 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Deformation Planning and Neural Tracking for DLOs in Constrained Environments
Dec 31, 2025Deformable linear objects (DLOs) manipulation presents significant challenges due to DLOs' inherent high-dimensional state space and complex deformation dynamics. The wide-populated obstacles in realistic workspaces further complicate DLO manipulation, necessitating efficient deformation planning and robust deformation tracking. In this work, we propose a novel framework for DLO manipulation in constrained environments. This framework combines hierarchical deformation planning with neural tracking, ensuring reliable performance in both global deformation synthesis and local deformation tracking. Specifically, the deformation planner begins by generating a spatial path set that inherently satisfies the homotopic constraints associated with DLO keypoint paths. Next, a path-set-guided optimization method is applied to synthesize an optimal temporal deformation sequence for the DLO. In manipulation execution, a neural model predictive control approach, leveraging a data-driven deformation model, is designed to accurately track the planned DLO deformation sequence. The effectiveness of the proposed framework is validated in extensive constrained DLO manipulation tasks.
SimTac: A Physics-Based Simulator for Vision-Based Tactile Sensing with Biomorphic Structures
Nov 14, 2025Tactile sensing in biological organisms is deeply intertwined with morphological form, such as human fingers, cat paws, and elephant trunks, which enables rich and adaptive interactions through a variety of geometrically complex structures. In contrast, vision-based tactile sensors in robotics have been limited to simple planar geometries, with biomorphic designs remaining underexplored. To address this gap, we present SimTac, a physics-based simulation framework for the design and validation of biomorphic tactile sensors. SimTac consists of particle-based deformation modeling, light-field rendering for photorealistic tactile image generation, and a neural network for predicting mechanical responses, enabling accurate and efficient simulation across a wide range of geometries and materials. We demonstrate the versatility of SimTac by designing and validating physical sensor prototypes inspired by biological tactile structures and further demonstrate its effectiveness across multiple Sim2Real tactile tasks, including object classification, slip detection, and contact safety assessment. Our framework bridges the gap between bio-inspired design and practical realisation, expanding the design space of tactile sensors and paving the way for tactile sensing systems that integrate morphology and sensing to enable robust interaction in unstructured environments.
A Multimodal Approach for Fluid Overload Prediction: Integrating Lung Ultrasound and Clinical Data
Sep 13, 2024

Managing fluid balance in dialysis patients is crucial, as improper management can lead to severe complications. In this paper, we propose a multimodal approach that integrates visual features from lung ultrasound images with clinical data to enhance the prediction of excess body fluid. Our framework employs independent encoders to extract features for each modality and combines them through a cross-domain attention mechanism to capture complementary information. By framing the prediction as a classification task, the model achieves significantly better performance than regression. The results demonstrate that multimodal models consistently outperform single-modality models, particularly when attention mechanisms prioritize tabular data. Pseudo-sample generation further contributes to mitigating the imbalanced classification problem, achieving the highest accuracy of 88.31%. This study underscores the effectiveness of multimodal learning for fluid overload management in dialysis patients, offering valuable insights for improved clinical outcomes.
DUCPS: Deep Unfolding the Cauchy Proximal Splitting Algorithm for B-Lines Quantification in Lung Ultrasound Images
Jul 16, 2024The identification of artefacts, particularly B-lines, in lung ultrasound (LUS), is crucial for assisting clinical diagnosis, prompting the development of innovative methodologies. While the Cauchy proximal splitting (CPS) algorithm has demonstrated effective performance in B-line detection, the process is slow and has limited generalization. This paper addresses these issues with a novel unsupervised deep unfolding network structure (DUCPS). The framework utilizes deep unfolding procedures to merge traditional model-based techniques with deep learning approaches. By unfolding the CPS algorithm into a deep network, DUCPS enables the parameters in the optimization algorithm to be learnable, thus enhancing generalization performance and facilitating rapid convergence. We conducted entirely unsupervised training using the Neighbor2Neighbor (N2N) and the Structural Similarity Index Measure (SSIM) losses. When combined with an improved line identification method proposed in this paper, state-of-the-art performance is achieved, with the recall and F2 score reaching 0.70 and 0.64, respectively. Notably, DUCPS significantly improves computational efficiency eliminating the need for extensive data labeling, representing a notable advancement over both traditional algorithms and existing deep learning approaches.
DUBLINE: A Deep Unfolding Network for B-line Detection in Lung Ultrasound Images
Nov 11, 2023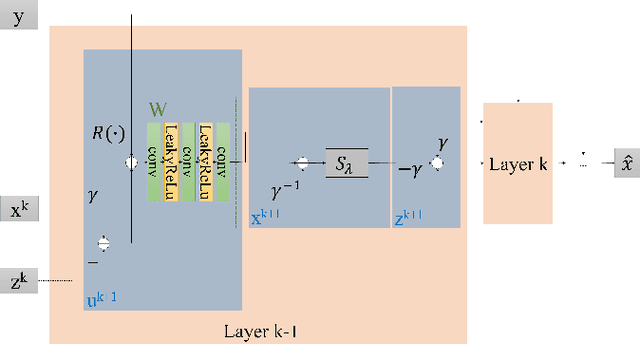
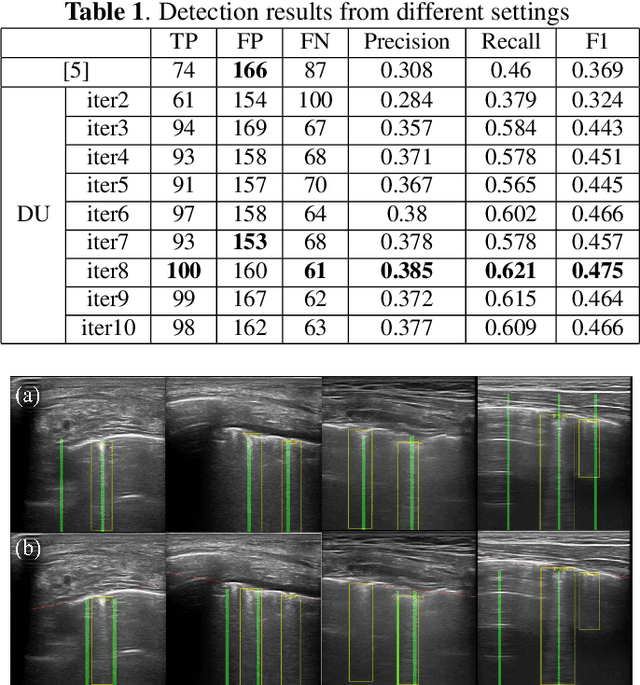

In the context of lung ultrasound, the detection of B-lines, which are indicative of interstitial lung disease and pulmonary edema, plays a pivotal role in clinical diagnosis. Current methods still rely on visual inspection by experts. Vision-based automatic B-line detection methods have been developed, but their performance has yet to improve in terms of both accuracy and computational speed. This paper presents a novel approach to posing B-line detection as an inverse problem via deep unfolding of the Alternating Direction Method of Multipliers (ADMM). It tackles the challenges of data labelling and model training in lung ultrasound image analysis by harnessing the capabilities of deep neural networks and model-based methods. Our objective is to substantially enhance diagnostic accuracy while ensuring efficient real-time capabilities. The results show that the proposed method runs more than 90 times faster than the traditional model-based method and achieves an F1 score that is 10.6% higher.
A Semi-supervised Learning Approach for B-line Detection in Lung Ultrasound Images
Nov 30, 2022



Studies have proved that the number of B-lines in lung ultrasound images has a strong statistical link to the amount of extravascular lung water, which is significant for hemodialysis treatment. Manual inspection of B-lines requires experts and is time-consuming, whilst modelling automation methods is currently problematic because of a lack of ground truth. Therefore, in this paper, we propose a novel semi-supervised learning method for the B-line detection task based on contrastive learning. Through multi-level unsupervised learning on unlabelled lung ultrasound images, the features of the artefacts are learnt. In the downstream task, we introduce a fine-tuning process on a small number of labelled images using the EIoU-based loss function. Apart from reducing the data labelling workload, the proposed method shows a superior performance to model-based algorithm with the recall of 91.43%, the accuracy of 84.21% and the F1 score of 91.43%.
AdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search
Apr 25, 2021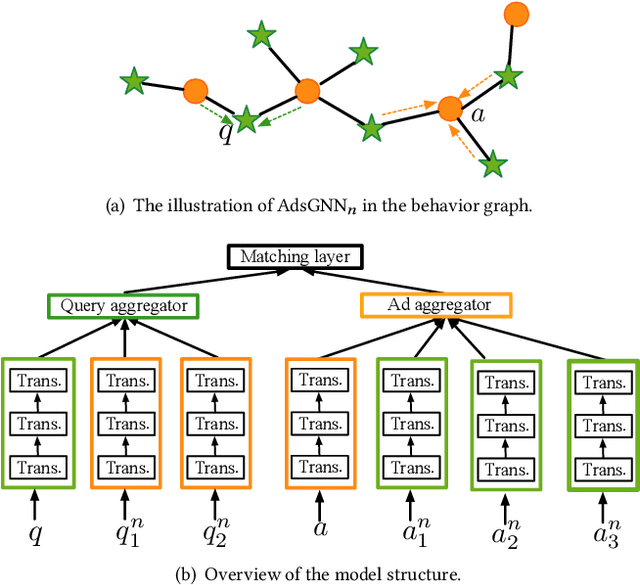

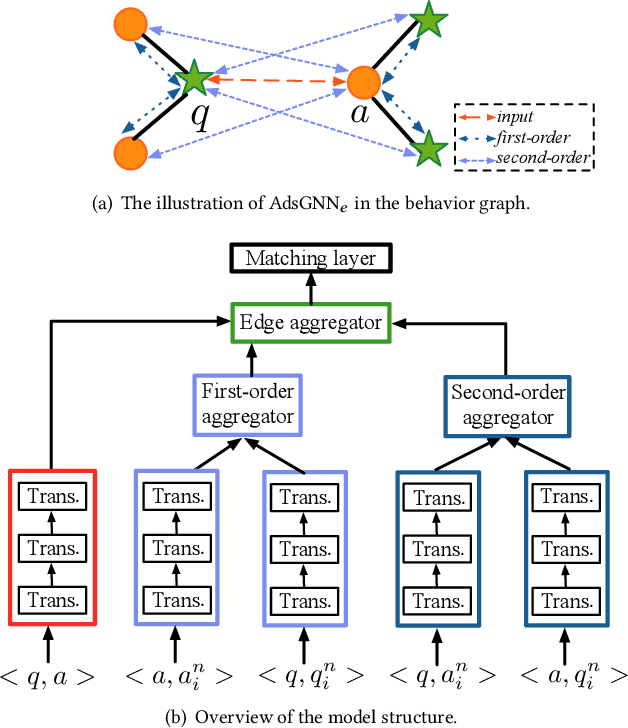
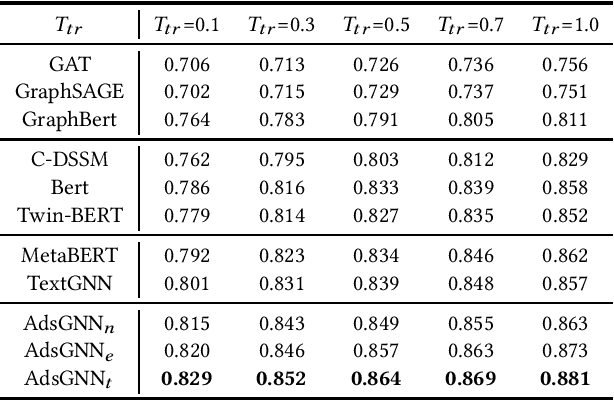
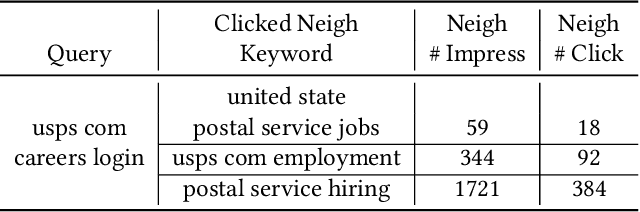
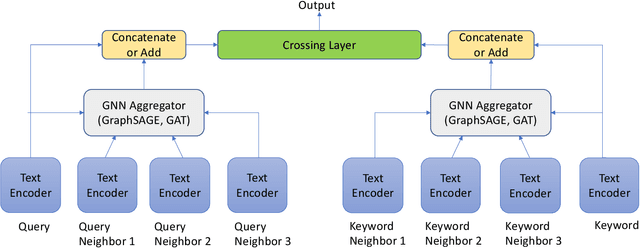
Sponsored search ads appear next to search results when people look for products and services on search engines. In recent years, they have become one of the most lucrative channels for marketing. As the fundamental basis of search ads, relevance modeling has attracted increasing attention due to the significant research challenges and tremendous practical value. Most existing approaches solely rely on the semantic information in the input query-ad pair, while the pure semantic information in the short ads data is not sufficient to fully identify user's search intents. Our motivation lies in incorporating the tremendous amount of unsupervised user behavior data from the historical search logs as the complementary graph to facilitate relevance modeling. In this paper, we extensively investigate how to naturally fuse the semantic textual information with the user behavior graph, and further propose three novel AdsGNN models to aggregate topological neighborhood from the perspectives of nodes, edges and tokens. Furthermore, two critical but rarely investigated problems, domain-specific pre-training and long-tail ads matching, are studied thoroughly. Empirically, we evaluate the AdsGNN models over the large industry dataset, and the experimental results of online/offline tests consistently demonstrate the superiority of our proposal.
Current Advances in Computational Lung Ultrasound Imaging: A Review
Mar 23, 2021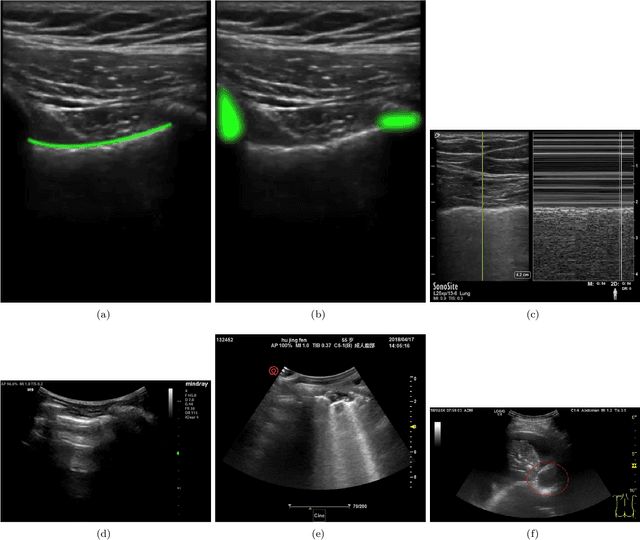
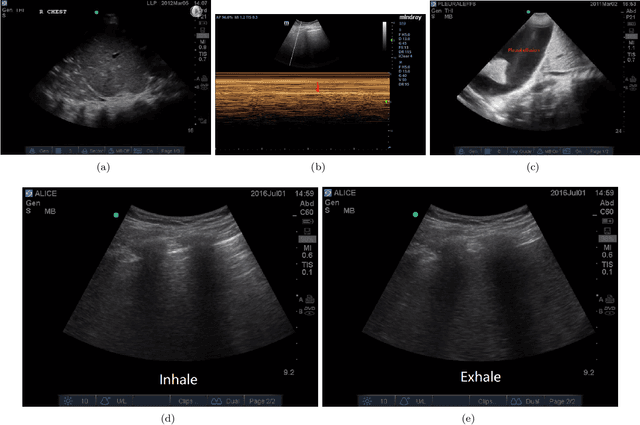
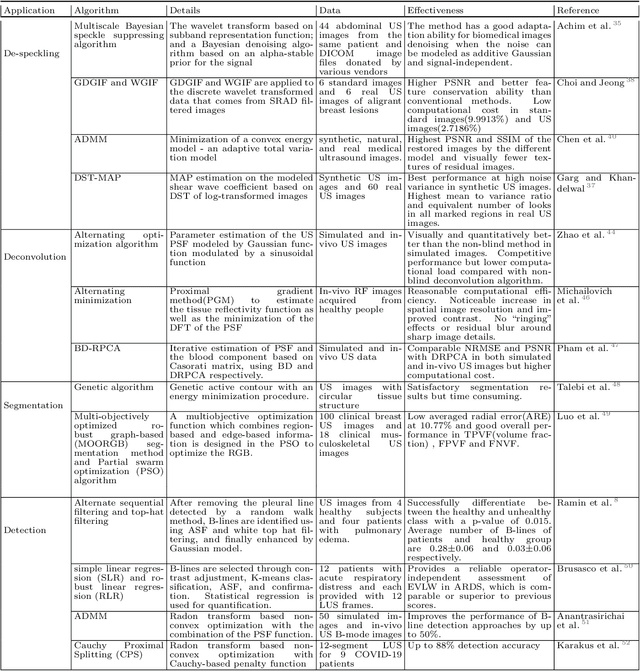
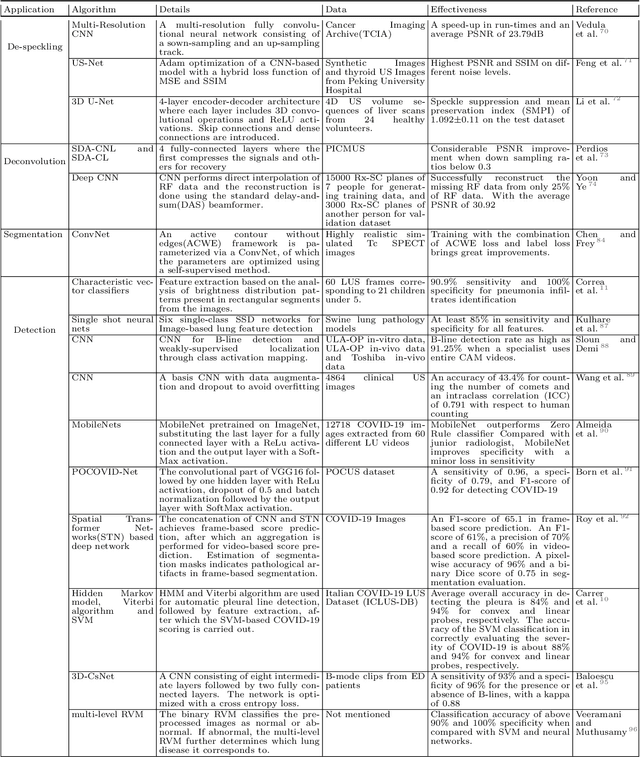
In the field of biomedical imaging, ultrasonography has become increasingly widespread, and an important auxiliary diagnostic tool with unique advantages, such as being non-ionising and often portable. This article reviews the state-of-the-art in medical ultrasound image computing and in particular its application in the examination of the lungs. First, we review the current developments in medical ultrasound technology. We then focus on the characteristics of lung ultrasonography and on its ability to diagnose a variety of diseases through the identification of various artefacts. We review medical ultrasound image processing methods by splitting them into two categories: (1) traditional model-based methods, and (2) data driven methods. For the former, we consider inverse problem based methods by focusing in particular on ultrasound image despeckling, deconvolution, and line artefacts detection. Among the data-driven approaches, we discuss various works based on deep/machine learning, which include various effective network architectures implementing supervised, weakly supervised and unsupervised learning.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021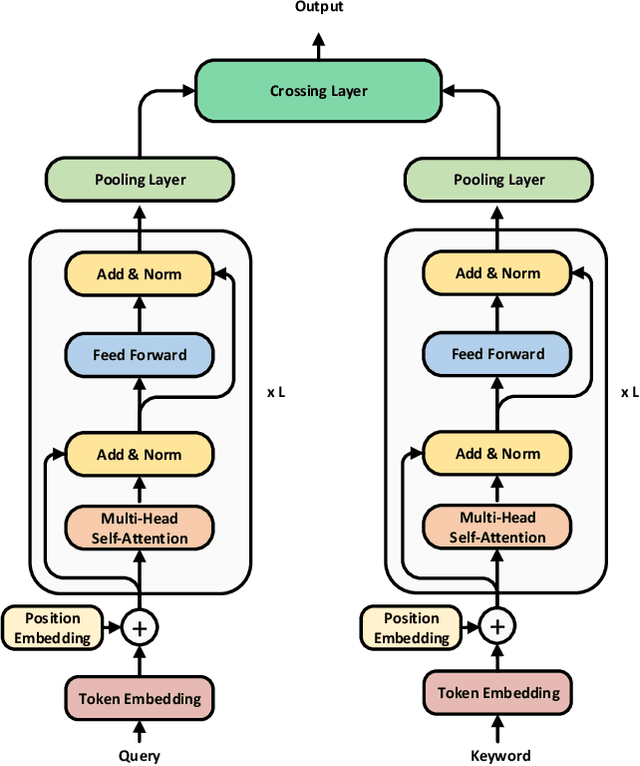
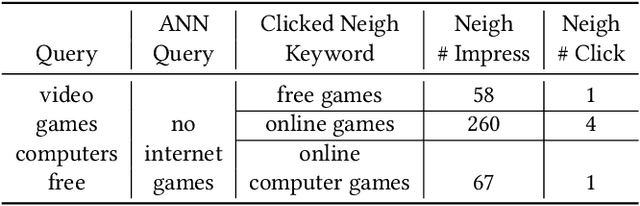
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.
End-to-End Framework for Efficient Deep Learning Using Metasurfaces Optics
Nov 23, 2020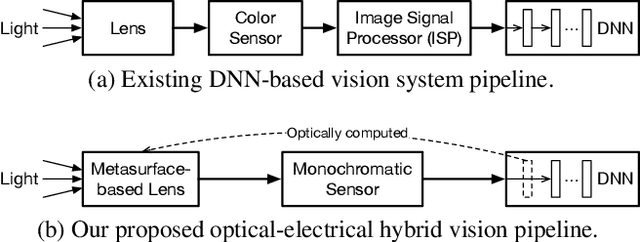
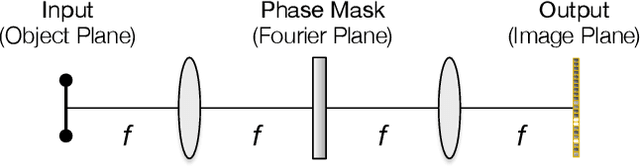
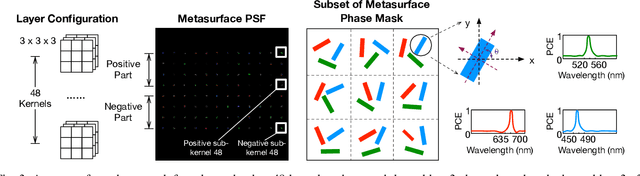
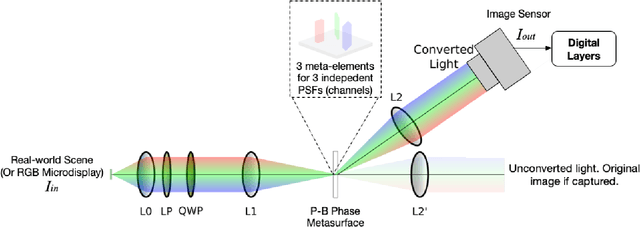
Deep learning using Convolutional Neural Networks (CNNs) has been shown to significantly out-performed many conventional vision algorithms. Despite efforts to increase the CNN efficiency both algorithmically and with specialized hardware, deep learning remains difficult to deploy in resource-constrained environments. In this paper, we propose an end-to-end framework to explore optically compute the CNNs in free-space, much like a computational camera. Compared to existing free-space optics-based approaches which are limited to processing single-channel (i.e., grayscale) inputs, we propose the first general approach, based on nanoscale meta-surface optics, that can process RGB data directly from the natural scenes. Our system achieves up to an order of magnitude energy saving, simplifies the sensor design, all the while sacrificing little network accuracy.