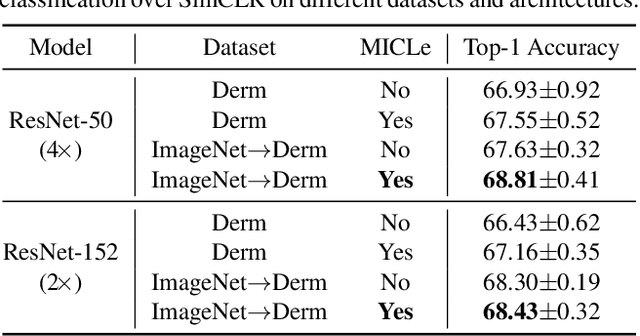
Self-supervised pretraining followed by supervised fine-tuning has seen success in image recognition, especially when labeled examples are scarce, but has received limited attention in medical image analysis. This paper studies the effectiveness of self-supervised learning as a pretraining strategy for medical image classification. We conduct experiments on two distinct tasks: dermatology skin condition classification from digital camera images and multi-label chest X-ray classification, and demonstrate that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images significantly improves the accuracy of medical image classifiers. We introduce a novel Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case, when available, to construct more informative positive pairs for self-supervised learning. Combining our contributions, we achieve an improvement of 6.7% in top-1 accuracy and an improvement of 1.1% in mean AUC on dermatology and chest X-ray classification respectively, outperforming strong supervised baselines pretrained on ImageNet. In addition, we show that big self-supervised models are robust to distribution shift and can learn efficiently with a small number of labeled medical images.
FIT: a Fast and Accurate Framework for Solving Medical Inquiring and Diagnosing Tasks
Dec 02, 2020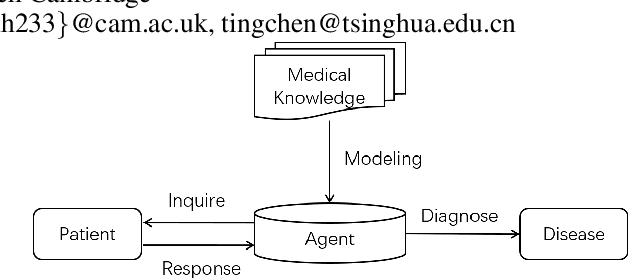

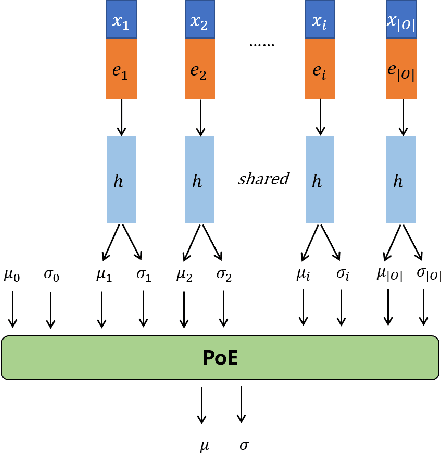

Automatic self-diagnosis provides low-cost and accessible healthcare via an agent that queries the patient and makes predictions about possible diseases. From a machine learning perspective, symptom-based self-diagnosis can be viewed as a sequential feature selection and classification problem. Reinforcement learning methods have shown good performance in this task but often suffer from large search spaces and costly training. To address these problems, we propose a competitive framework, called FIT, which uses an information-theoretic reward to determine what data to collect next. FIT improves over previous information-based approaches by using a multimodal variational autoencoder (MVAE) model and a two-step sampling strategy for disease prediction. Furthermore, we propose novel methods to substantially reduce the computational cost of FIT to a level that is acceptable for practical online self-diagnosis. Our results in two simulated datasets show that FIT can effectively deal with large search space problems, outperforming existing baselines. Moreover, using two medical datasets, we show that FIT is a competitive alternative in real-world settings.
Graph Contrastive Learning with Augmentations
Nov 11, 2020
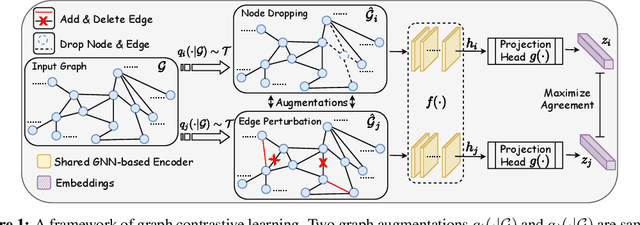

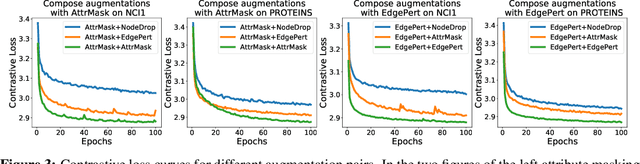
Generalizable, transferrable, and robust representation learning on graph-structured data remains a challenge for current graph neural networks (GNNs). Unlike what has been developed for convolutional neural networks (CNNs) for image data, self-supervised learning and pre-training are less explored for GNNs. In this paper, we propose a graph contrastive learning (GraphCL) framework for learning unsupervised representations of graph data. We first design four types of graph augmentations to incorporate various priors. We then systematically study the impact of various combinations of graph augmentations on multiple datasets, in four different settings: semi-supervised, unsupervised, and transfer learning as well as adversarial attacks. The results show that, even without tuning augmentation extents nor using sophisticated GNN architectures, our GraphCL framework can produce graph representations of similar or better generalizability, transferrability, and robustness compared to state-of-the-art methods. We also investigate the impact of parameterized graph augmentation extents and patterns, and observe further performance gains in preliminary experiments. Our codes are available at https://github.com/Shen-Lab/GraphCL.
Intriguing Properties of Contrastive Losses
Nov 05, 2020

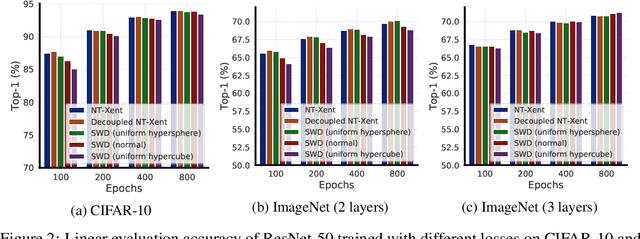
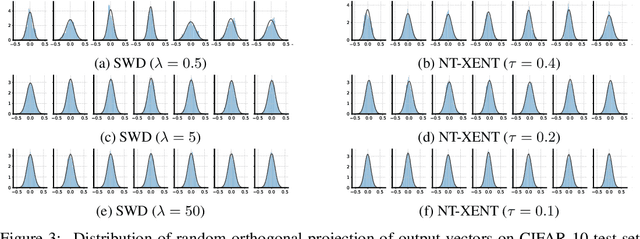
Contrastive loss and its variants have become very popular recently for learning visual representations without supervision. In this work, we first generalize the standard contrastive loss based on cross entropy to a broader family of losses that share an abstract form of $\mathcal{L}_{\text{alignment}} + \lambda \mathcal{L}_{\text{distribution}}$, where hidden representations are encouraged to (1) be aligned under some transformations/augmentations, and (2) match a prior distribution of high entropy. We show that various instantiations of the generalized loss perform similarly under the presence of a multi-layer non-linear projection head, and the temperature scaling ($\tau$) widely used in the standard contrastive loss is (within a range) inversely related to the weighting ($\lambda$) between the two loss terms. We then study an intriguing phenomenon of feature suppression among competing features shared acros augmented views, such as "color distribution" vs "object class". We construct datasets with explicit and controllable competing features, and show that, for contrastive learning, a few bits of easy-to-learn shared features could suppress, and even fully prevent, the learning of other sets of competing features. Interestingly, this characteristic is much less detrimental in autoencoders based on a reconstruction loss. Existing contrastive learning methods critically rely on data augmentation to favor certain sets of features than others, while one may wish that a network would learn all competing features as much as its capacity allows.
What's in a Loss Function for Image Classification?
Oct 30, 2020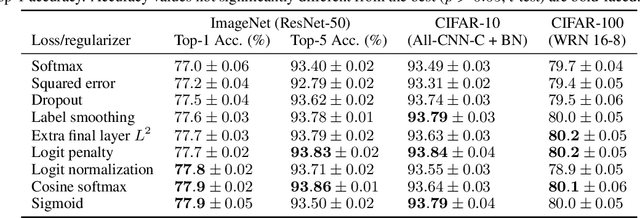
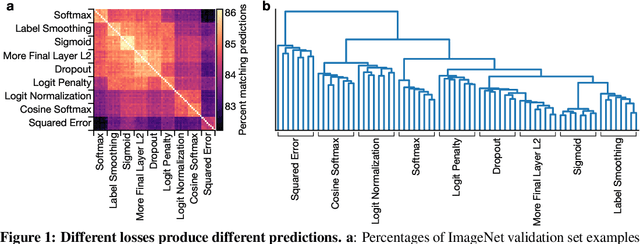
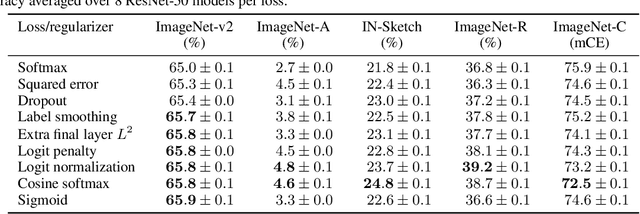
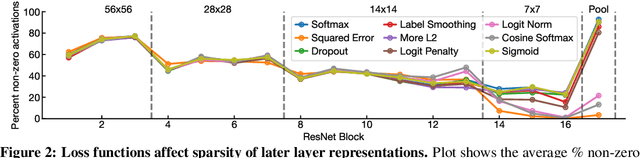
It is common to use the softmax cross-entropy loss to train neural networks on classification datasets where a single class label is assigned to each example. However, it has been shown that modifying softmax cross-entropy with label smoothing or regularizers such as dropout can lead to higher performance. This paper studies a variety of loss functions and output layer regularization strategies on image classification tasks. We observe meaningful differences in model predictions, accuracy, calibration, and out-of-distribution robustness for networks trained with different objectives. However, differences in hidden representations of networks trained with different objectives are restricted to the last few layers; representational similarity reveals no differences among network layers that are not close to the output. We show that all objectives that improve over vanilla softmax loss produce greater class separation in the penultimate layer of the network, which potentially accounts for improved performance on the original task, but results in features that transfer worse to other tasks.
Robust Pre-Training by Adversarial Contrastive Learning
Oct 26, 2020


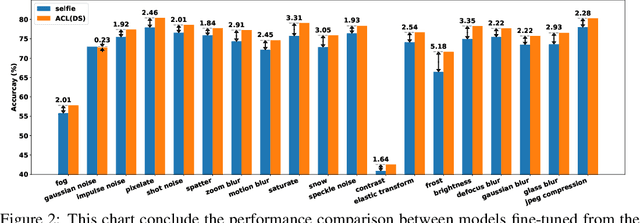
Recent work has shown that, when integrated with adversarial training, self-supervised pre-training can lead to state-of-the-art robustness In this work, we improve robustness-aware self-supervised pre-training by learning representations that are consistent under both data augmentations and adversarial perturbations. Our approach leverages a recent contrastive learning framework, which learns representations by maximizing feature consistency under differently augmented views. This fits particularly well with the goal of adversarial robustness, as one cause of adversarial fragility is the lack of feature invariance, i.e., small input perturbations can result in undesirable large changes in features or even predicted labels. We explore various options to formulate the contrastive task, and demonstrate that by injecting adversarial perturbations, contrastive pre-training can lead to models that are both label-efficient and robust. We empirically evaluate the proposed Adversarial Contrastive Learning (ACL) and show it can consistently outperform existing methods. For example on the CIFAR-10 dataset, ACL outperforms the previous state-of-the-art unsupervised robust pre-training approach by 2.99% on robust accuracy and 2.14% on standard accuracy. We further demonstrate that ACL pre-training can improve semi-supervised adversarial training, even when only a few labeled examples are available. Our codes and pre-trained models have been released at: https://github.com/VITA-Group/Adversarial-Contrastive-Learning.
Deep Hash Embedding for Large-Vocab Categorical Feature Representations
Oct 21, 2020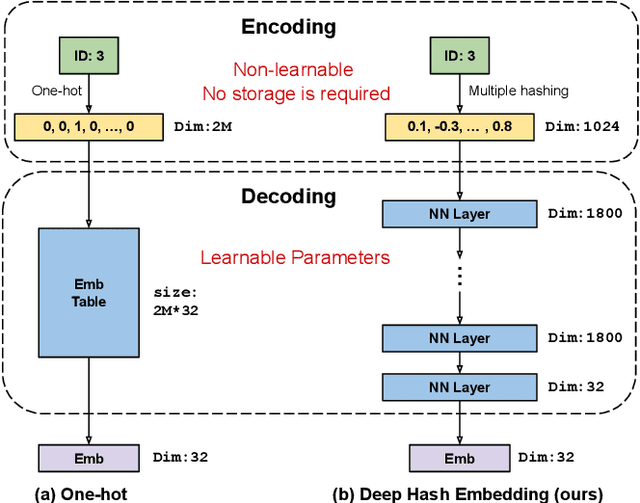

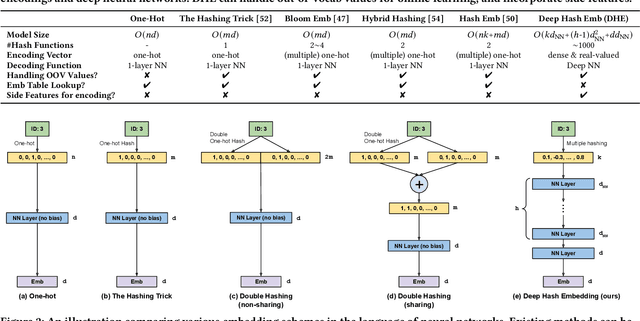
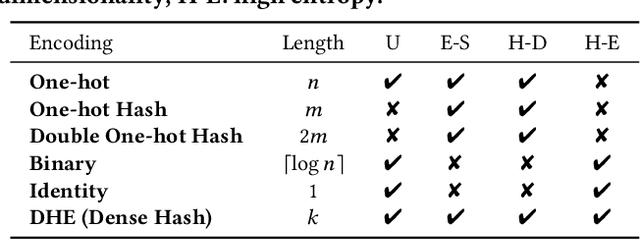
Embedding learning for large-vocabulary categorical features (e.g. user/item IDs, and words) is crucial for deep learning, and especially neural models for recommendation systems and natural language understanding tasks. Typically, the model creates a huge embedding table that each row represents a dedicated embedding vector for every feature value. In practice, to handle new (i.e., out-of-vocab) feature values and reduce the storage cost, the hashing trick is often adopted, that randomly maps feature values to a smaller number of hashing buckets. Essentially, thess embedding methods can be viewed as 1-layer wide neural networks with one-hot encodings. In this paper, we propose an alternative embedding framework Deep Hash Embedding (DHE), with non-one-hot encodings and a deep neural network (embedding network) to compute embeddings on the fly without having to store them. DHE first encodes the feature value to a dense vector with multiple hashing functions and then applies a DNN to generate the embedding. DHE is collision-free as the dense hashing encodings are unique identifiers for both in-vocab and out-of-vocab feature values. The encoding module is deterministic, non-learnable, and free of storage, while the embedding network is updated during the training time to memorize embedding information. Empirical results show that DHE outperforms state-of-the-art hashing-based embedding learning algorithms, and achieves comparable AUC against the standard one-hot encoding, with significantly smaller model sizes. Our work sheds light on design of DNN-based alternative embedding schemes for categorical features without using embedding table lookup.
Big Self-Supervised Models are Strong Semi-Supervised Learners
Jun 17, 2020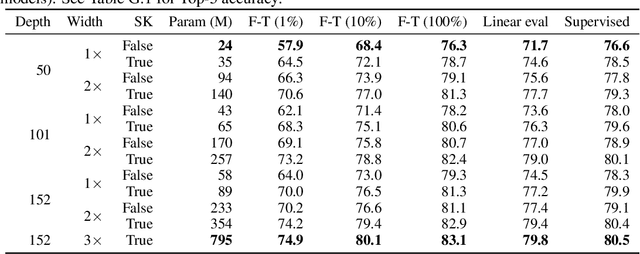
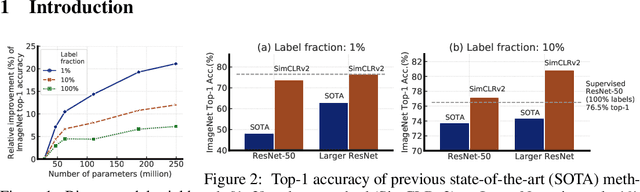
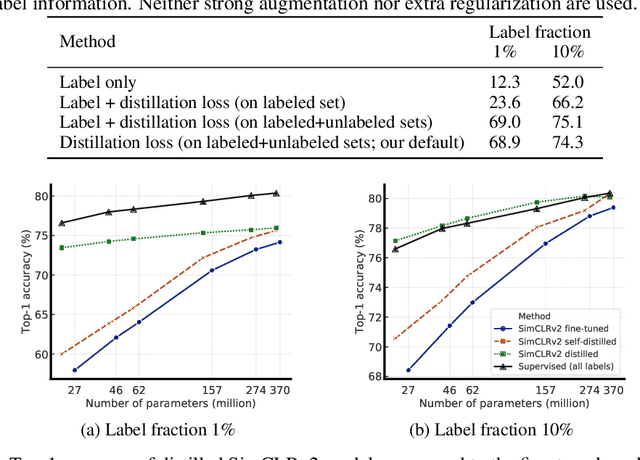
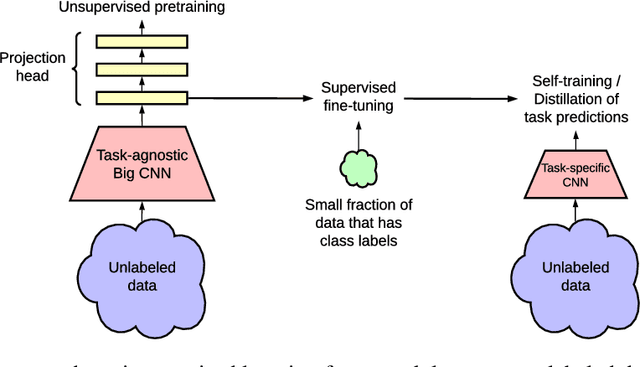
One paradigm for learning from few labeled examples while making best use of a large amount of unlabeled data is unsupervised pretraining followed by supervised fine-tuning. Although this paradigm uses unlabeled data in a task-agnostic way, in contrast to most previous approaches to semi-supervised learning for computer vision, we show that it is surprisingly effective for semi-supervised learning on ImageNet. A key ingredient of our approach is the use of a big (deep and wide) network during pretraining and fine-tuning. We find that, the fewer the labels, the more this approach (task-agnostic use of unlabeled data) benefits from a bigger network. After fine-tuning, the big network can be further improved and distilled into a much smaller one with little loss in classification accuracy by using the unlabeled examples for a second time, but in a task-specific way. The proposed semi-supervised learning algorithm can be summarized in three steps: unsupervised pretraining of a big ResNet model using SimCLRv2 (a modification of SimCLR), supervised fine-tuning on a few labeled examples, and distillation with unlabeled examples for refining and transferring the task-specific knowledge. This procedure achieves 73.9\% ImageNet top-1 accuracy with just 1\% of the labels ($\le$13 labeled images per class) using ResNet-50, a $10\times$ improvement in label efficiency over the previous state-of-the-art. With 10\% of labels, ResNet-50 trained with our method achieves 77.5\% top-1 accuracy, outperforming standard supervised training with all of the labels.