 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Inference in Discrete Distributions with Monte Carlo Tree Search and Value Functions
Oct 15, 2019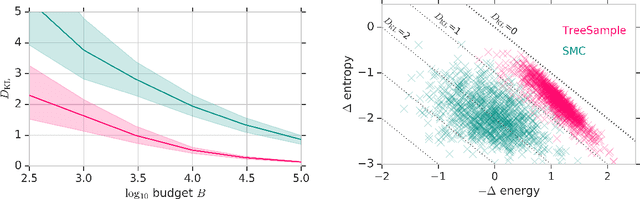

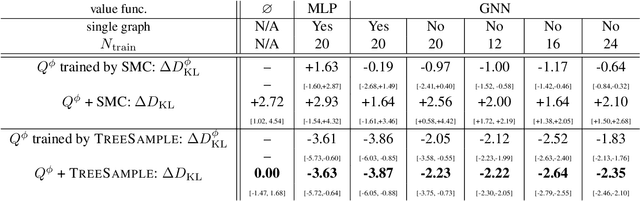
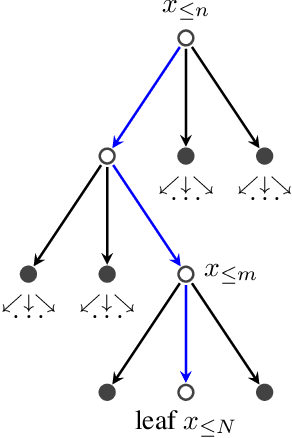
A plethora of problems in AI, engineering and the sciences are naturally formalized as inference in discrete probabilistic models. Exact inference is often prohibitively expensive, as it may require evaluating the (unnormalized) target density on its entire domain. Here we consider the setting where only a limited budget of calls to the unnormalized density oracle is available, raising the challenge of where in the domain to allocate these function calls in order to construct a good approximate solution. We formulate this problem as an instance of sequential decision-making under uncertainty and leverage methods from reinforcement learning for probabilistic inference with budget constraints. In particular, we propose the TreeSample algorithm, an adaptation of Monte Carlo Tree Search to approximate inference. This algorithm caches all previous queries to the density oracle in an explicit search tree, and dynamically allocates new queries based on a "best-first" heuristic for exploration, using existing upper confidence bound methods. Our non-parametric inference method can be effectively combined with neural networks that compile approximate conditionals of the target, which are then used to guide the inference search and enable generalization across multiple target distributions. We show empirically that TreeSample outperforms standard approximate inference methods on synthetic factor graphs.
Unsupervised Doodling and Painting with Improved SPIRAL
Oct 02, 2019
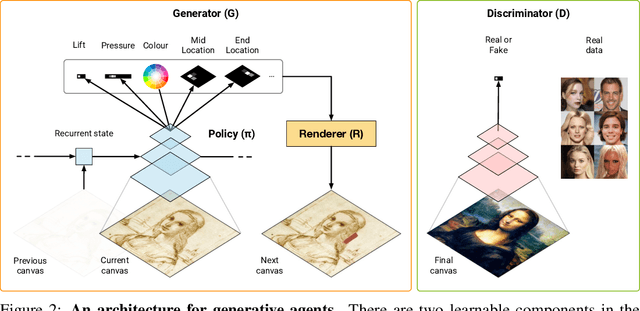


We investigate using reinforcement learning agents as generative models of images (extending arXiv:1804.01118). A generative agent controls a simulated painting environment, and is trained with rewards provided by a discriminator network simultaneously trained to assess the realism of the agent's samples, either unconditional or reconstructions. Compared to prior work, we make a number of improvements to the architectures of the agents and discriminators that lead to intriguing and at times surprising results. We find that when sufficiently constrained, generative agents can learn to produce images with a degree of visual abstraction, despite having only ever seen real photographs (no human brush strokes). And given enough time with the painting environment, they can produce images with considerable realism. These results show that, under the right circumstances, some aspects of human drawing can emerge from simulated embodiment, without the need for external supervision, imitation or social cues. Finally, we note the framework's potential for use in creative applications.
Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search
Nov 15, 2018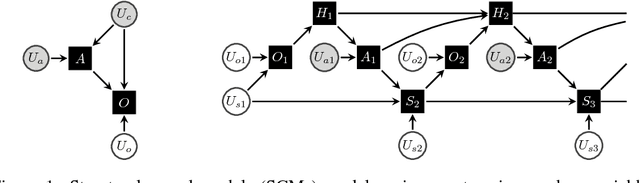
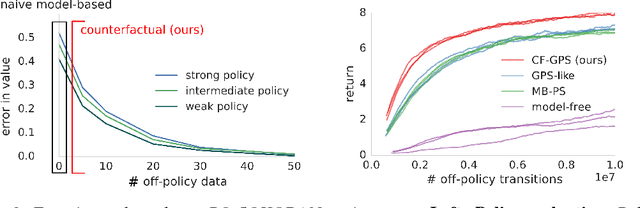
Learning policies on data synthesized by models can in principle quench the thirst of reinforcement learning algorithms for large amounts of real experience, which is often costly to acquire. However, simulating plausible experience de novo is a hard problem for many complex environments, often resulting in biases for model-based policy evaluation and search. Instead of de novo synthesis of data, here we assume logged, real experience and model alternative outcomes of this experience under counterfactual actions, actions that were not actually taken. Based on this, we propose the Counterfactually-Guided Policy Search (CF-GPS) algorithm for learning policies in POMDPs from off-policy experience. It leverages structural causal models for counterfactual evaluation of arbitrary policies on individual off-policy episodes. CF-GPS can improve on vanilla model-based RL algorithms by making use of available logged data to de-bias model predictions. In contrast to off-policy algorithms based on Importance Sampling which re-weight data, CF-GPS leverages a model to explicitly consider alternative outcomes, allowing the algorithm to make better use of experience data. We find empirically that these advantages translate into improved policy evaluation and search results on a non-trivial grid-world task. Finally, we show that CF-GPS generalizes the previously proposed Guided Policy Search and that reparameterization-based algorithms such Stochastic Value Gradient can be interpreted as counterfactual methods.
Relational recurrent neural networks
Jun 28, 2018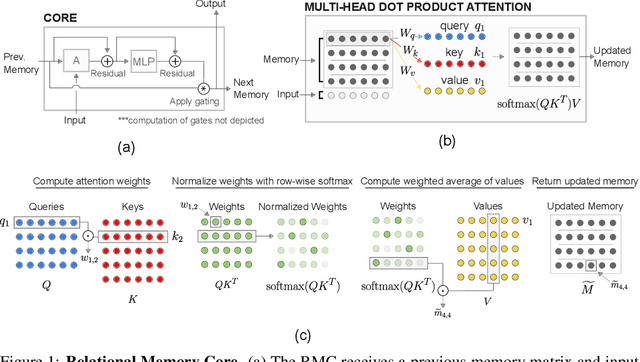
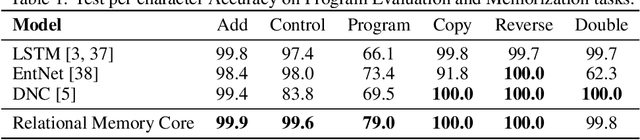
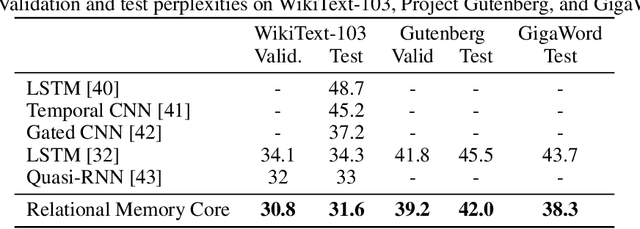
Memory-based neural networks model temporal data by leveraging an ability to remember information for long periods. It is unclear, however, whether they also have an ability to perform complex relational reasoning with the information they remember. Here, we first confirm our intuitions that standard memory architectures may struggle at tasks that heavily involve an understanding of the ways in which entities are connected -- i.e., tasks involving relational reasoning. We then improve upon these deficits by using a new memory module -- a \textit{Relational Memory Core} (RMC) -- which employs multi-head dot product attention to allow memories to interact. Finally, we test the RMC on a suite of tasks that may profit from more capable relational reasoning across sequential information, and show large gains in RL domains (e.g. Mini PacMan), program evaluation, and language modeling, achieving state-of-the-art results on the WikiText-103, Project Gutenberg, and GigaWord datasets.
Learning and Querying Fast Generative Models for Reinforcement Learning
Feb 08, 2018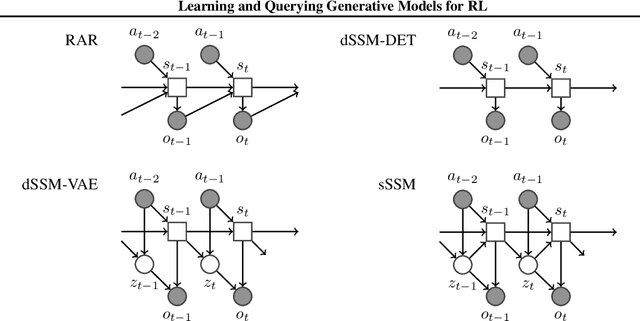

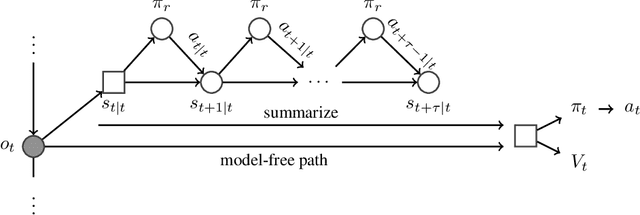
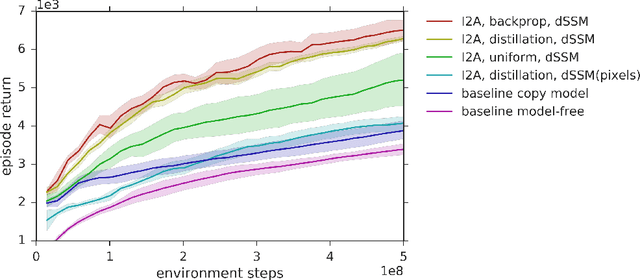
A key challenge in model-based reinforcement learning (RL) is to synthesize computationally efficient and accurate environment models. We show that carefully designed generative models that learn and operate on compact state representations, so-called state-space models, substantially reduce the computational costs for predicting outcomes of sequences of actions. Extensive experiments establish that state-space models accurately capture the dynamics of Atari games from the Arcade Learning Environment from raw pixels. The computational speed-up of state-space models while maintaining high accuracy makes their application in RL feasible: We demonstrate that agents which query these models for decision making outperform strong model-free baselines on the game MSPACMAN, demonstrating the potential of using learned environment models for planning.
Visual Interaction Networks
Jun 05, 2017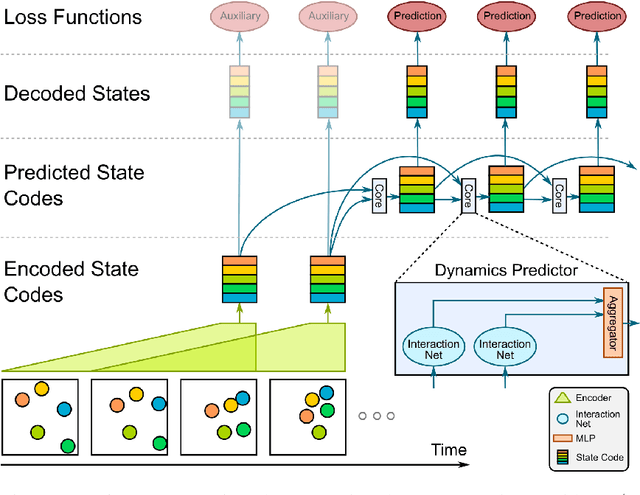

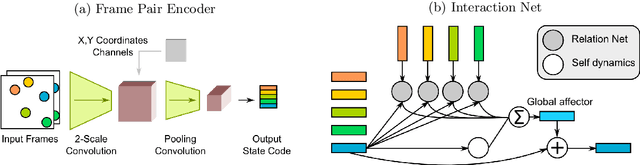
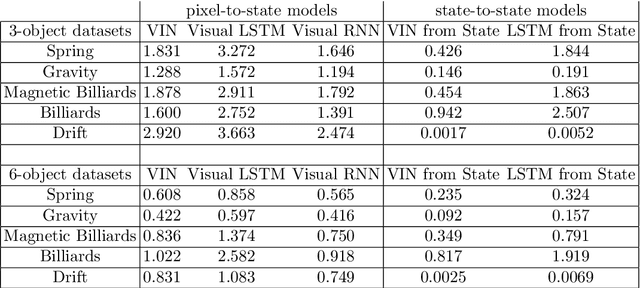
From just a glance, humans can make rich predictions about the future state of a wide range of physical systems. On the other hand, modern approaches from engineering, robotics, and graphics are often restricted to narrow domains and require direct measurements of the underlying states. We introduce the Visual Interaction Network, a general-purpose model for learning the dynamics of a physical system from raw visual observations. Our model consists of a perceptual front-end based on convolutional neural networks and a dynamics predictor based on interaction networks. Through joint training, the perceptual front-end learns to parse a dynamic visual scene into a set of factored latent object representations. The dynamics predictor learns to roll these states forward in time by computing their interactions and dynamics, producing a predicted physical trajectory of arbitrary length. We found that from just six input video frames the Visual Interaction Network can generate accurate future trajectories of hundreds of time steps on a wide range of physical systems. Our model can also be applied to scenes with invisible objects, inferring their future states from their effects on the visible objects, and can implicitly infer the unknown mass of objects. Our results demonstrate that the perceptual module and the object-based dynamics predictor module can induce factored latent representations that support accurate dynamical predictions. This work opens new opportunities for model-based decision-making and planning from raw sensory observations in complex physical environments.
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
Aug 12, 2016
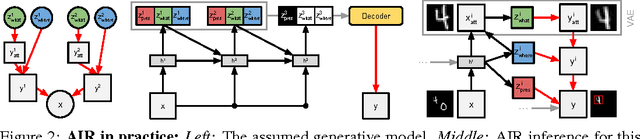

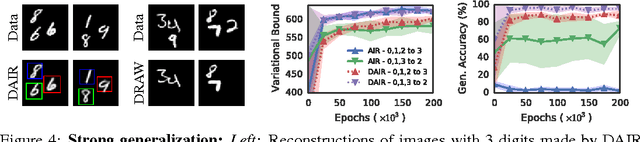
We present a framework for efficient inference in structured image models that explicitly reason about objects. We achieve this by performing probabilistic inference using a recurrent neural network that attends to scene elements and processes them one at a time. Crucially, the model itself learns to choose the appropriate number of inference steps. We use this scheme to learn to perform inference in partially specified 2D models (variable-sized variational auto-encoders) and fully specified 3D models (probabilistic renderers). We show that such models learn to identify multiple objects - counting, locating and classifying the elements of a scene - without any supervision, e.g., decomposing 3D images with various numbers of objects in a single forward pass of a neural network. We further show that the networks produce accurate inferences when compared to supervised counterparts, and that their structure leads to improved generalization.
Deep Reinforcement Learning in Large Discrete Action Spaces
Apr 04, 2016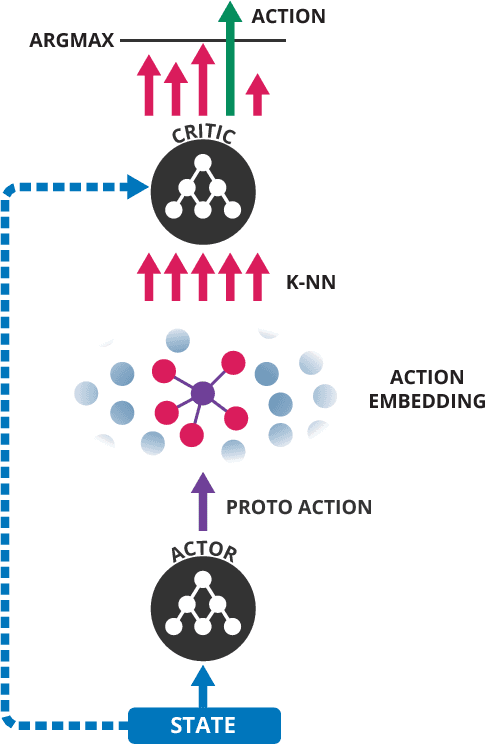

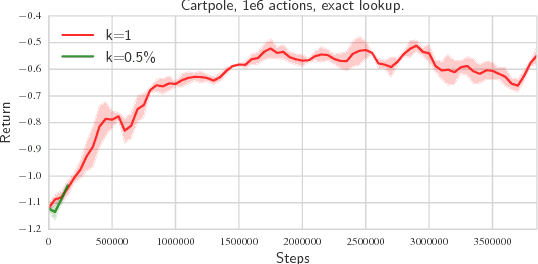
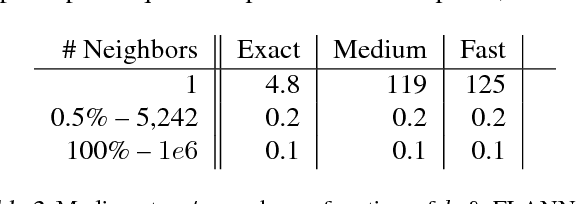
Being able to reason in an environment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-world tasks involving large numbers of discrete actions for which current methods are difficult or even often impossible to apply. An ability to generalize over the set of actions as well as sub-linear complexity relative to the size of the set are both necessary to handle such tasks. Current approaches are not able to provide both of these, which motivates the work in this paper. Our proposed approach leverages prior information about the actions to embed them in a continuous space upon which it can generalize. Additionally, approximate nearest-neighbor methods allow for logarithmic-time lookup complexity relative to the number of actions, which is necessary for time-wise tractable training. This combined approach allows reinforcement learning methods to be applied to large-scale learning problems previously intractable with current methods. We demonstrate our algorithm's abilities on a series of tasks having up to one million actions.
Gradient Estimation Using Stochastic Computation Graphs
Jan 05, 2016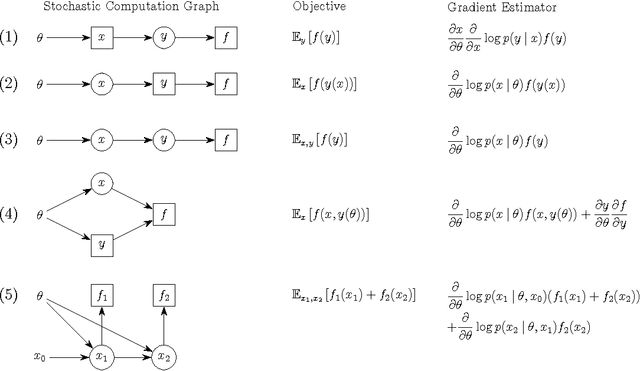
In a variety of problems originating in supervised, unsupervised, and reinforcement learning, the loss function is defined by an expectation over a collection of random variables, which might be part of a probabilistic model or the external world. Estimating the gradient of this loss function, using samples, lies at the core of gradient-based learning algorithms for these problems. We introduce the formalism of stochastic computation graphs---directed acyclic graphs that include both deterministic functions and conditional probability distributions---and describe how to easily and automatically derive an unbiased estimator of the loss function's gradient. The resulting algorithm for computing the gradient estimator is a simple modification of the standard backpropagation algorithm. The generic scheme we propose unifies estimators derived in variety of prior work, along with variance-reduction techniques therein. It could assist researchers in developing intricate models involving a combination of stochastic and deterministic operations, enabling, for example, attention, memory, and control actions.
Automated Variational Inference in Probabilistic Programming
Jan 07, 2013
We present a new algorithm for approximate inference in probabilistic programs, based on a stochastic gradient for variational programs. This method is efficient without restrictions on the probabilistic program; it is particularly practical for distributions which are not analytically tractable, including highly structured distributions that arise in probabilistic programs. We show how to automatically derive mean-field probabilistic programs and optimize them, and demonstrate that our perspective improves inference efficiency over other algorithms.