 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Scene Segmentation Using a Light Deep Neural Network Architecture for Autonomous Robot Navigation on Construction Sites
Jan 24, 2019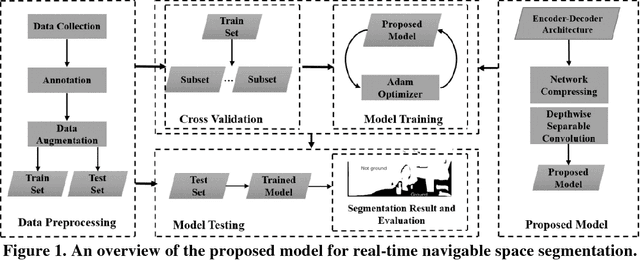
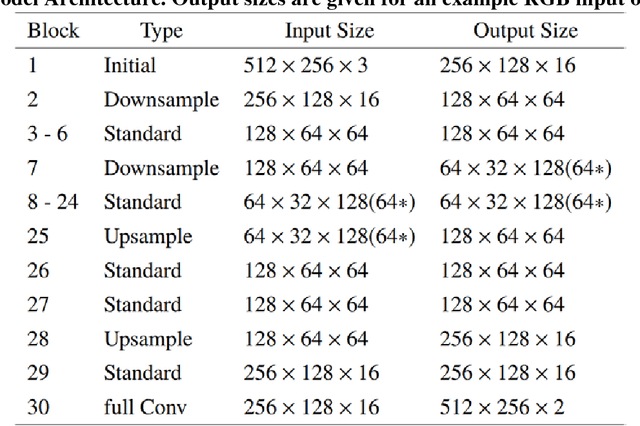
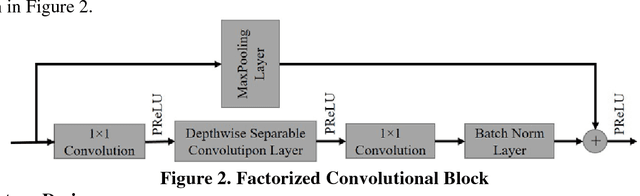
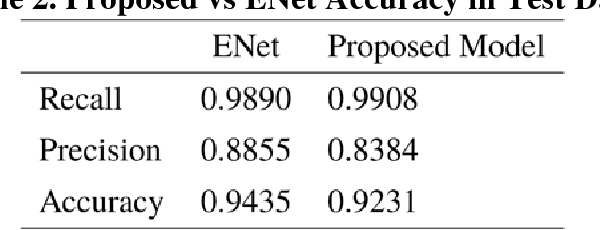
Camera-equipped unmanned vehicles (UVs) have received a lot of attention in data collection for construction monitoring applications. To develop an autonomous platform, the UV should be able to process multiple modules (e.g., context-awareness, control, localization, and mapping) on an embedded platform. Pixel-wise semantic segmentation provides a UV with the ability to be contextually aware of its surrounding environment. However, in the case of mobile robotic systems with limited computing resources, the large size of the segmentation model and high memory usage requires high computing resources, which a major challenge for mobile UVs (e.g., a small-scale vehicle with limited payload and space). To overcome this challenge, this paper presents a light and efficient deep neural network architecture to run on an embedded platform in real-time. The proposed model segments navigable space on an image sequence (i.e., a video stream), which is essential for an autonomous vehicle that is based on machine vision. The results demonstrate the performance efficiency of the proposed architecture compared to the existing models and suggest possible improvements that could make the model even more efficient, which is necessary for the future development of the autonomous robotics systems.
Learning Spatial Pyramid Attentive Pooling in Image Synthesis and Image-to-Image Translation
Jan 18, 2019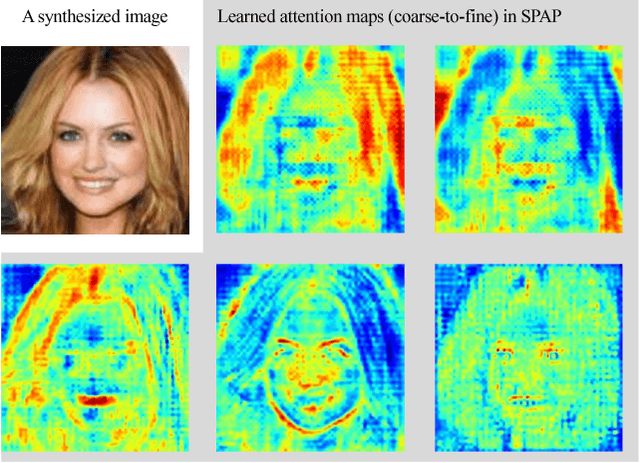
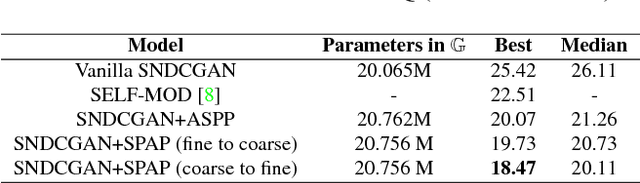
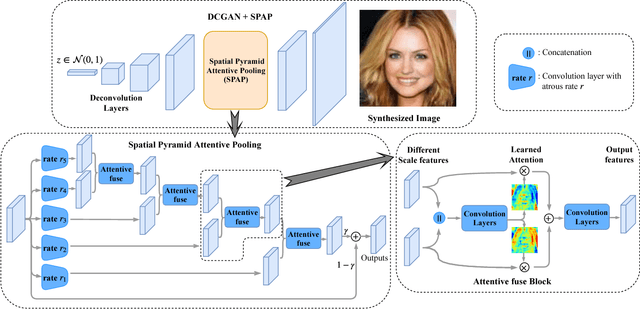
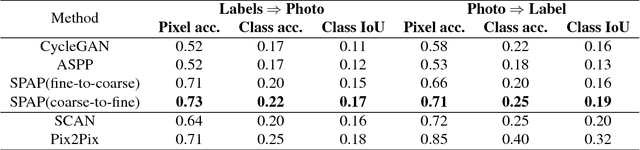
Image synthesis and image-to-image translation are two important generative learning tasks. Remarkable progress has been made by learning Generative Adversarial Networks (GANs)~\cite{goodfellow2014generative} and cycle-consistent GANs (CycleGANs)~\cite{zhu2017unpaired} respectively. This paper presents a method of learning Spatial Pyramid Attentive Pooling (SPAP) which is a novel architectural unit and can be easily integrated into both generators and discriminators in GANs and CycleGANs. The proposed SPAP integrates Atrous spatial pyramid~\cite{chen2018deeplab}, a proposed cascade attention mechanism and residual connections~\cite{he2016deep}. It leverages the advantages of the three components to facilitate effective end-to-end generative learning: (i) the capability of fusing multi-scale information by ASPP; (ii) the capability of capturing relative importance between both spatial locations (especially multi-scale context) or feature channels by attention; (iii) the capability of preserving information and enhancing optimization feasibility by residual connections. Coarse-to-fine and fine-to-coarse SPAP are studied and intriguing attention maps are observed in both tasks. In experiments, the proposed SPAP is tested in GANs on the Celeba-HQ-128 dataset~\cite{karras2017progressive}, and tested in CycleGANs on the Image-to-Image translation datasets including the Cityscape dataset~\cite{cordts2016cityscapes}, Facade and Aerial Maps dataset~\cite{zhu2017unpaired}, both obtaining better performance.
Neural Abstract Style Transfer for Chinese Traditional Painting
Dec 13, 2018

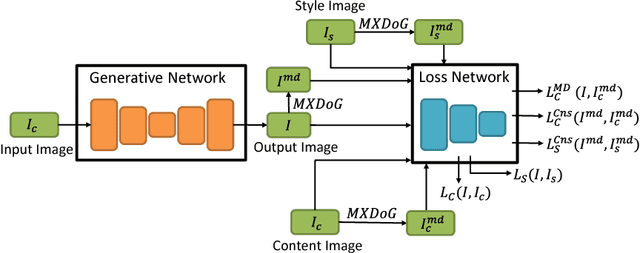

Chinese traditional painting is one of the most historical artworks in the world. It is very popular in Eastern and Southeast Asia due to being aesthetically appealing. Compared with western artistic painting, it is usually more visually abstract and textureless. Recently, neural network based style transfer methods have shown promising and appealing results which are mainly focused on western painting. It remains a challenging problem to preserve abstraction in neural style transfer. In this paper, we present a Neural Abstract Style Transfer method for Chinese traditional painting. It learns to preserve abstraction and other style jointly end-to-end via a novel MXDoG-guided filter (Modified version of the eXtended Difference-of-Gaussians) and three fully differentiable loss terms. To the best of our knowledge, there is little work study on neural style transfer of Chinese traditional painting. To promote research on this direction, we collect a new dataset with diverse photo-realistic images and Chinese traditional paintings. In experiments, the proposed method shows more appealing stylized results in transferring the style of Chinese traditional painting than state-of-the-art neural style transfer methods.
Learning Attraction Field Representation for Robust Line Segment Detection
Dec 05, 2018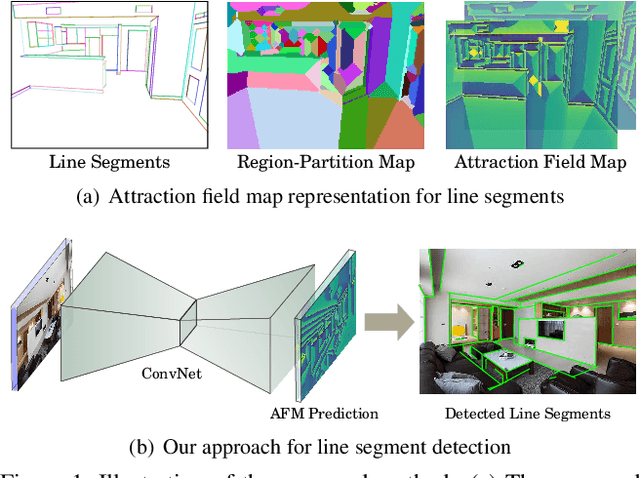

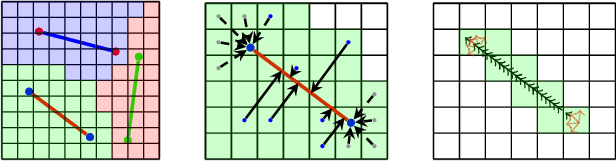
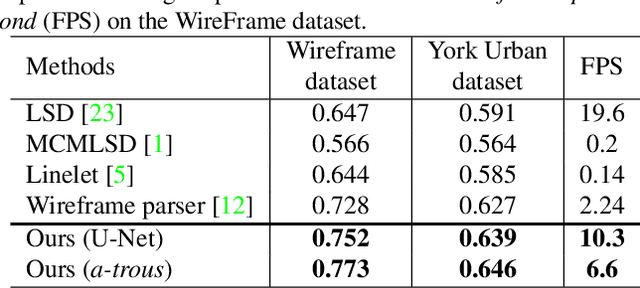
This paper presents a region-partition based attraction field dual representation for line segment maps, and thus poses the problem of line segment detection (LSD) as the region coloring problem. The latter is then addressed by learning deep convolutional neural networks (ConvNets) for accuracy, robustness and efficiency. For a 2D line segment map, our dual representation consists of three components: (i) A region-partition map in which every pixel is assigned to one and only one line segment; (ii) An attraction field map in which every pixel in a partition region is encoded by its 2D projection vector w.r.t. the associated line segment; and (iii) A squeeze module which squashes the attraction field to a line segment map that almost perfectly recovers the input one. By leveraging the duality, we learn ConvNets to compute the attraction field maps for raw in-put images, followed by the squeeze module for LSD, in an end-to-end manner. Our method rigorously addresses several challenges in LSD such as local ambiguity and class imbalance. Our method also harnesses the best practices developed in ConvNets based semantic segmentation methods such as the encoder-decoder architecture and the a-trous convolution. In experiments, our method is tested on the WireFrame dataset and the YorkUrban dataset with state-of-the-art performance obtained. Especially, we advance the performance by 4.5 percents on the WireFrame dataset. Our method is also fast with 6.6~10.4 FPS, outperforming most of existing line segment detectors.
Relational Long Short-Term Memory for Video Action Recognition
Nov 16, 2018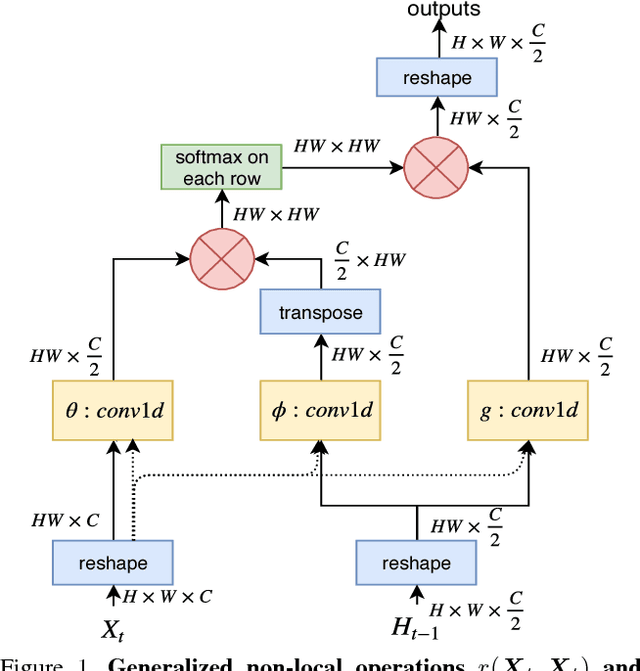
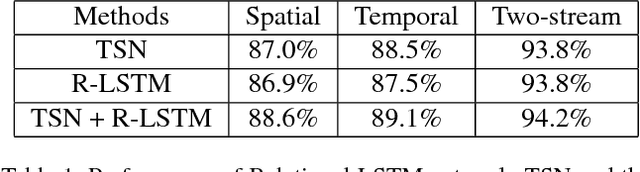
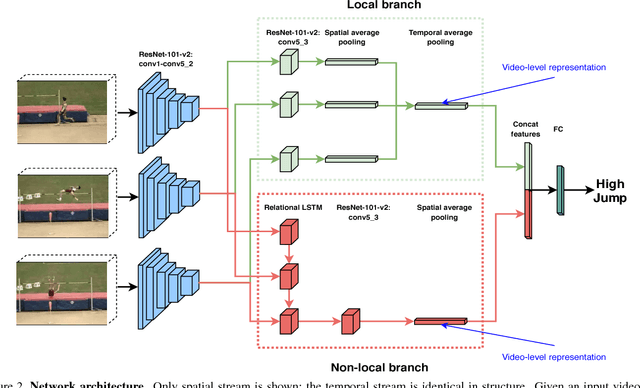
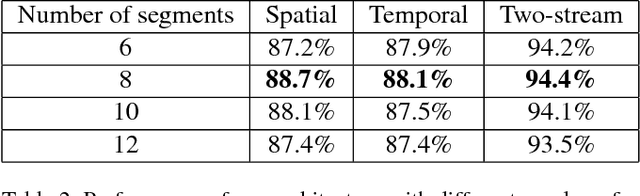
Spatial and temporal relationships, both short-range and long-range, between objects in videos are key cues for recognizing actions. It is a challenging problem to model them jointly. In this paper, we first present a new variant of Long Short-Term Memory, namely Relational LSTM to address the challenge for relation reasoning across space and time between objects. In our Relational LSTM module, we utilize a non-local operation similar in spirit to the recently proposed non-local network to substitute the fully connected operation in the vanilla LSTM. By doing this, our Relational LSTM is capable of capturing long and short-range spatio-temporal relations between objects in videos in a principled way. Then, we propose a two-branch neural architecture consisting of the Relational LSTM module as the non-local branch and a spatio-temporal pooling based local branch. The local branch is introduced for capturing local spatial appearance and/or short-term motion features. The two-branch modules are concatenated to learn video-level features from snippet-level ones end-to-end. Experimental results on UCF-101 and HMDB-51 datasets show that our model achieves state-of-the-art results among LSTM-based methods, while obtaining comparable performance with other state-of-the-art methods (which use not directly comparable schema). Our code will be released.
ARCHER: Aggressive Rewards to Counter bias in Hindsight Experience Replay
Sep 07, 2018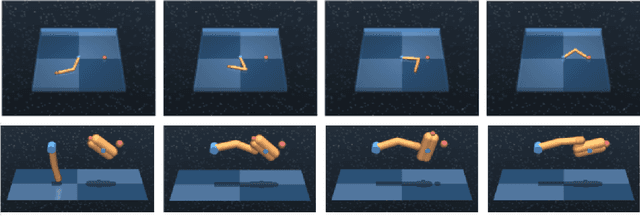
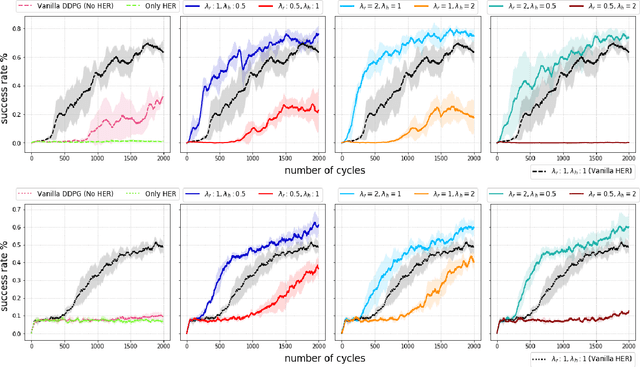
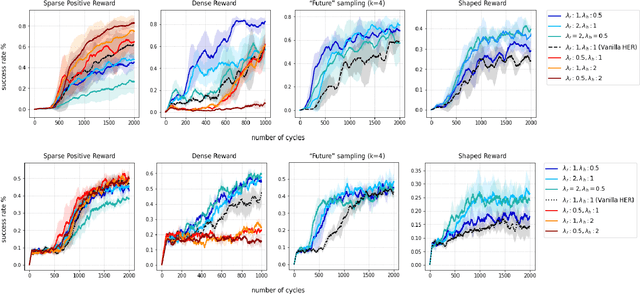
Experience replay is an important technique for addressing sample-inefficiency in deep reinforcement learning (RL), but faces difficulty in learning from binary and sparse rewards due to disproportionately few successful experiences in the replay buffer. Hindsight experience replay (HER) was recently proposed to tackle this difficulty by manipulating unsuccessful transitions, but in doing so, HER introduces a significant bias in the replay buffer experiences and therefore achieves a suboptimal improvement in sample-efficiency. In this paper, we present an analysis on the source of bias in HER, and propose a simple and effective method to counter the bias, to most effectively harness the sample-efficiency provided by HER. Our method, motivated by counter-factual reasoning and called ARCHER, extends HER with a trade-off to make rewards calculated for hindsight experiences numerically greater than real rewards. We validate our algorithm on two continuous control environments from DeepMind Control Suite - Reacher and Finger, which simulate manipulation tasks with a robotic arm - in combination with various reward functions, task complexities and goal sampling strategies. Our experiments consistently demonstrate that countering bias using more aggressive hindsight rewards increases sample efficiency, thus establishing the greater benefit of ARCHER in RL applications with limited computing budget.
Towards Interpretable R-CNN by Unfolding Latent Structures
Sep 06, 2018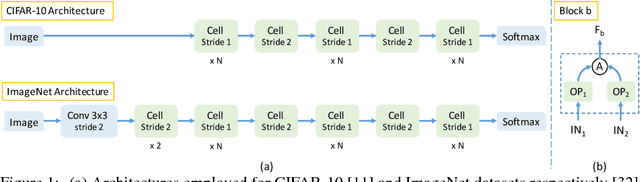
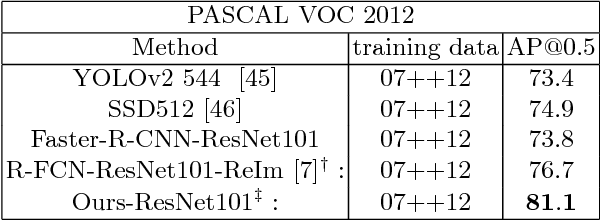
This paper first proposes a method of formulating model interpretability in visual understanding tasks based on the idea of unfolding latent structures. It then presents a case study in object detection using popular two-stage region-based convolutional network (i.e., R-CNN) detection systems. We focus on weakly-supervised extractive rationale generation, that is learning to unfold latent discriminative part configurations of object instances automatically and simultaneously in detection without using any supervision for part configurations. We utilize a top-down hierarchical and compositional grammar model embedded in a directed acyclic AND-OR Graph (AOG) to explore and unfold the space of latent part configurations of regions of interest (RoIs). We propose an AOGParsing operator to substitute the RoIPooling operator widely used in R-CNN. In detection, a bounding box is interpreted by the best parse tree derived from the AOG on-the-fly, which is treated as the qualitatively extractive rationale generated for interpreting detection. We propose a folding-unfolding method to train the AOG and convolutional networks end-to-end. In experiments, we build on R-FCN and test our method on the PASCAL VOC 2007 and 2012 datasets. We show that the method can unfold promising latent structures without hurting the performance.
Auto-Context R-CNN
Jul 08, 2018
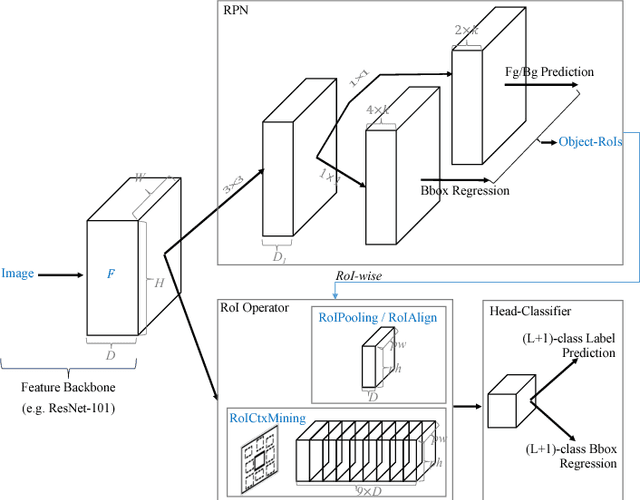
Region-based convolutional neural networks (R-CNN)~\cite{fast_rcnn,faster_rcnn,mask_rcnn} have largely dominated object detection. Operators defined on RoIs (Region of Interests) play an important role in R-CNNs such as RoIPooling~\cite{fast_rcnn} and RoIAlign~\cite{mask_rcnn}. They all only utilize information inside RoIs for RoI prediction, even with their recent deformable extensions~\cite{deformable_cnn}. Although surrounding context is well-known for its importance in object detection, it has yet been integrated in R-CNNs in a flexible and effective way. Inspired by the auto-context work~\cite{auto_context} and the multi-class object layout work~\cite{nms_context}, this paper presents a generic context-mining RoI operator (i.e., \textit{RoICtxMining}) seamlessly integrated in R-CNNs, and the resulting object detection system is termed \textbf{Auto-Context R-CNN} which is trained end-to-end. The proposed RoICtxMining operator is a simple yet effective two-layer extension of the RoIPooling or RoIAlign operator. Centered at an object-RoI, it creates a $3\times 3$ layout to mine contextual information adaptively in the $8$ surrounding context regions on-the-fly. Within each of the $8$ context regions, a context-RoI is mined in term of discriminative power and its RoIPooling / RoIAlign features are concatenated with the object-RoI for final prediction. \textit{The proposed Auto-Context R-CNN is robust to occlusion and small objects, and shows promising vulnerability for adversarial attacks without being adversarially-trained.} In experiments, it is evaluated using RoIPooling as the backbone and shows competitive results on Pascal VOC, Microsoft COCO, and KITTI datasets (including $6.9\%$ mAP improvements over the R-FCN~\cite{rfcn} method on COCO \textit{test-dev} dataset and the first place on both KITTI pedestrian and cyclist detection as of this submission).
Building an Integrated Mobile Robotic System for Real-Time Applications in Construction
Apr 18, 2018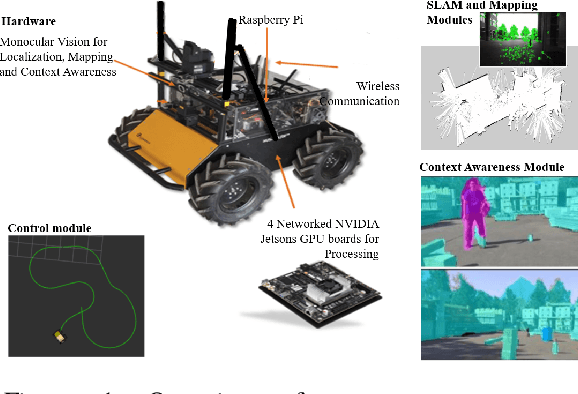
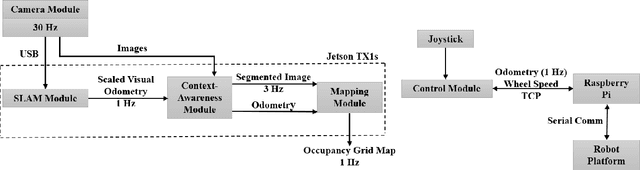

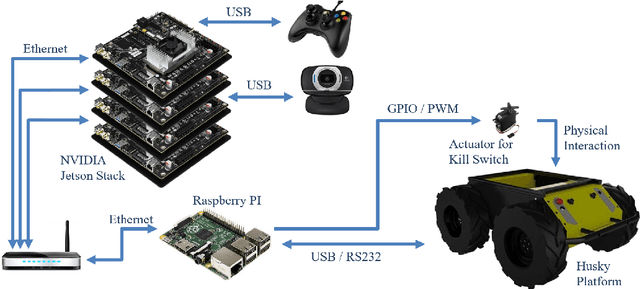
One of the major challenges of a real-time autonomous robotic system for construction monitoring is to simultaneously localize, map, and navigate over the lifetime of the robot, with little or no human intervention. Past research on Simultaneous Localization and Mapping (SLAM) and context-awareness are two active research areas in the computer vision and robotics communities. The studies that integrate both in real-time into a single modular framework for construction monitoring still need further investigation. A monocular vision system and real-time scene understanding are computationally heavy and the major state-of-the-art algorithms are tested on high-end desktops and/or servers with a high CPU- and/or GPU- computing capabilities, which affect their mobility and deployment for real-world applications. To address these challenges and achieve automation, this paper proposes an integrated robotic computer vision system, which generates a real-world spatial map of the obstacles and traversable space present in the environment in near real-time. This is done by integrating contextual Awareness and visual SLAM into a ground robotics agent. This paper presents the hardware utilization and performance of the aforementioned system for three different outdoor environments, which represent the applicability of this pipeline to diverse outdoor scenes in near real-time. The entire system is also self-contained and does not require user input, which demonstrates the potential of this computer vision system for autonomous navigation.
Scene-centric Joint Parsing of Cross-view Videos
Feb 05, 2018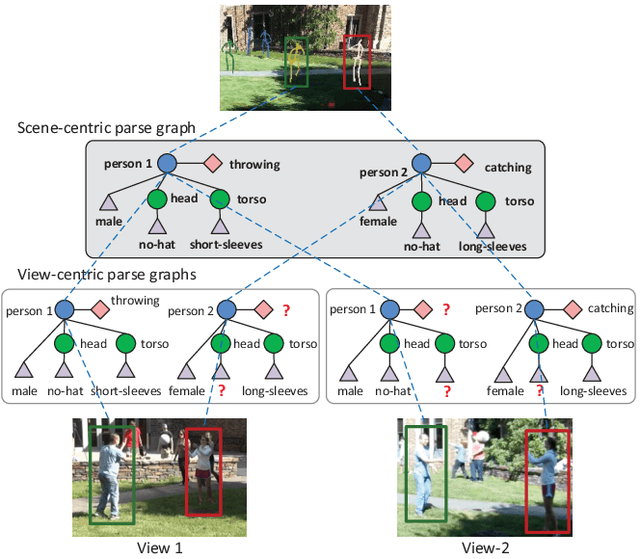
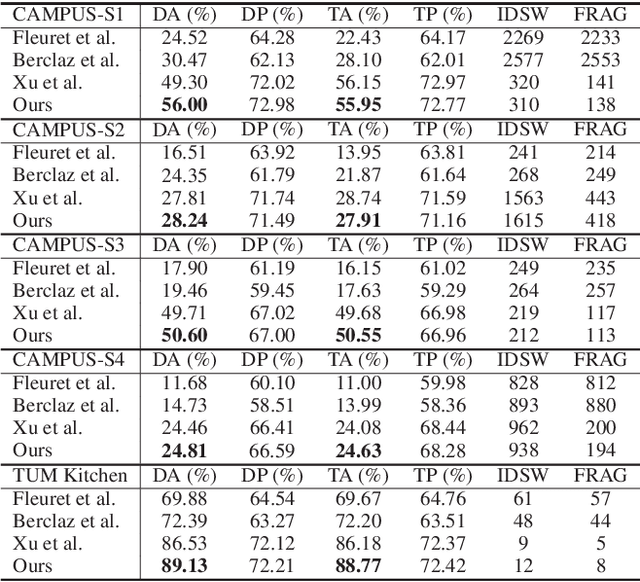
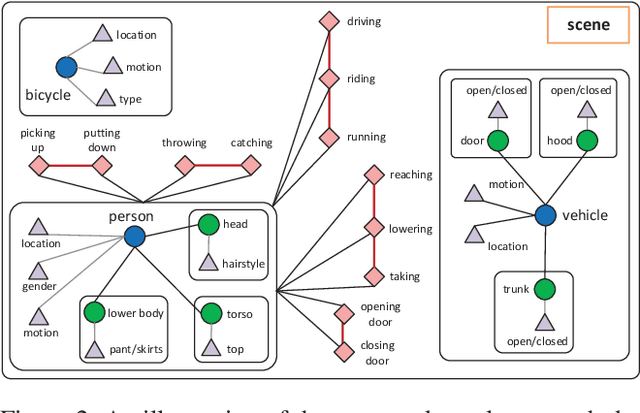

Cross-view video understanding is an important yet under-explored area in computer vision. In this paper, we introduce a joint parsing framework that integrates view-centric proposals into scene-centric parse graphs that represent a coherent scene-centric understanding of cross-view scenes. Our key observations are that overlapping fields of views embed rich appearance and geometry correlations and that knowledge fragments corresponding to individual vision tasks are governed by consistency constraints available in commonsense knowledge. The proposed joint parsing framework represents such correlations and constraints explicitly and generates semantic scene-centric parse graphs. Quantitative experiments show that scene-centric predictions in the parse graph outperform view-centric predictions.