 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training with Rectified Rejection
May 31, 2021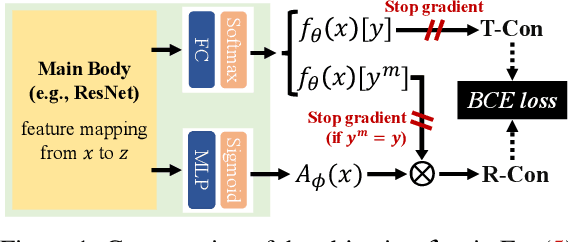
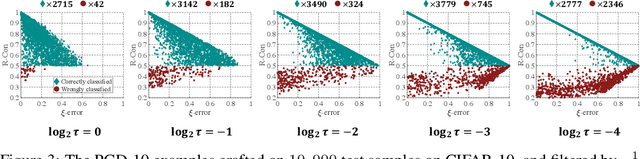
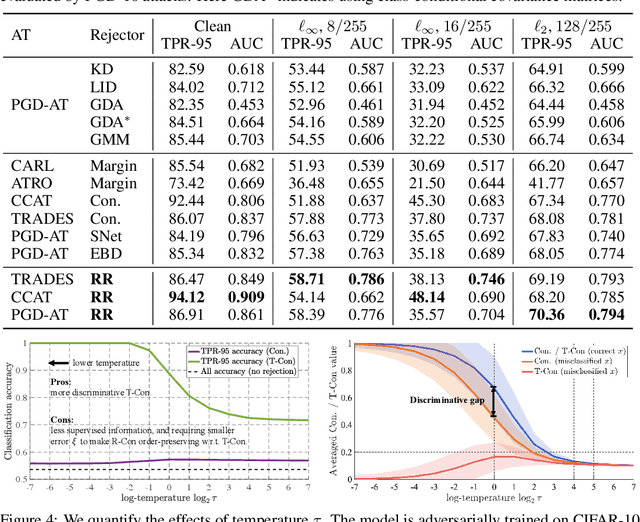
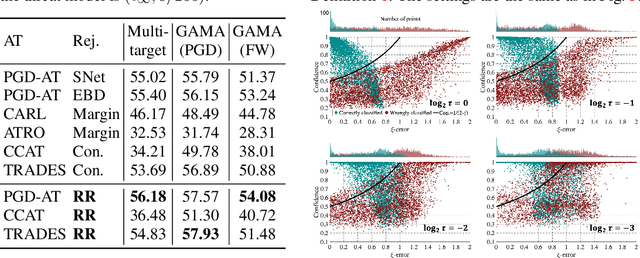
Adversarial training (AT) is one of the most effective strategies for promoting model robustness, whereas even the state-of-the-art adversarially trained models struggle to exceed 60% robust test accuracy on CIFAR-10 without additional data, which is far from practical. A natural way to break this accuracy bottleneck is to introduce a rejection option, where confidence is a commonly used certainty proxy. However, the vanilla confidence can overestimate the model certainty if the input is wrongly classified. To this end, we propose to use true confidence (T-Con) (i.e., predicted probability of the true class) as a certainty oracle, and learn to predict T-Con by rectifying confidence. We prove that under mild conditions, a rectified confidence (R-Con) rejector and a confidence rejector can be coupled to distinguish any wrongly classified input from correctly classified ones, even under adaptive attacks. We also quantify that training R-Con to be aligned with T-Con could be an easier task than learning robust classifiers. In our experiments, we evaluate our rectified rejection (RR) module on CIFAR-10, CIFAR-10-C, and CIFAR-100 under several attacks, and demonstrate that the RR module is well compatible with different AT frameworks on improving robustness, with little extra computation.
NAS-BERT: Task-Agnostic and Adaptive-Size BERT Compression with Neural Architecture Search
May 30, 2021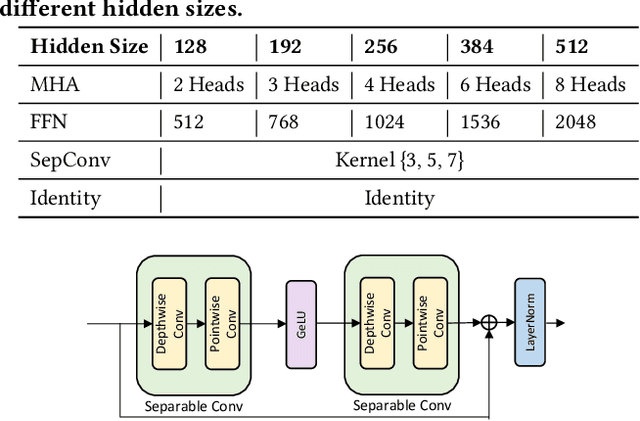
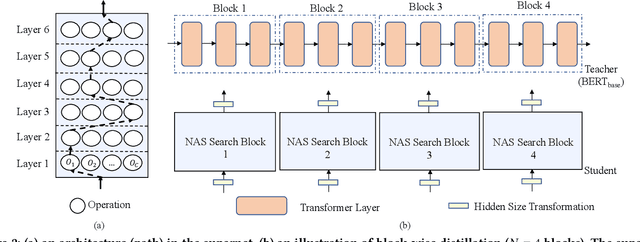
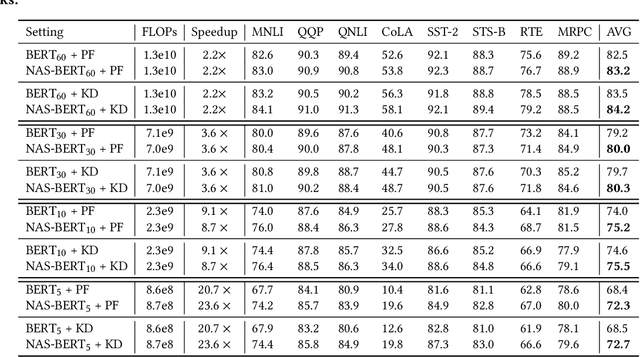
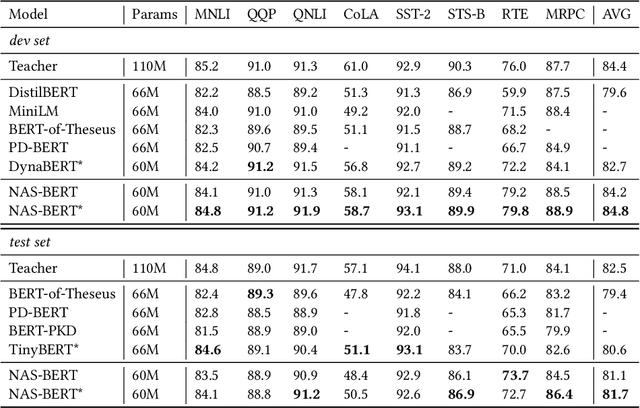
While pre-trained language models (e.g., BERT) have achieved impressive results on different natural language processing tasks, they have large numbers of parameters and suffer from big computational and memory costs, which make them difficult for real-world deployment. Therefore, model compression is necessary to reduce the computation and memory cost of pre-trained models. In this work, we aim to compress BERT and address the following two challenging practical issues: (1) The compression algorithm should be able to output multiple compressed models with different sizes and latencies, in order to support devices with different memory and latency limitations; (2) The algorithm should be downstream task agnostic, so that the compressed models are generally applicable for different downstream tasks. We leverage techniques in neural architecture search (NAS) and propose NAS-BERT, an efficient method for BERT compression. NAS-BERT trains a big supernet on a search space containing a variety of architectures and outputs multiple compressed models with adaptive sizes and latency. Furthermore, the training of NAS-BERT is conducted on standard self-supervised pre-training tasks (e.g., masked language model) and does not depend on specific downstream tasks. Thus, the compressed models can be used across various downstream tasks. The technical challenge of NAS-BERT is that training a big supernet on the pre-training task is extremely costly. We employ several techniques including block-wise search, search space pruning, and performance approximation to improve search efficiency and accuracy. Extensive experiments on GLUE and SQuAD benchmark datasets demonstrate that NAS-BERT can find lightweight models with better accuracy than previous approaches, and can be directly applied to different downstream tasks with adaptive model sizes for different requirements of memory or latency.
Learning Structures for Deep Neural Networks
May 27, 2021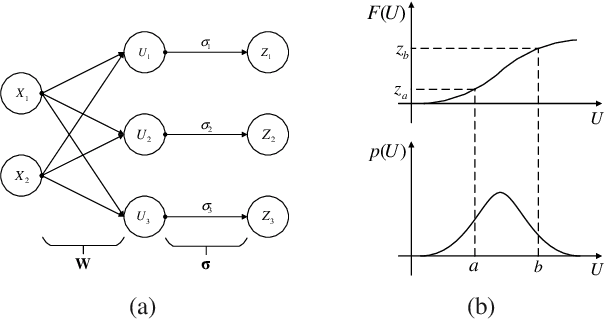
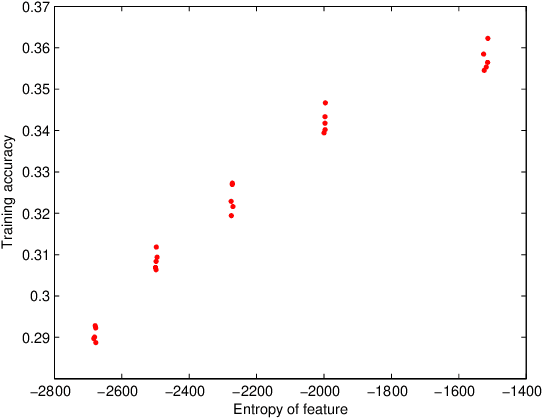

In this paper, we focus on the unsupervised setting for structure learning of deep neural networks and propose to adopt the efficient coding principle, rooted in information theory and developed in computational neuroscience, to guide the procedure of structure learning without label information. This principle suggests that a good network structure should maximize the mutual information between inputs and outputs, or equivalently maximize the entropy of outputs under mild assumptions. We further establish connections between this principle and the theory of Bayesian optimal classification, and empirically verify that larger entropy of the outputs of a deep neural network indeed corresponds to a better classification accuracy. Then as an implementation of the principle, we show that sparse coding can effectively maximize the entropy of the output signals, and accordingly design an algorithm based on global group sparse coding to automatically learn the inter-layer connection and determine the depth of a neural network. Our experiments on a public image classification dataset demonstrate that using the structure learned from scratch by our proposed algorithm, one can achieve a classification accuracy comparable to the best expert-designed structure (i.e., convolutional neural networks (CNN)). In addition, our proposed algorithm successfully discovers the local connectivity (corresponding to local receptive fields in CNN) and invariance structure (corresponding to pulling in CNN), as well as achieves a good tradeoff between marginal performance gain and network depth.
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
Apr 20, 2021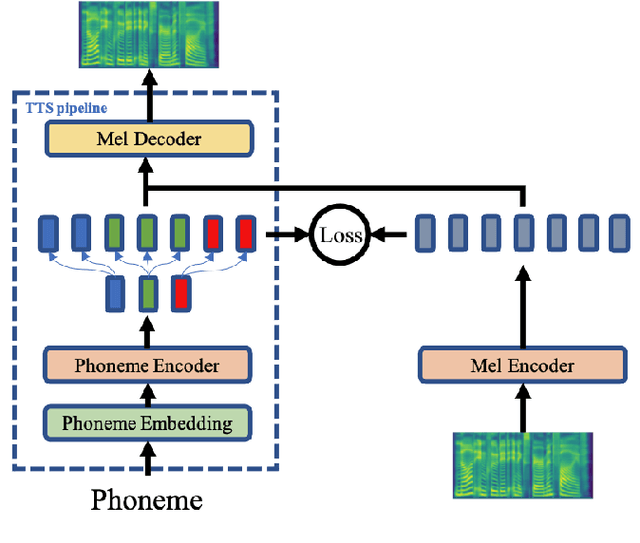
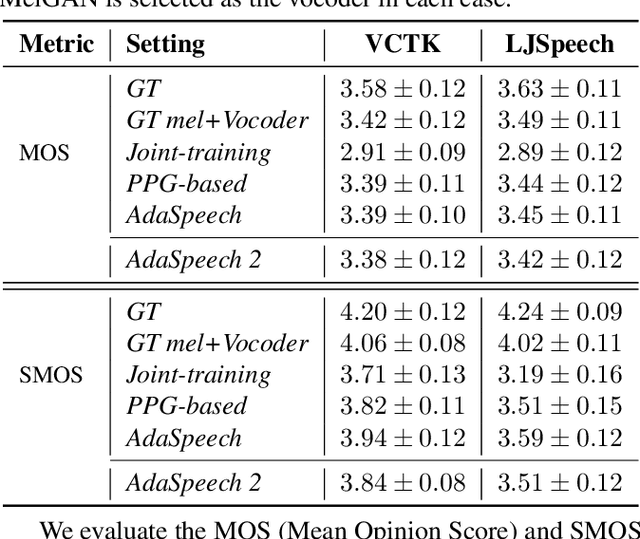
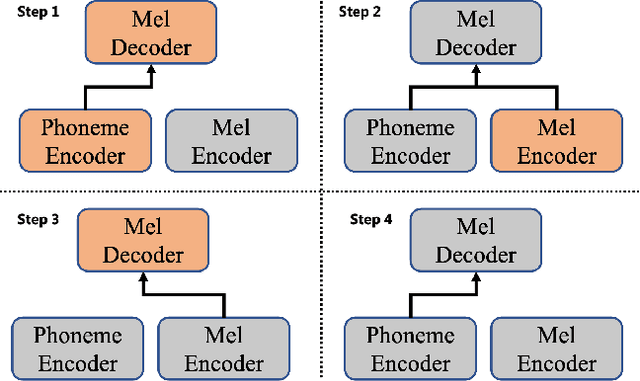

Text to speech (TTS) is widely used to synthesize personal voice for a target speaker, where a well-trained source TTS model is fine-tuned with few paired adaptation data (speech and its transcripts) on this target speaker. However, in many scenarios, only untranscribed speech data is available for adaptation, which brings challenges to the previous TTS adaptation pipelines (e.g., AdaSpeech). In this paper, we develop AdaSpeech 2, an adaptive TTS system that only leverages untranscribed speech data for adaptation. Specifically, we introduce a mel-spectrogram encoder to a well-trained TTS model to conduct speech reconstruction, and at the same time constrain the output sequence of the mel-spectrogram encoder to be close to that of the original phoneme encoder. In adaptation, we use untranscribed speech data for speech reconstruction and only fine-tune the TTS decoder. AdaSpeech 2 has two advantages: 1) Pluggable: our system can be easily applied to existing trained TTS models without re-training. 2) Effective: our system achieves on-par voice quality with the transcribed TTS adaptation (e.g., AdaSpeech) with the same amount of untranscribed data, and achieves better voice quality than previous untranscribed adaptation methods. Synthesized speech samples can be found at https://speechresearch.github.io/adaspeech2/.
UniDrop: A Simple yet Effective Technique to Improve Transformer without Extra Cost
Apr 11, 2021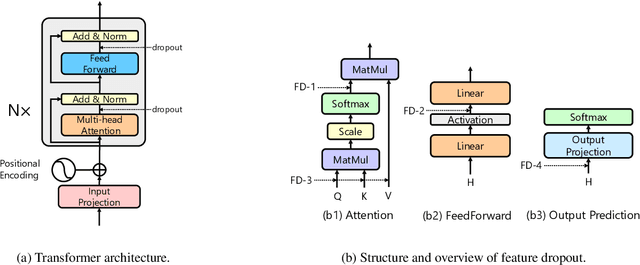

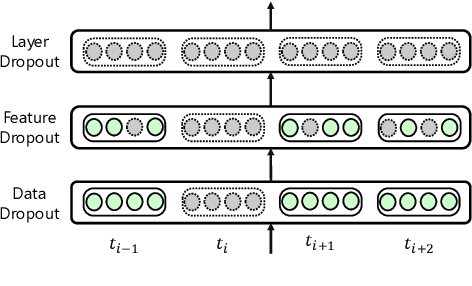

Transformer architecture achieves great success in abundant natural language processing tasks. The over-parameterization of the Transformer model has motivated plenty of works to alleviate its overfitting for superior performances. With some explorations, we find simple techniques such as dropout, can greatly boost model performance with a careful design. Therefore, in this paper, we integrate different dropout techniques into the training of Transformer models. Specifically, we propose an approach named UniDrop to unites three different dropout techniques from fine-grain to coarse-grain, i.e., feature dropout, structure dropout, and data dropout. Theoretically, we demonstrate that these three dropouts play different roles from regularization perspectives. Empirically, we conduct experiments on both neural machine translation and text classification benchmark datasets. Extensive results indicate that Transformer with UniDrop can achieve around 1.5 BLEU improvement on IWSLT14 translation tasks, and better accuracy for the classification even using strong pre-trained RoBERTa as backbone.
IOT: Instance-wise Layer Reordering for Transformer Structures
Mar 05, 2021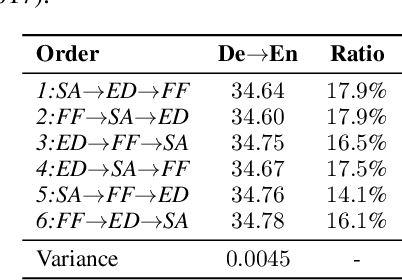
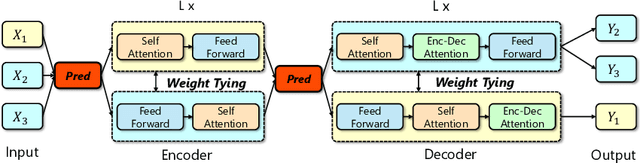

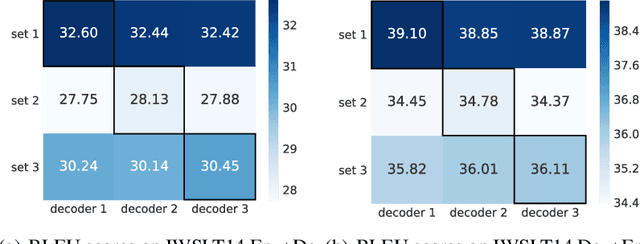
With sequentially stacked self-attention, (optional) encoder-decoder attention, and feed-forward layers, Transformer achieves big success in natural language processing (NLP), and many variants have been proposed. Currently, almost all these models assume that the layer order is fixed and kept the same across data samples. We observe that different data samples actually favor different orders of the layers. Based on this observation, in this work, we break the assumption of the fixed layer order in the Transformer and introduce instance-wise layer reordering into the model structure. Our Instance-wise Ordered Transformer (IOT) can model variant functions by reordered layers, which enables each sample to select the better one to improve the model performance under the constraint of almost the same number of parameters. To achieve this, we introduce a light predictor with negligible parameter and inference cost to decide the most capable and favorable layer order for any input sequence. Experiments on 3 tasks (neural machine translation, abstractive summarization, and code generation) and 9 datasets demonstrate consistent improvements of our method. We further show that our method can also be applied to other architectures beyond Transformer. Our code is released at Github.
Learning Invariant Representations across Domains and Tasks
Mar 03, 2021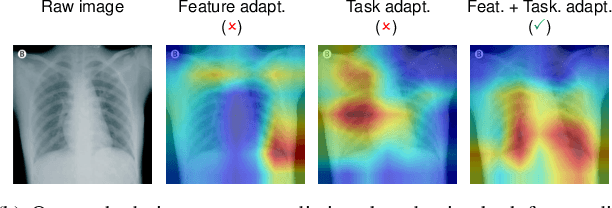
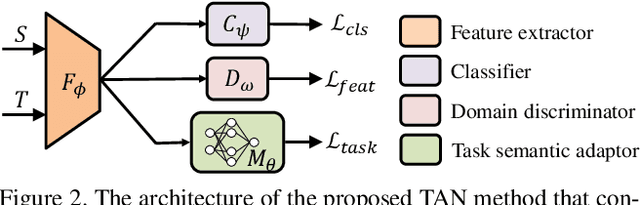
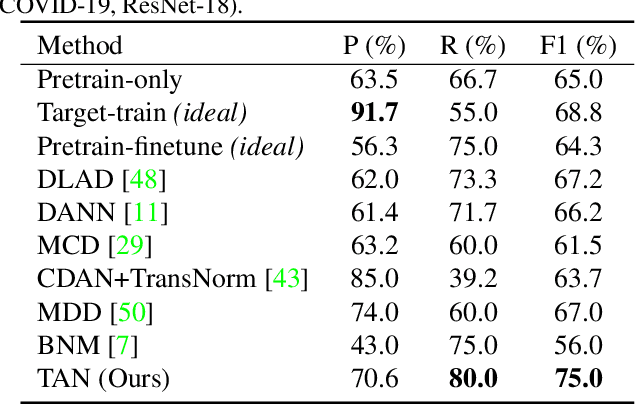
Being expensive and time-consuming to collect massive COVID-19 image samples to train deep classification models, transfer learning is a promising approach by transferring knowledge from the abundant typical pneumonia datasets for COVID-19 image classification. However, negative transfer may deteriorate the performance due to the feature distribution divergence between two datasets and task semantic difference in diagnosing pneumonia and COVID-19 that rely on different characteristics. It is even more challenging when the target dataset has no labels available, i.e., unsupervised task transfer learning. In this paper, we propose a novel Task Adaptation Network (TAN) to solve this unsupervised task transfer problem. In addition to learning transferable features via domain-adversarial training, we propose a novel task semantic adaptor that uses the learning-to-learn strategy to adapt the task semantics. Experiments on three public COVID-19 datasets demonstrate that our proposed method achieves superior performance. Especially on COVID-DA dataset, TAN significantly increases the recall and F1 score by 5.0% and 7.8% compared to recently strong baselines. Moreover, we show that TAN also achieves superior performance on several public domain adaptation benchmarks.
AdaSpeech: Adaptive Text to Speech for Custom Voice
Mar 01, 2021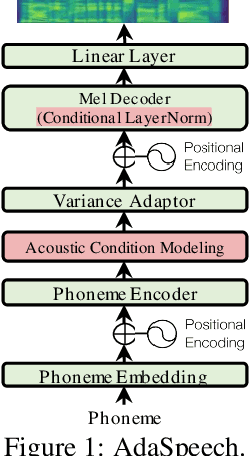
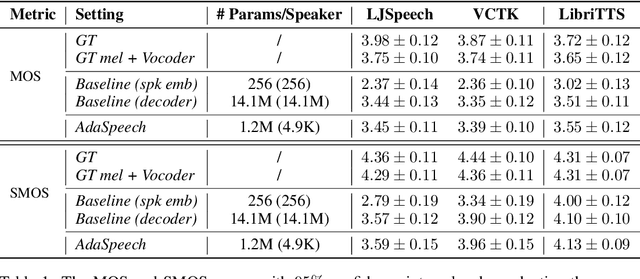
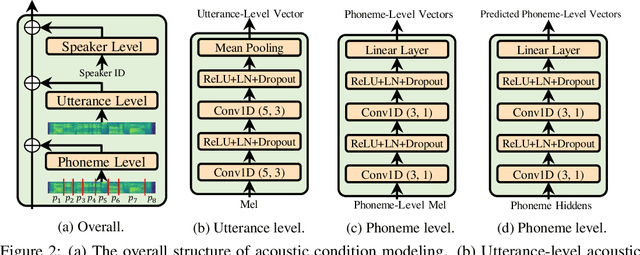
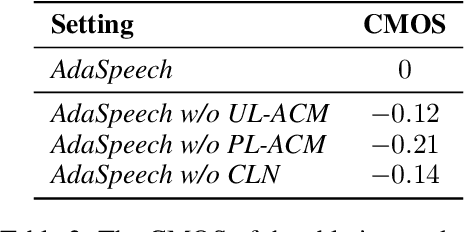
Custom voice, a specific text to speech (TTS) service in commercial speech platforms, aims to adapt a source TTS model to synthesize personal voice for a target speaker using few speech data. Custom voice presents two unique challenges for TTS adaptation: 1) to support diverse customers, the adaptation model needs to handle diverse acoustic conditions that could be very different from source speech data, and 2) to support a large number of customers, the adaptation parameters need to be small enough for each target speaker to reduce memory usage while maintaining high voice quality. In this work, we propose AdaSpeech, an adaptive TTS system for high-quality and efficient customization of new voices. We design several techniques in AdaSpeech to address the two challenges in custom voice: 1) To handle different acoustic conditions, we use two acoustic encoders to extract an utterance-level vector and a sequence of phoneme-level vectors from the target speech during training; in inference, we extract the utterance-level vector from a reference speech and use an acoustic predictor to predict the phoneme-level vectors. 2) To better trade off the adaptation parameters and voice quality, we introduce conditional layer normalization in the mel-spectrogram decoder of AdaSpeech, and fine-tune this part in addition to speaker embedding for adaptation. We pre-train the source TTS model on LibriTTS datasets and fine-tune it on VCTK and LJSpeech datasets (with different acoustic conditions from LibriTTS) with few adaptation data, e.g., 20 sentences, about 1 minute speech. Experiment results show that AdaSpeech achieves much better adaptation quality than baseline methods, with only about 5K specific parameters for each speaker, which demonstrates its effectiveness for custom voice. Audio samples are available at https://speechresearch.github.io/adaspeech/.
Do Not Let Privacy Overbill Utility: Gradient Embedding Perturbation for Private Learning
Feb 26, 2021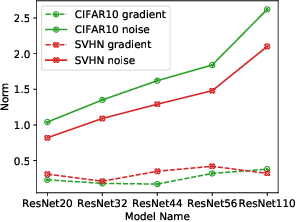
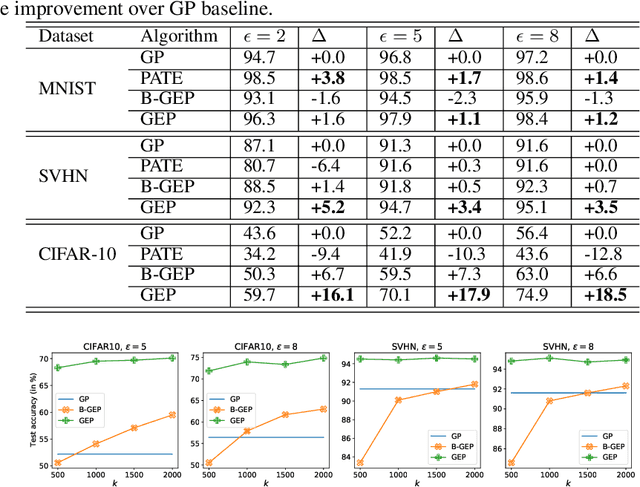
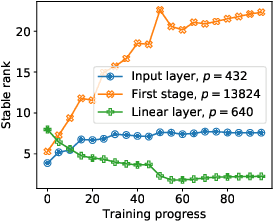
The privacy leakage of the model about the training data can be bounded in the differential privacy mechanism. However, for meaningful privacy parameters, a differentially private model degrades the utility drastically when the model comprises a large number of trainable parameters. In this paper, we propose an algorithm \emph{Gradient Embedding Perturbation (GEP)} towards training differentially private deep models with decent accuracy. Specifically, in each gradient descent step, GEP first projects individual private gradient into a non-sensitive anchor subspace, producing a low-dimensional gradient embedding and a small-norm residual gradient. Then, GEP perturbs the low-dimensional embedding and the residual gradient separately according to the privacy budget. Such a decomposition permits a small perturbation variance, which greatly helps to break the dimensional barrier of private learning. With GEP, we achieve decent accuracy with reasonable computational cost and modest privacy guarantee for deep models. Especially, with privacy bound $\epsilon=8$, we achieve $74.9\%$ test accuracy on CIFAR10 and $95.1\%$ test accuracy on SVHN, significantly improving over existing results.
LazyFormer: Self Attention with Lazy Update
Feb 25, 2021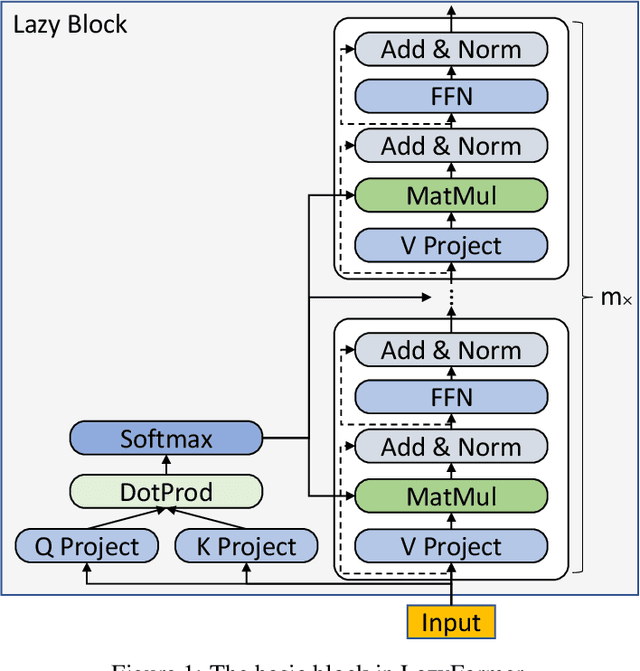


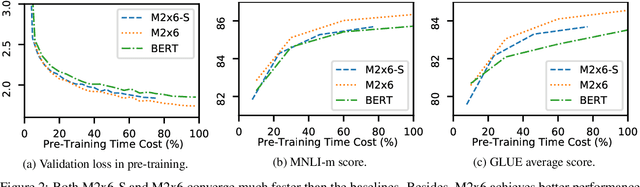
Improving the efficiency of Transformer-based language pre-training is an important task in NLP, especially for the self-attention module, which is computationally expensive. In this paper, we propose a simple but effective solution, called \emph{LazyFormer}, which computes the self-attention distribution infrequently. LazyFormer composes of multiple lazy blocks, each of which contains multiple Transformer layers. In each lazy block, the self-attention distribution is only computed once in the first layer and then is reused in all upper layers. In this way, the cost of computation could be largely saved. We also provide several training tricks for LazyFormer. Extensive experiments demonstrate the effectiveness of the proposed method.