 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOGAN: 3D-Aware Shadow and Occlusion Robust GAN for Makeup Transfer
Apr 21, 2021

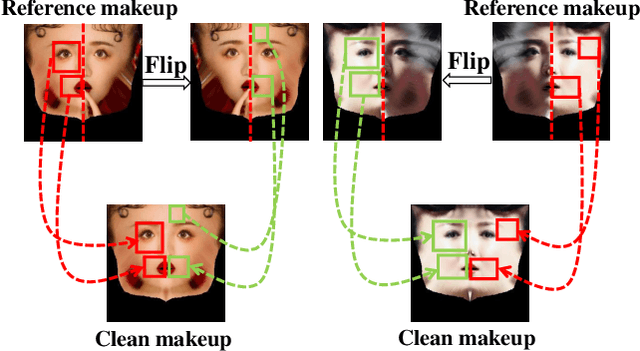
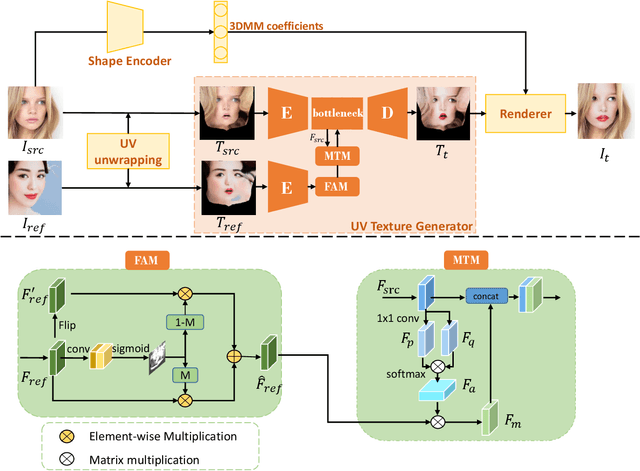
In recent years, virtual makeup applications have become more and more popular. However, it is still challenging to propose a robust makeup transfer method in the real-world environment. Current makeup transfer methods mostly work well on good-conditioned clean makeup images, but transferring makeup that exhibits shadow and occlusion is not satisfying. To alleviate it, we propose a novel makeup transfer method, called 3D-Aware Shadow and Occlusion Robust GAN (SOGAN). Given the source and the reference faces, we first fit a 3D face model and then disentangle the faces into shape and texture. In the texture branch, we map the texture to the UV space and design a UV texture generator to transfer the makeup. Since human faces are symmetrical in the UV space, we can conveniently remove the undesired shadow and occlusion from the reference image by carefully designing a Flip Attention Module (FAM). After obtaining cleaner makeup features from the reference image, a Makeup Transfer Module (MTM) is introduced to perform accurate makeup transfer. The qualitative and quantitative experiments demonstrate that our SOGAN not only achieves superior results in shadow and occlusion situations but also performs well in large pose and expression variations.
Locate then Segment: A Strong Pipeline for Referring Image Segmentation
Mar 30, 2021
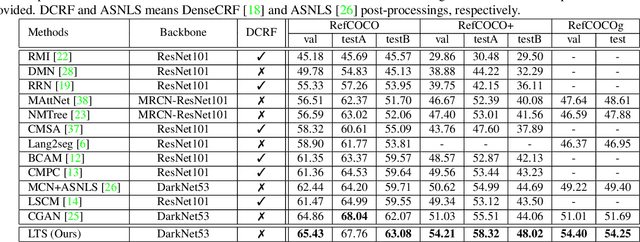
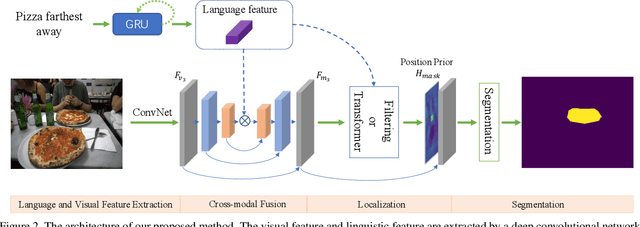
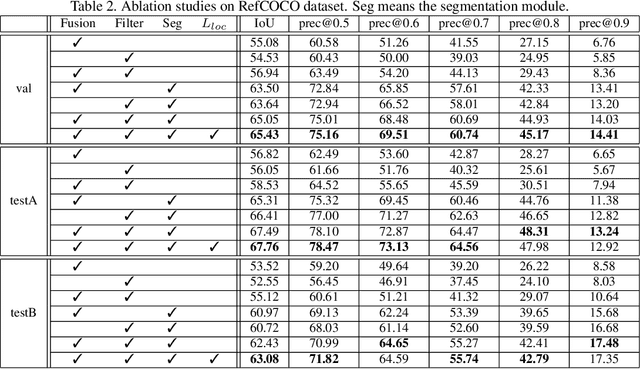
Referring image segmentation aims to segment the objects referred by a natural language expression. Previous methods usually focus on designing an implicit and recurrent feature interaction mechanism to fuse the visual-linguistic features to directly generate the final segmentation mask without explicitly modeling the localization information of the referent instances. To tackle these problems, we view this task from another perspective by decoupling it into a "Locate-Then-Segment" (LTS) scheme. Given a language expression, people generally first perform attention to the corresponding target image regions, then generate a fine segmentation mask about the object based on its context. The LTS first extracts and fuses both visual and textual features to get a cross-modal representation, then applies a cross-model interaction on the visual-textual features to locate the referred object with position prior, and finally generates the segmentation result with a light-weight segmentation network. Our LTS is simple but surprisingly effective. On three popular benchmark datasets, the LTS outperforms all the previous state-of-the-art methods by a large margin (e.g., +3.2% on RefCOCO+ and +3.4% on RefCOCOg). In addition, our model is more interpretable with explicitly locating the object, which is also proved by visualization experiments. We believe this framework is promising to serve as a strong baseline for referring image segmentation.
Learning Domain Invariant Representations for Generalizable Person Re-Identification
Mar 29, 2021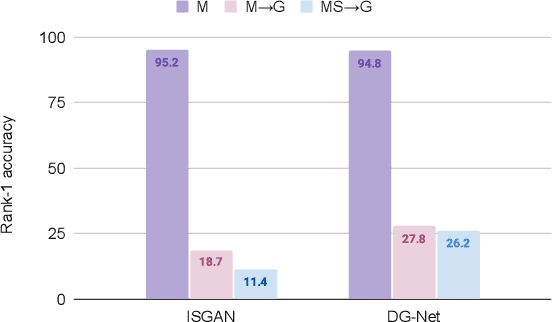
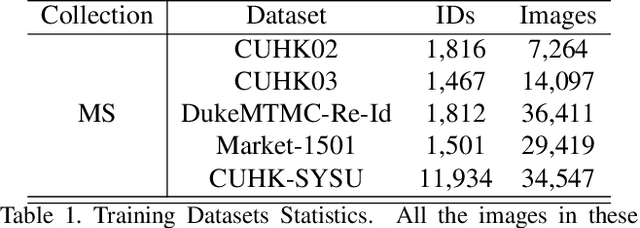
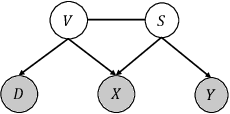
Generalizable person Re-Identification (ReID) has attracted growing attention in recent computer vision community, as it offers ready-to-use ReID models without the need for model retraining in new environments. In this work, we introduce causality into person ReID and propose a novel generalizable framework, named Domain Invariant Representations for generalizable person Re-Identification (DIR-ReID). We assume the data generation process is controlled by two sets of factors, i.e. identity-specific factors containing identity related cues, and domain-specific factors describing other scene-related information which cause distribution shifts across domains. With the assumption above, a novel Multi-Domain Disentangled Adversarial Network (MDDAN) is designed to disentangle these two sets of factors. Furthermore, a Causal Data Augmentation (CDA) block is proposed to perform feature-level data augmentation for better domain-invariant representations, which can be explained as interventions on latent factors from a causal learning perspective. Extensive experiments have been conducted, showing that DIR-ReID outperforms state-of-the-art methods on large-scale domain generalization (DG) ReID benchmarks. Moreover, a theoretical analysis is provided for a better understanding of our method.
Graph Classification by Mixture of Diverse Experts
Mar 29, 2021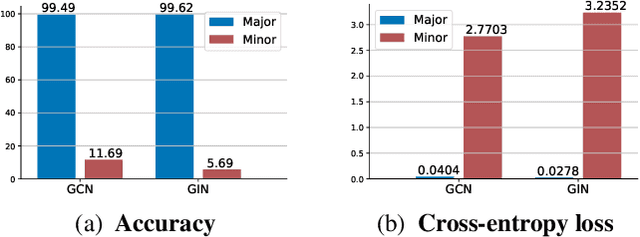
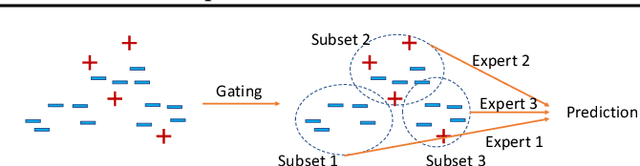
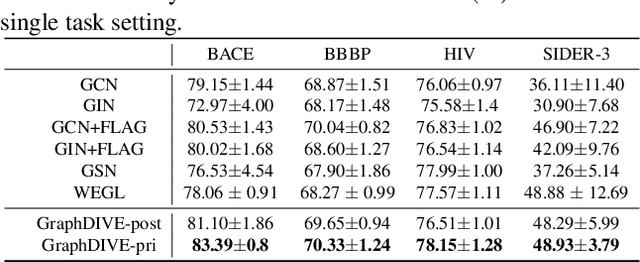
Graph classification is a challenging research problem in many applications across a broad range of domains. In these applications, it is very common that class distribution is imbalanced. Recently, Graph Neural Network (GNN) models have achieved superior performance on various real-world datasets. Despite their success, most of current GNN models largely overlook the important setting of imbalanced class distribution, which typically results in prediction bias towards majority classes. To alleviate the prediction bias, we propose to leverage semantic structure of dataset based on the distribution of node embedding. Specifically, we present GraphDIVE, a general framework leveraging mixture of diverse experts (i.e., graph classifiers) for imbalanced graph classification. With a divide-and-conquer principle, GraphDIVE employs a gating network to partition an imbalanced graph dataset into several subsets. Then each expert network is trained based on its corresponding subset. Experiments on real-world imbalanced graph datasets demonstrate the effectiveness of GraphDIVE.
Focal and Efficient IOU Loss for Accurate Bounding Box Regression
Jan 20, 2021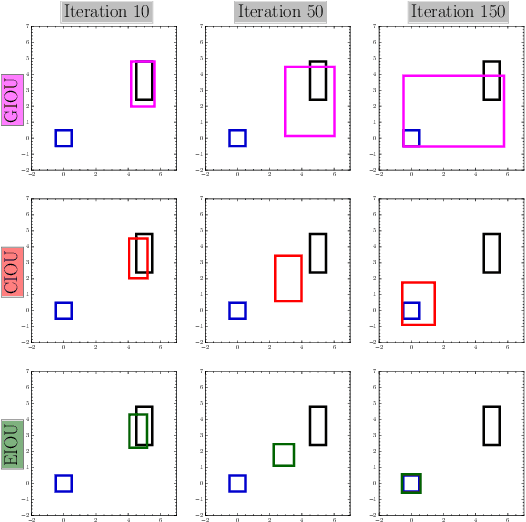
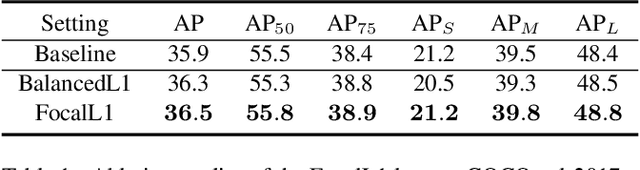
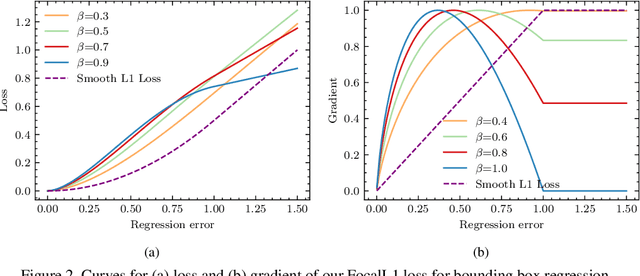
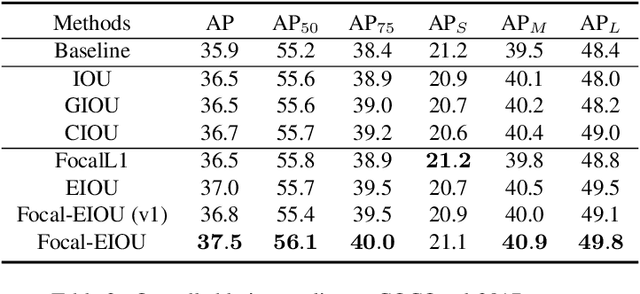
In object detection, bounding box regression (BBR) is a crucial step that determines the object localization performance. However, we find that most previous loss functions for BBR have two main drawbacks: (i) Both $\ell_n$-norm and IOU-based loss functions are inefficient to depict the objective of BBR, which leads to slow convergence and inaccurate regression results. (ii) Most of the loss functions ignore the imbalance problem in BBR that the large number of anchor boxes which have small overlaps with the target boxes contribute most to the optimization of BBR. To mitigate the adverse effects caused thereby, we perform thorough studies to exploit the potential of BBR losses in this paper. Firstly, an Efficient Intersection over Union (EIOU) loss is proposed, which explicitly measures the discrepancies of three geometric factors in BBR, i.e., the overlap area, the central point and the side length. After that, we state the Effective Example Mining (EEM) problem and propose a regression version of focal loss to make the regression process focus on high-quality anchor boxes. Finally, the above two parts are combined to obtain a new loss function, namely Focal-EIOU loss. Extensive experiments on both synthetic and real datasets are performed. Notable superiorities on both the convergence speed and the localization accuracy can be achieved over other BBR losses.
Rethinking the Heatmap Regression for Bottom-up Human Pose Estimation
Jan 05, 2021
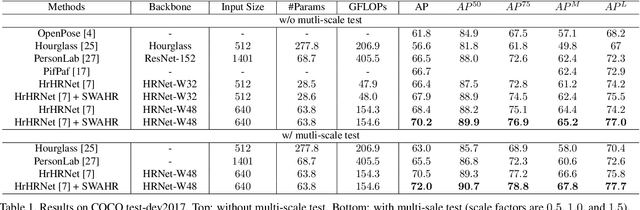
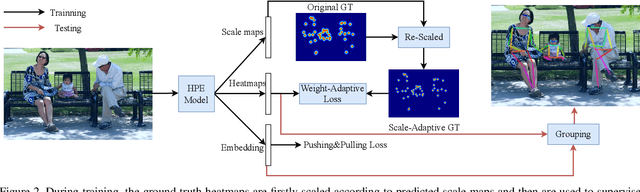
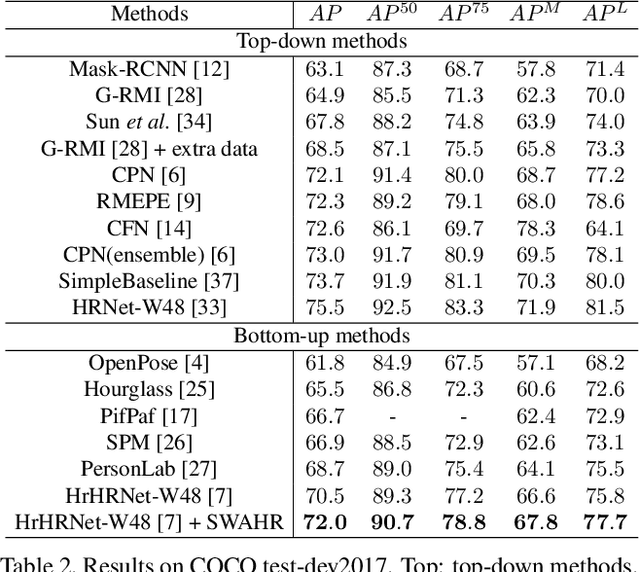
Heatmap regression has become the most prevalent choice for nowadays human pose estimation methods. The ground-truth heatmaps are usually constructed via covering all skeletal keypoints by 2D gaussian kernels. The standard deviations of these kernels are fixed. However, for bottom-up methods, which need to handle a large variance of human scales and labeling ambiguities, the current practice seems unreasonable. To better cope with these problems, we propose the scale-adaptive heatmap regression (SAHR) method, which can adaptively adjust the standard deviation for each keypoint. In this way, SAHR is more tolerant of various human scales and labeling ambiguities. However, SAHR may aggravate the imbalance between fore-background samples, which potentially hurts the improvement of SAHR. Thus, we further introduce the weight-adaptive heatmap regression (WAHR) to help balance the fore-background samples. Extensive experiments show that SAHR together with WAHR largely improves the accuracy of bottom-up human pose estimation. As a result, we finally outperform the state-of-the-art model by $+1.5AP$ and achieve $72.0 AP$ on COCO test-dev2017, which is comparable with the performances of most top-down methods.
Efficient Human Pose Estimation by Learning Deeply Aggregated Representations
Dec 15, 2020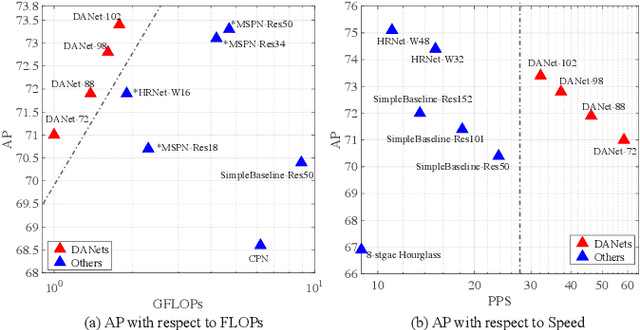
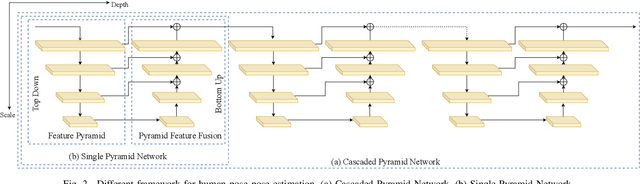
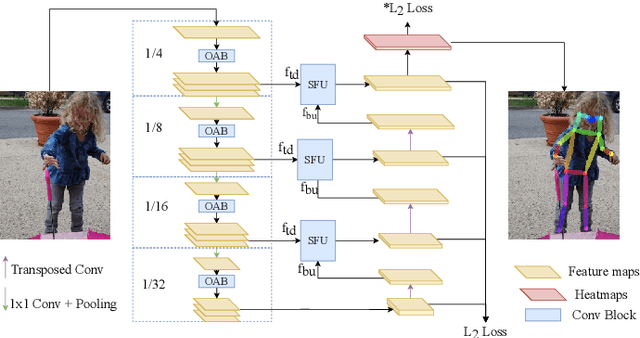
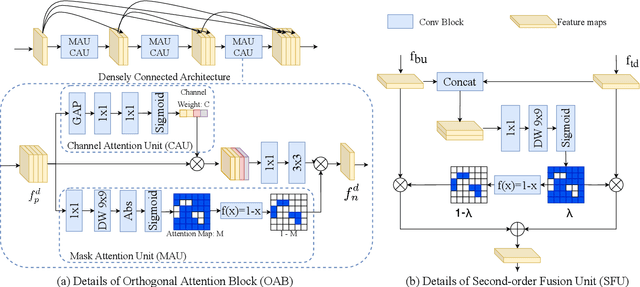
In this paper, we propose an efficient human pose estimation network (DANet) by learning deeply aggregated representations. Most existing models explore multi-scale information mainly from features with different spatial sizes. Powerful multi-scale representations usually rely on the cascaded pyramid framework. This framework largely boosts the performance but in the meanwhile makes networks very deep and complex. Instead, we focus on exploiting multi-scale information from layers with different receptive-field sizes and then making full of use this information by improving the fusion method. Specifically, we propose an orthogonal attention block (OAB) and a second-order fusion unit (SFU). The OAB learns multi-scale information from different layers and enhances them by encouraging them to be diverse. The SFU adaptively selects and fuses diverse multi-scale information and suppress the redundant ones. This could maximize the effective information in final fused representations. With the help of OAB and SFU, our single pyramid network may be able to generate deeply aggregated representations that contain even richer multi-scale information and have a larger representing capacity than that of cascaded networks. Thus, our networks could achieve comparable or even better accuracy with much smaller model complexity. Specifically, our \mbox{DANet-72} achieves $70.5$ in AP score on COCO test-dev set with only $1.0G$ FLOPs. Its speed on a CPU platform achieves $58$ Persons-Per-Second~(PPS).
Style Intervention: How to Achieve Spatial Disentanglement with Style-based Generators?
Nov 19, 2020


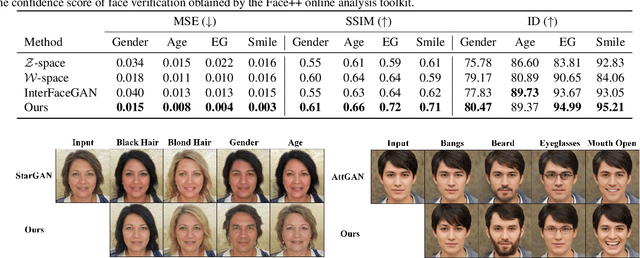
Generative Adversarial Networks (GANs) with style-based generators (e.g. StyleGAN) successfully enable semantic control over image synthesis, and recent studies have also revealed that interpretable image translations could be obtained by modifying the latent code. However, in terms of the low-level image content, traveling in the latent space would lead to `spatially entangled changes' in corresponding images, which is undesirable in many real-world applications where local editing is required. To solve this problem, we analyze properties of the 'style space' and explore the possibility of controlling the local translation with pre-trained style-based generators. Concretely, we propose 'Style Intervention', a lightweight optimization-based algorithm which could adapt to arbitrary input images and render natural translation effects under flexible objectives. We verify the performance of the proposed framework in facial attribute editing on high-resolution images, where both photo-realism and consistency are required. Extensive qualitative results demonstrate the effectiveness of our method, and quantitative measurements also show that the proposed algorithm outperforms state-of-the-art benchmarks in various aspects.
Unfolding the Alternating Optimization for Blind Super Resolution
Oct 16, 2020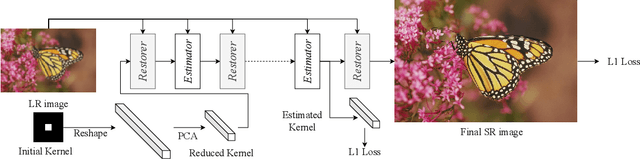
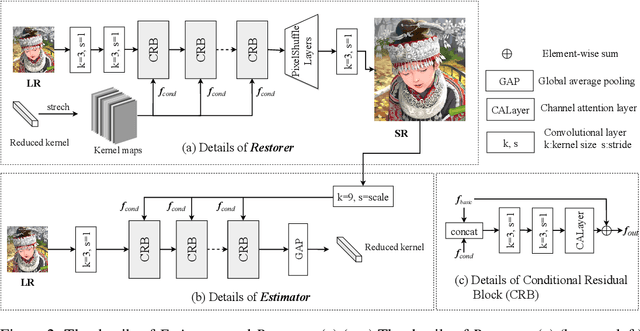
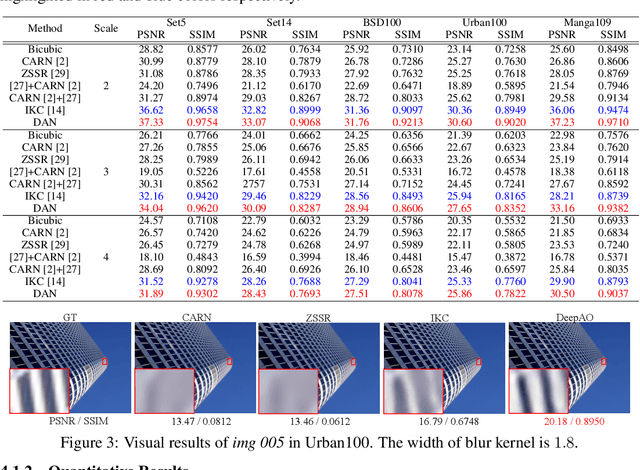

Previous methods decompose blind super resolution (SR) problem into two sequential steps: \textit{i}) estimating blur kernel from given low-resolution (LR) image and \textit{ii}) restoring SR image based on estimated kernel. This two-step solution involves two independently trained models, which may not be well compatible with each other. Small estimation error of the first step could cause severe performance drop of the second one. While on the other hand, the first step can only utilize limited information from LR image, which makes it difficult to predict highly accurate blur kernel. Towards these issues, instead of considering these two steps separately, we adopt an alternating optimization algorithm, which can estimate blur kernel and restore SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores SR image based on predicted kernel, and \textit{Estimator} estimates blur kernel with the help of restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, \textit{Estimator} utilizes information from both LR and SR images, which makes the estimation of blur kernel easier. More importantly, \textit{Restorer} is trained with the kernel estimated by \textit{Estimator}, instead of ground-truth kernel, thus \textit{Restorer} could be more tolerant to the estimation error of \textit{Estimator}. Extensive experiments on synthetic datasets and real-world images show that our model can largely outperform state-of-the-art methods and produce more visually favorable results at much higher speed. The source code is available at https://github.com/greatlog/DAN.git.
Adversarial Self-Supervised Learning for Semi-Supervised 3D Action Recognition
Jul 12, 2020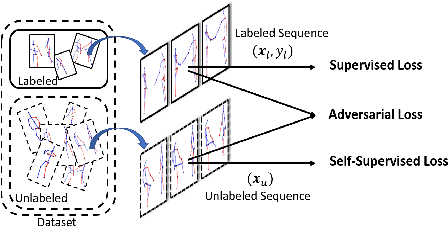
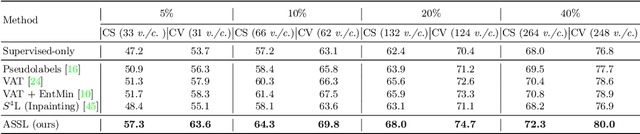
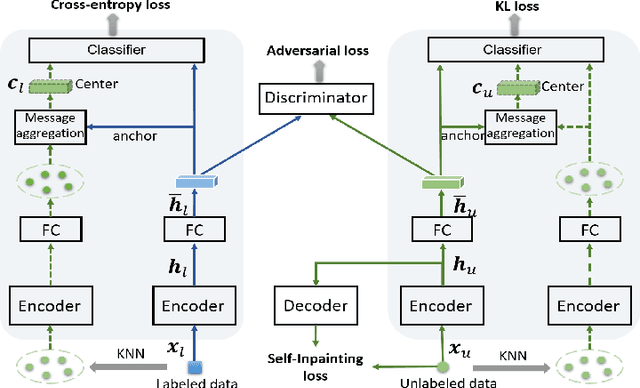
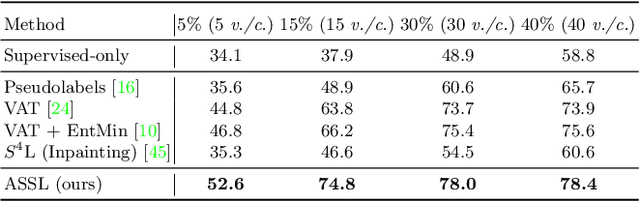
We consider the problem of semi-supervised 3D action recognition which has been rarely explored before. Its major challenge lies in how to effectively learn motion representations from unlabeled data. Self-supervised learning (SSL) has been proved very effective at learning representations from unlabeled data in the image domain. However, few effective self-supervised approaches exist for 3D action recognition, and directly applying SSL for semi-supervised learning suffers from misalignment of representations learned from SSL and supervised learning tasks. To address these issues, we present Adversarial Self-Supervised Learning (ASSL), a novel framework that tightly couples SSL and the semi-supervised scheme via neighbor relation exploration and adversarial learning. Specifically, we design an effective SSL scheme to improve the discrimination capability of learned representations for 3D action recognition, through exploring the data relations within a neighborhood. We further propose an adversarial regularization to align the feature distributions of labeled and unlabeled samples. To demonstrate effectiveness of the proposed ASSL in semi-supervised 3D action recognition, we conduct extensive experiments on NTU and N-UCLA datasets. The results confirm its advantageous performance over state-of-the-art semi-supervised methods in the few label regime for 3D action recognition.