 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
Oct 18, 2021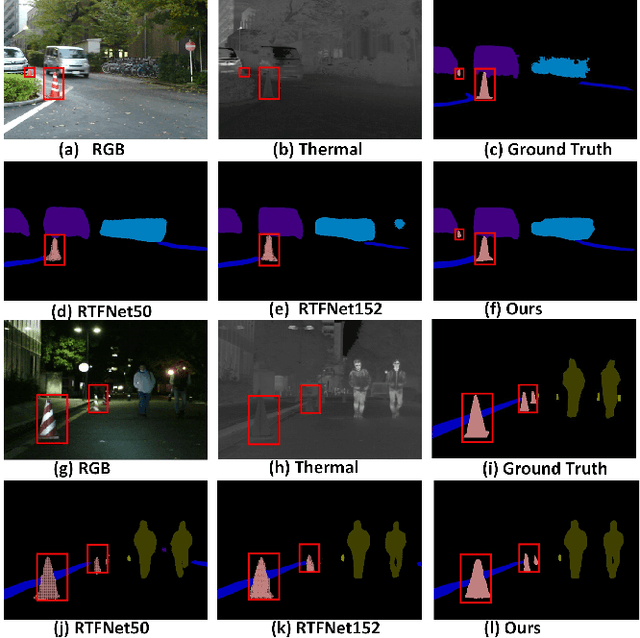
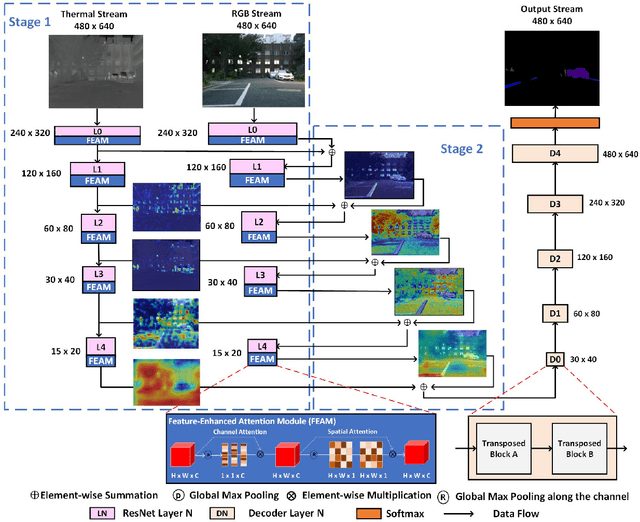
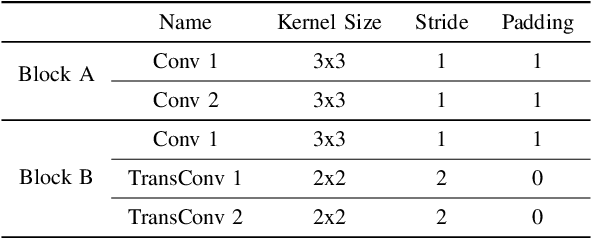
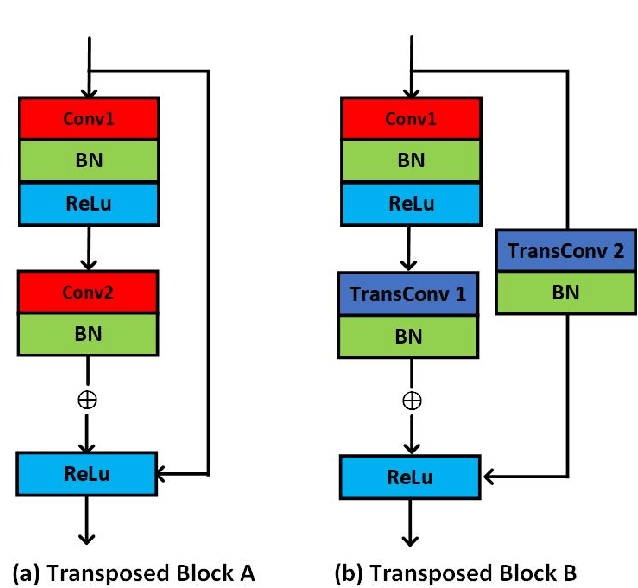
The RGB-Thermal (RGB-T) information for semantic segmentation has been extensively explored in recent years. However, most existing RGB-T semantic segmentation usually compromises spatial resolution to achieve real-time inference speed, which leads to poor performance. To better extract detail spatial information, we propose a two-stage Feature-Enhanced Attention Network (FEANet) for the RGB-T semantic segmentation task. Specifically, we introduce a Feature-Enhanced Attention Module (FEAM) to excavate and enhance multi-level features from both the channel and spatial views. Benefited from the proposed FEAM module, our FEANet can preserve the spatial information and shift more attention to high-resolution features from the fused RGB-T images. Extensive experiments on the urban scene dataset demonstrate that our FEANet outperforms other state-of-the-art (SOTA) RGB-T methods in terms of objective metrics and subjective visual comparison (+2.6% in global mAcc and +0.8% in global mIoU). For the 480 x 640 RGB-T test images, our FEANet can run with a real-time speed on an NVIDIA GeForce RTX 2080 Ti card.
AB-Mapper: Attention and BicNet Based Multi-agent Path Finding for Dynamic Crowded Environment
Oct 02, 2021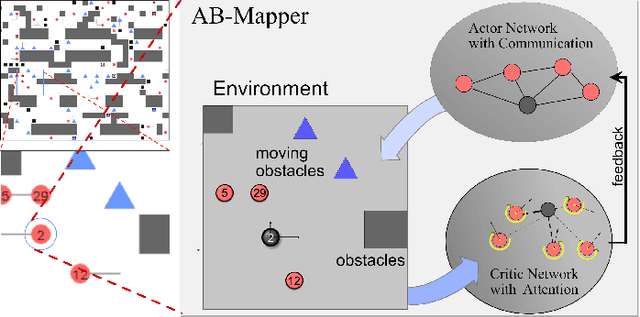
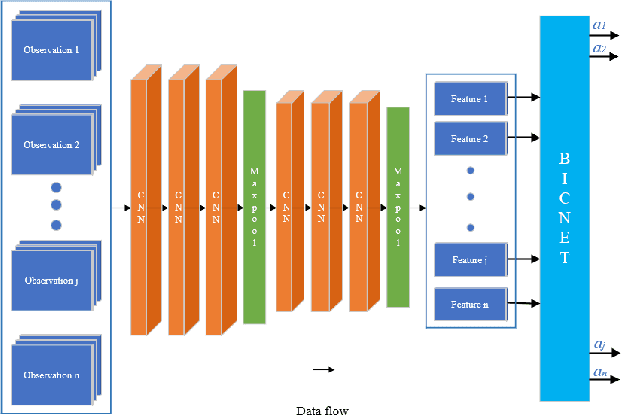
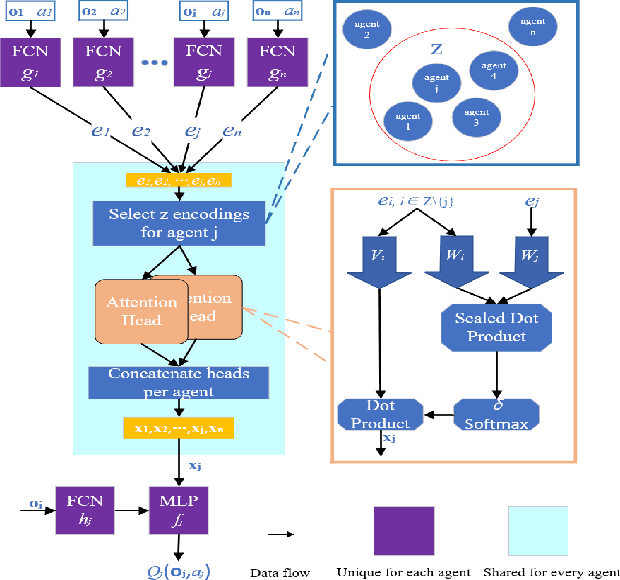
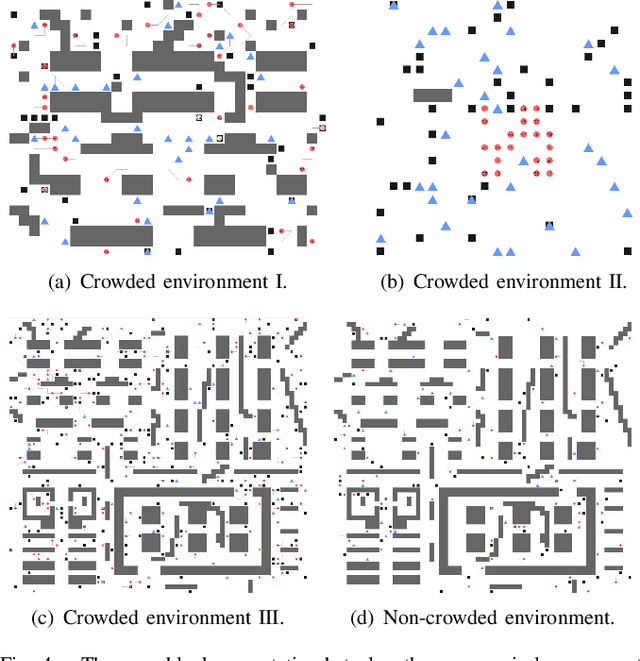
Multi-agent path finding in dynamic crowded environments is of great academic and practical value for multi-robot systems in the real world. To improve the effectiveness and efficiency of communication and learning process during path planning in dynamic crowded environments, we introduce an algorithm called Attention and BicNet based Multi-agent path planning with effective reinforcement (AB-Mapper)under the actor-critic reinforcement learning framework. In this framework, on the one hand, we utilize the BicNet with communication function in the actor-network to achieve intra team coordination. On the other hand, we propose a centralized critic network that can selectively allocate attention weights to surrounding agents. This attention mechanism allows an individual agent to automatically learn a better evaluation of actions by also considering the behaviours of its surrounding agents. Compared with the state-of-the-art method Mapper,our AB-Mapper is more effective (85.86% vs. 81.56% in terms of success rate) in solving the general path finding problems with dynamic obstacles. In addition, in crowded scenarios, our method outperforms the Mapper method by a large margin,reaching a stunning gap of more than 40% for each experiment.
Meta Reinforcement Learning Based Sensor Scanning in 3D Uncertain Environments for Heterogeneous Multi-Robot Systems
Sep 28, 2021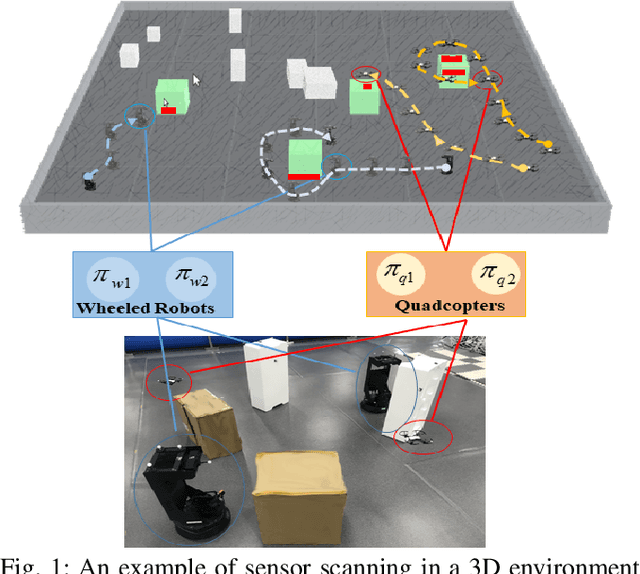
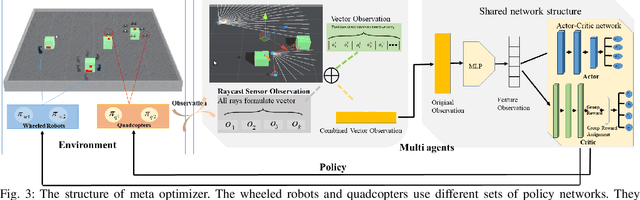
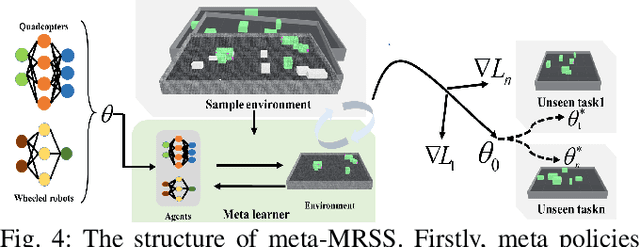
We study a novel problem that tackles learning based sensor scanning in 3D and uncertain environments with heterogeneous multi-robot systems. Our motivation is two-fold: first, 3D environments are complex, the use of heterogeneous multi-robot systems intuitively can facilitate sensor scanning by fully taking advantage of sensors with different capabilities. Second, in uncertain environments (e.g. rescue), time is of great significance. Since the learning process normally takes time to train and adapt to a new environment, we need to find an effective way to explore and adapt quickly. To this end, in this paper, we present a meta-learning approach to improve the exploration and adaptation capabilities. The experimental results demonstrate our method can outperform other methods by approximately 15%-27% on success rate and 70%-75% on adaptation speed.
View Blind-spot as Inpainting: Self-Supervised Denoising with Mask Guided Residual Convolution
Sep 10, 2021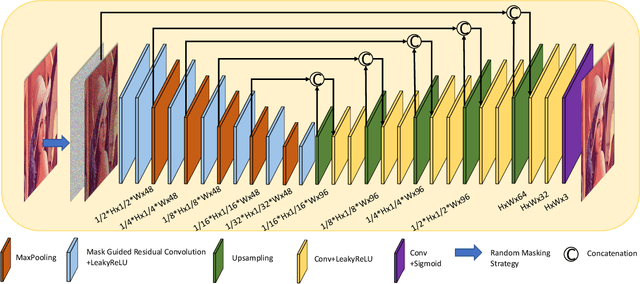
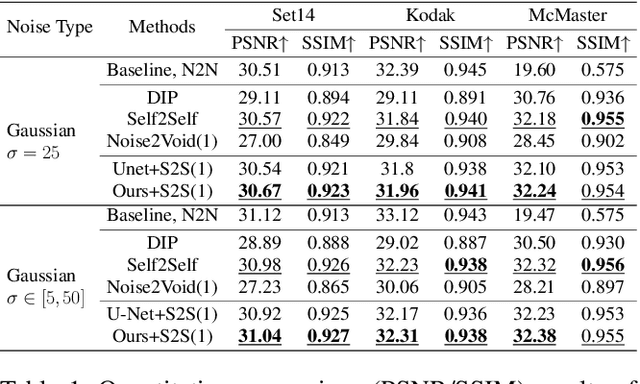
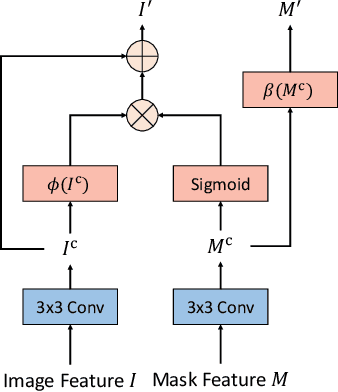
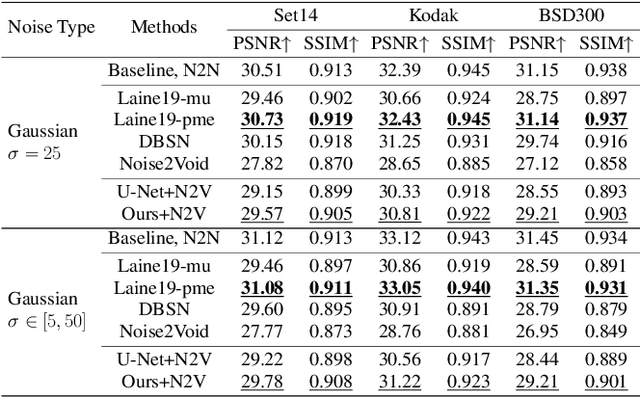
In recent years, self-supervised denoising methods have shown impressive performance, which circumvent painstaking collection procedure of noisy-clean image pairs in supervised denoising methods and boost denoising applicability in real world. One of well-known self-supervised denoising strategies is the blind-spot training scheme. However, a few works attempt to improve blind-spot based self-denoiser in the aspect of network architecture. In this paper, we take an intuitive view of blind-spot strategy and consider its process of using neighbor pixels to predict manipulated pixels as an inpainting process. Therefore, we propose a novel Mask Guided Residual Convolution (MGRConv) into common convolutional neural networks, e.g. U-Net, to promote blind-spot based denoising. Our MGRConv can be regarded as soft partial convolution and find a trade-off among partial convolution, learnable attention maps, and gated convolution. It enables dynamic mask learning with appropriate mask constrain. Different from partial convolution and gated convolution, it provides moderate freedom for network learning. It also avoids leveraging external learnable parameters for mask activation, unlike learnable attention maps. The experiments show that our proposed plug-and-play MGRConv can assist blind-spot based denoising network to reach promising results on both existing single-image based and dataset-based methods.
AgreementLearning: An End-to-End Framework for Learning with Multiple Annotators without Groundtruth
Sep 08, 2021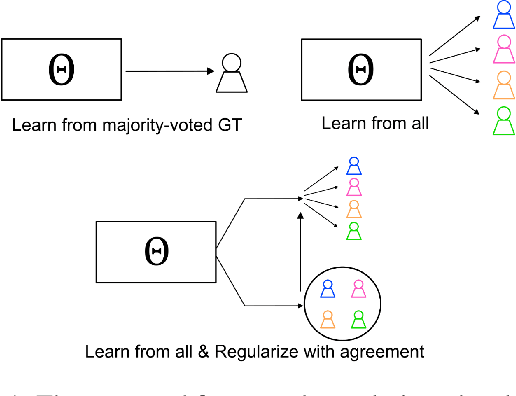
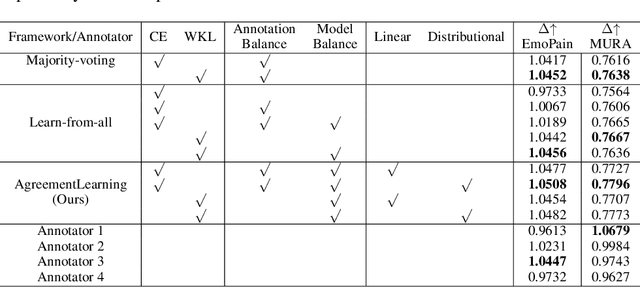
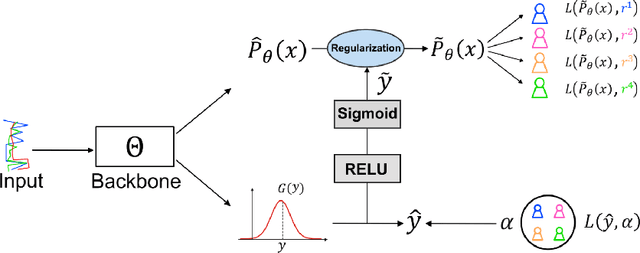
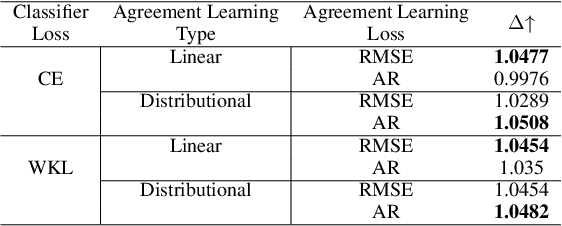
The annotation of domain experts is important for some medical applications where the objective groundtruth is ambiguous to define, e.g., the rehabilitation for some chronic diseases, and the prescreening of some musculoskeletal abnormalities without further medical examinations. However, improper uses of the annotations may hinder developing reliable models. On one hand, forcing the use of a single groundtruth generated from multiple annotations is less informative for the modeling. On the other hand, feeding the model with all the annotations without proper regularization is noisy given existing disagreements. For such issues, we propose a novel agreement learning framework to tackle the challenge of learning from multiple annotators without objective groundtruth. The framework has two streams, with one stream fitting with the multiple annotators and the other stream learning agreement information between the annotators. In particular, the agreement learning stream produces regularization information to the classifier stream, tuning its decision to be better in line with the agreement between the annotators. The proposed method can be easily plugged to existing backbones developed with majority-voted groundtruth or multiple annotations. Thereon, experiments on two medical datasets demonstrate improved agreement levels with annotators.
AcousticFusion: Fusing Sound Source Localization to Visual SLAM in Dynamic Environments
Aug 03, 2021



Dynamic objects in the environment, such as people and other agents, lead to challenges for existing simultaneous localization and mapping (SLAM) approaches. To deal with dynamic environments, computer vision researchers usually apply some learning-based object detectors to remove these dynamic objects. However, these object detectors are computationally too expensive for mobile robot on-board processing. In practical applications, these objects output noisy sounds that can be effectively detected by on-board sound source localization. The directional information of the sound source object can be efficiently obtained by direction of sound arrival (DoA) estimation, but depth estimation is difficult. Therefore, in this paper, we propose a novel audio-visual fusion approach that fuses sound source direction into the RGB-D image and thus removes the effect of dynamic obstacles on the multi-robot SLAM system. Experimental results of multi-robot SLAM in different dynamic environments show that the proposed method uses very small computational resources to obtain very stable self-localization results.
PoseFusion2: Simultaneous Background Reconstruction and Human Shape Recovery in Real-time
Aug 02, 2021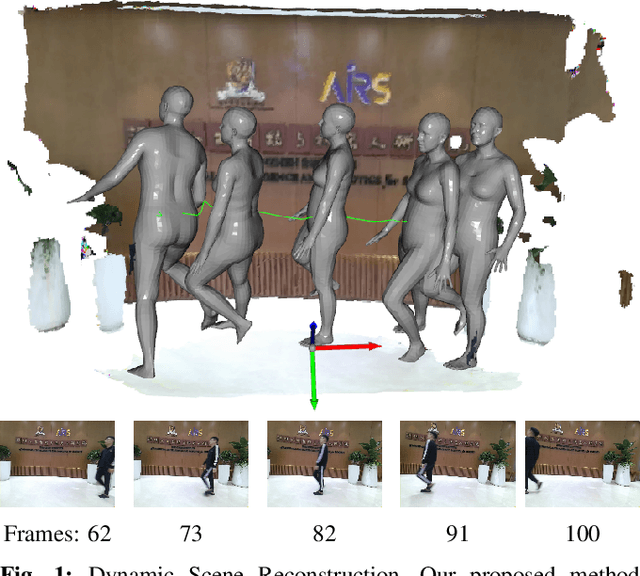



Dynamic environments that include unstructured moving objects pose a hard problem for Simultaneous Localization and Mapping (SLAM) performance. The motion of rigid objects can be typically tracked by exploiting their texture and geometric features. However, humans moving in the scene are often one of the most important, interactive targets - they are very hard to track and reconstruct robustly due to non-rigid shapes. In this work, we present a fast, learning-based human object detector to isolate the dynamic human objects and realise a real-time dense background reconstruction framework. We go further by estimating and reconstructing the human pose and shape. The final output environment maps not only provide the dense static backgrounds but also contain the dynamic human meshes and their trajectories. Our Dynamic SLAM system runs at around 26 frames per second (fps) on GPUs, while additionally turning on accurate human pose estimation can be executed at up to 10 fps.
Object-to-Scene: Learning to Transfer Object Knowledge to Indoor Scene Recognition
Aug 01, 2021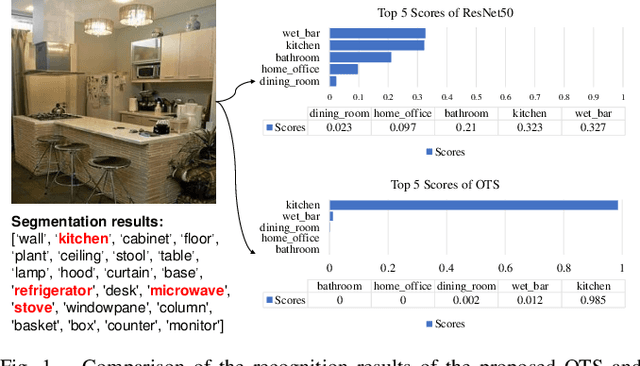
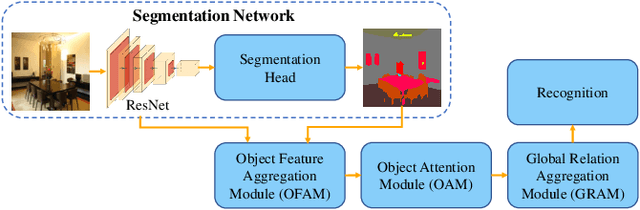
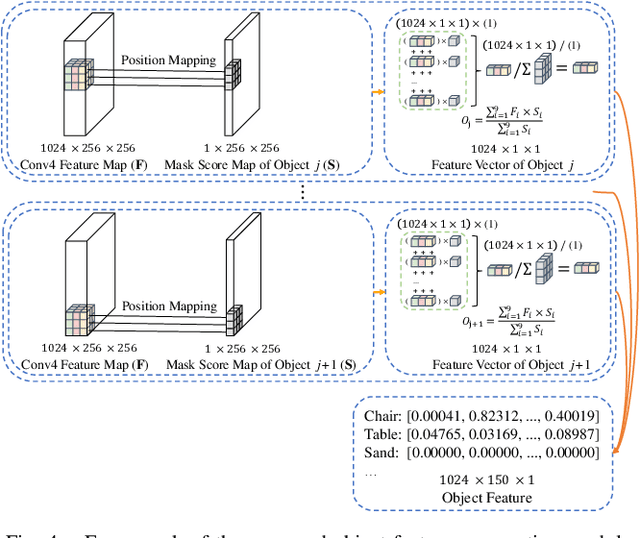
Accurate perception of the surrounding scene is helpful for robots to make reasonable judgments and behaviours. Therefore, developing effective scene representation and recognition methods are of significant importance in robotics. Currently, a large body of research focuses on developing novel auxiliary features and networks to improve indoor scene recognition ability. However, few of them focus on directly constructing object features and relations for indoor scene recognition. In this paper, we analyze the weaknesses of current methods and propose an Object-to-Scene (OTS) method, which extracts object features and learns object relations to recognize indoor scenes. The proposed OTS first extracts object features based on the segmentation network and the proposed object feature aggregation module (OFAM). Afterwards, the object relations are calculated and the scene representation is constructed based on the proposed object attention module (OAM) and global relation aggregation module (GRAM). The final results in this work show that OTS successfully extracts object features and learns object relations from the segmentation network. Moreover, OTS outperforms the state-of-the-art methods by more than 2\% on indoor scene recognition without using any additional streams. Code is publicly available at: https://github.com/FreeformRobotics/OTS.
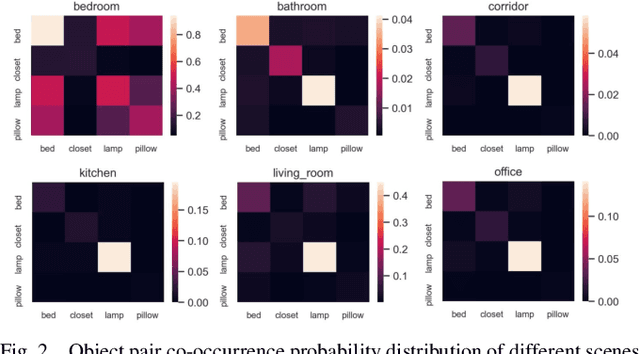
BORM: Bayesian Object Relation Model for Indoor Scene Recognition
Aug 01, 2021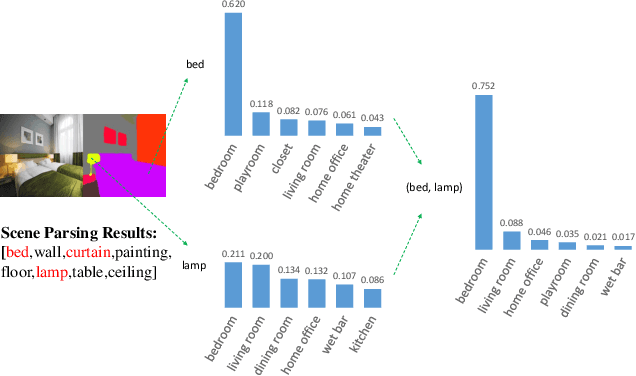
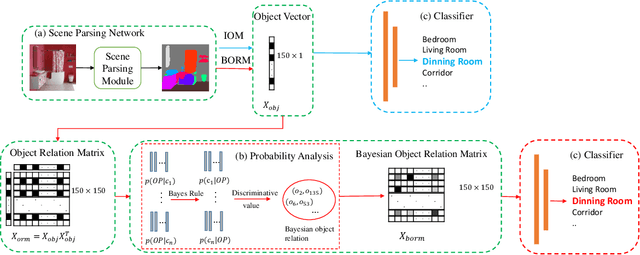
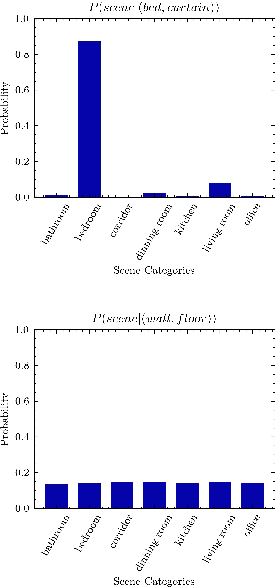
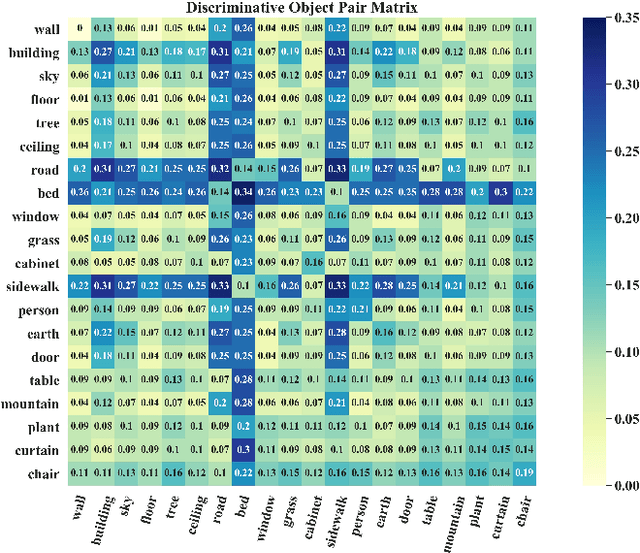
Scene recognition is a fundamental task in robotic perception. For human beings, scene recognition is reasonable because they have abundant object knowledge of the real world. The idea of transferring prior object knowledge from humans to scene recognition is significant but still less exploited. In this paper, we propose to utilize meaningful object representations for indoor scene representation. First, we utilize an improved object model (IOM) as a baseline that enriches the object knowledge by introducing a scene parsing algorithm pretrained on the ADE20K dataset with rich object categories related to the indoor scene. To analyze the object co-occurrences and pairwise object relations, we formulate the IOM from a Bayesian perspective as the Bayesian object relation model (BORM). Meanwhile, we incorporate the proposed BORM with the PlacesCNN model as the combined Bayesian object relation model (CBORM) for scene recognition and significantly outperforms the state-of-the-art methods on the reduced Places365 dataset, and SUN RGB-D dataset without retraining, showing the excellent generalization ability of the proposed method. Code can be found at https://github.com/hszhoushen/borm.
* 8 pages, 5 figures, conference, Accepted by IROS2021
Boosting Light-Weight Depth Estimation Via Knowledge Distillation
May 13, 2021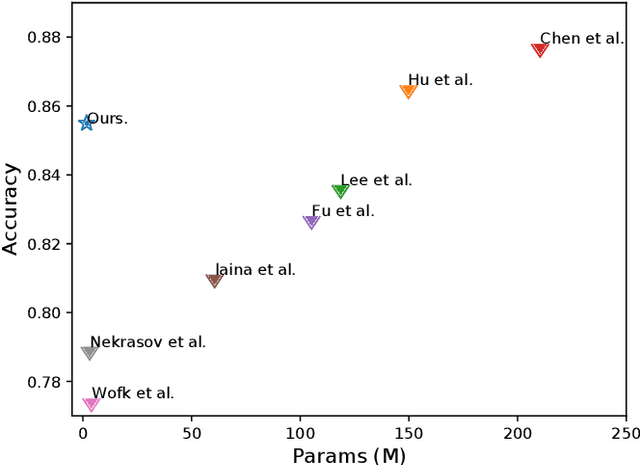

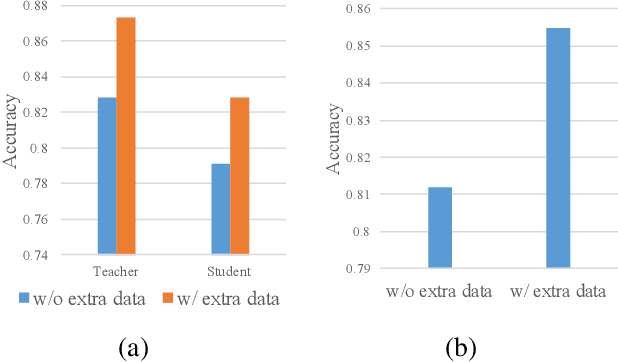
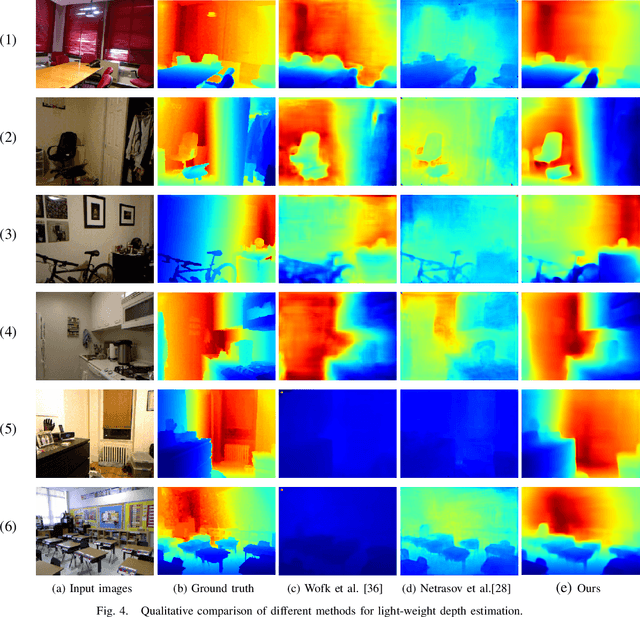
The advanced performance of depth estimation is achieved by the employment of large and complex neural networks. While the performance has still been continuously improved, we argue that the depth estimation has to be accurate and efficient. It's a preliminary requirement for real-world applications. However, fast depth estimation tends to lower the performance as the trade-off between the model's capacity and accuracy. In this paper, we attempt to archive highly accurate depth estimation with a light-weight network. To this end, we first introduce a compact network that can estimate a depth map in real-time. We then technically show two complementary and necessary strategies to improve the performance of the light-weight network. As the number of real-world scenes is infinite, the first is the employment of auxiliary data that increases the diversity of training data. The second is the use of knowledge distillation to further boost the performance. Through extensive and rigorous experiments, we show that our method outperforms previous light-weight methods in terms of inference accuracy, computational efficiency and generalization. We can achieve comparable performance compared to state-of-the-of-art methods with only 1% parameters, on the other hand, our method outperforms other light-weight methods by a significant margin.