 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehending and Ordering Semantics for Image Captioning
Jun 14, 2022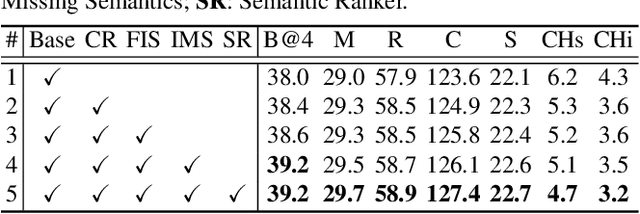
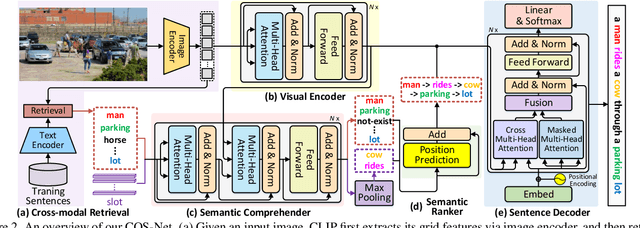
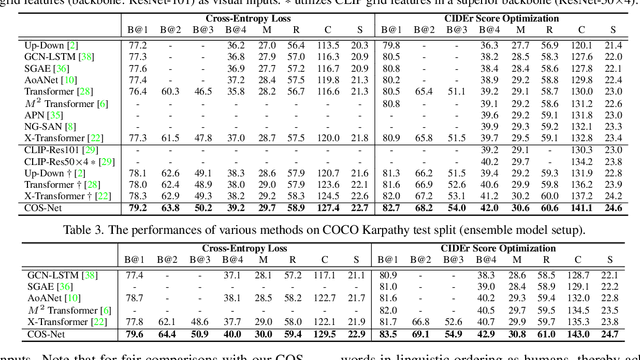
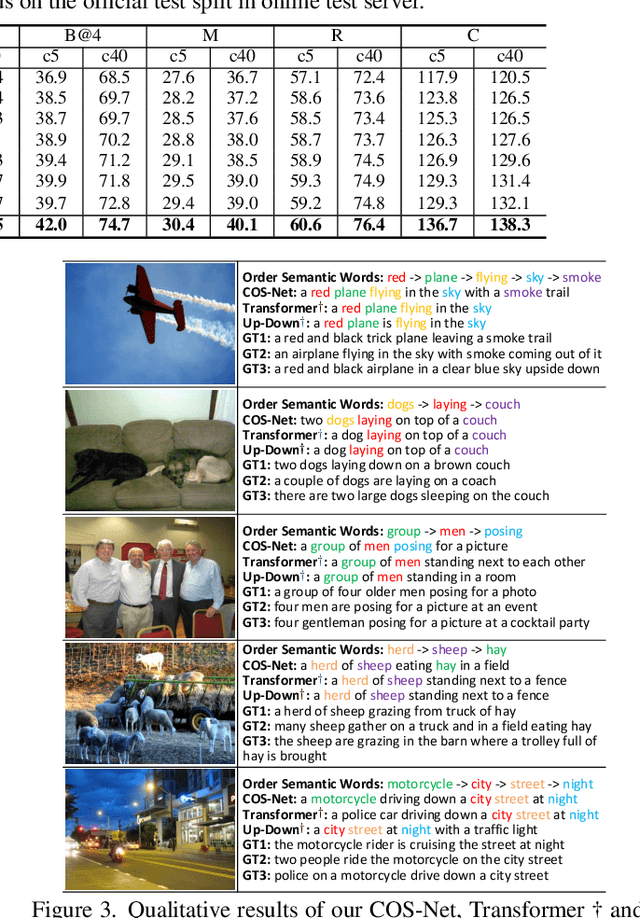
Comprehending the rich semantics in an image and ordering them in linguistic order are essential to compose a visually-grounded and linguistically coherent description for image captioning. Modern techniques commonly capitalize on a pre-trained object detector/classifier to mine the semantics in an image, while leaving the inherent linguistic ordering of semantics under-exploited. In this paper, we propose a new recipe of Transformer-style structure, namely Comprehending and Ordering Semantics Networks (COS-Net), that novelly unifies an enriched semantic comprehending and a learnable semantic ordering processes into a single architecture. Technically, we initially utilize a cross-modal retrieval model to search the relevant sentences of each image, and all words in the searched sentences are taken as primary semantic cues. Next, a novel semantic comprehender is devised to filter out the irrelevant semantic words in primary semantic cues, and meanwhile infer the missing relevant semantic words visually grounded in the image. After that, we feed all the screened and enriched semantic words into a semantic ranker, which learns to allocate all semantic words in linguistic order as humans. Such sequence of ordered semantic words are further integrated with visual tokens of images to trigger sentence generation. Empirical evidences show that COS-Net clearly surpasses the state-of-the-art approaches on COCO and achieves to-date the best CIDEr score of 141.1% on Karpathy test split. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/cosnet}.
MLP-3D: A MLP-like 3D Architecture with Grouped Time Mixing
Jun 13, 2022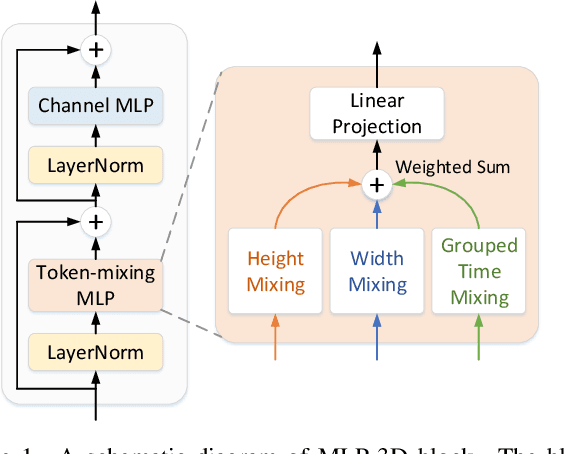
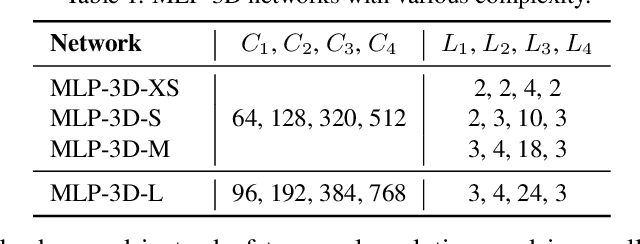

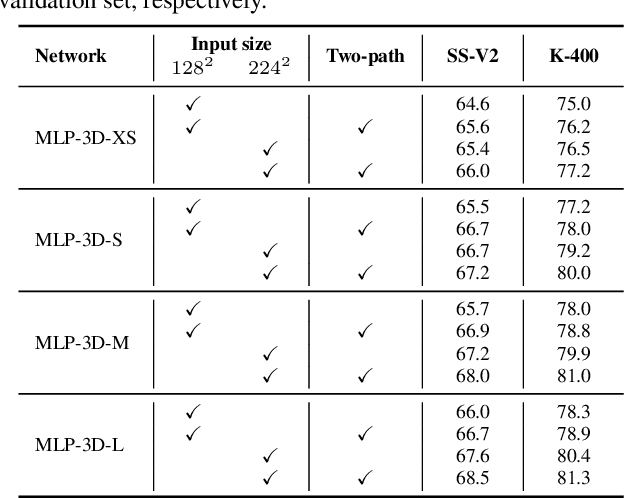
Convolutional Neural Networks (CNNs) have been regarded as the go-to models for visual recognition. More recently, convolution-free networks, based on multi-head self-attention (MSA) or multi-layer perceptrons (MLPs), become more and more popular. Nevertheless, it is not trivial when utilizing these newly-minted networks for video recognition due to the large variations and complexities in video data. In this paper, we present MLP-3D networks, a novel MLP-like 3D architecture for video recognition. Specifically, the architecture consists of MLP-3D blocks, where each block contains one MLP applied across tokens (i.e., token-mixing MLP) and one MLP applied independently to each token (i.e., channel MLP). By deriving the novel grouped time mixing (GTM) operations, we equip the basic token-mixing MLP with the ability of temporal modeling. GTM divides the input tokens into several temporal groups and linearly maps the tokens in each group with the shared projection matrix. Furthermore, we devise several variants of GTM with different grouping strategies, and compose each variant in different blocks of MLP-3D network by greedy architecture search. Without the dependence on convolutions or attention mechanisms, our MLP-3D networks achieves 68.5\%/81.4\% top-1 accuracy on Something-Something V2 and Kinetics-400 datasets, respectively. Despite with fewer computations, the results are comparable to state-of-the-art widely-used 3D CNNs and video transformers. Source code is available at https://github.com/ZhaofanQiu/MLP-3D.
Exploring Structure-aware Transformer over Interaction Proposals for Human-Object Interaction Detection
Jun 13, 2022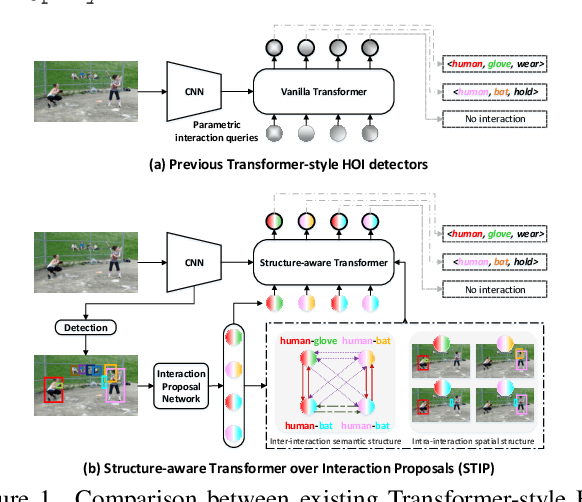
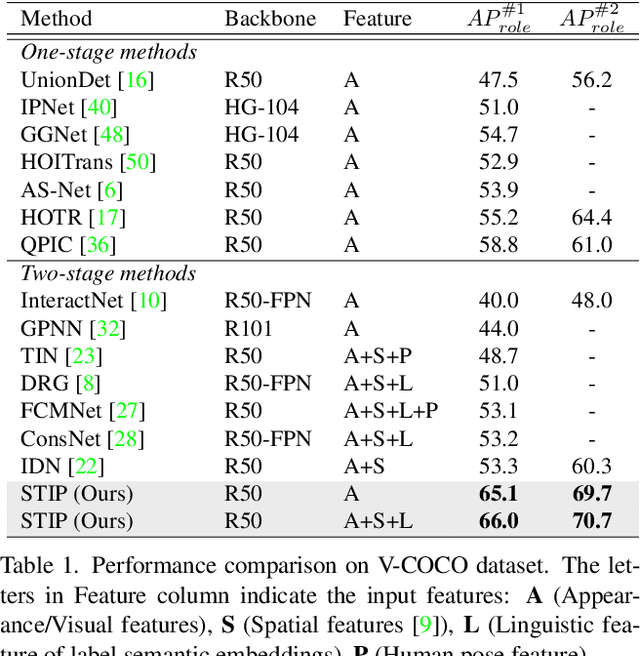
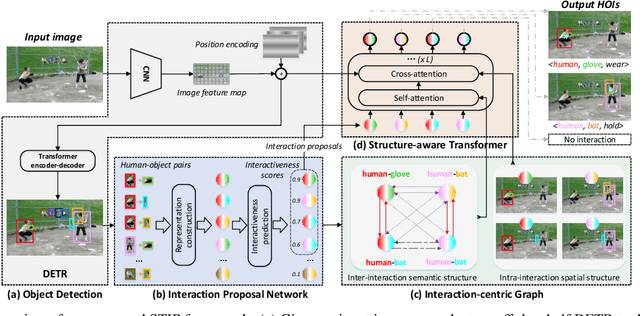
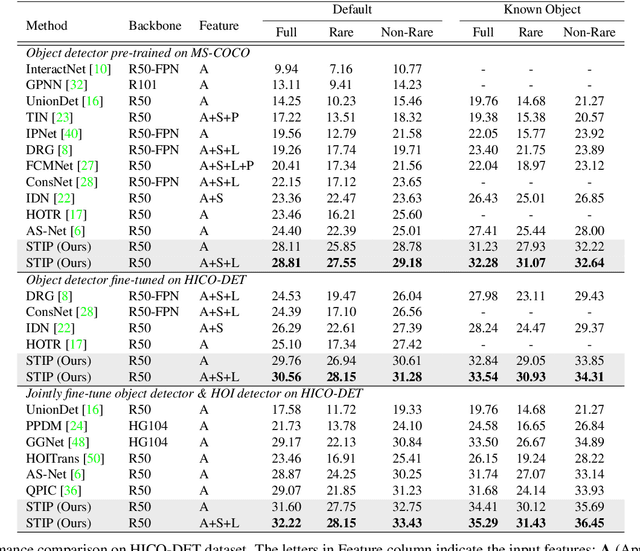
Recent high-performing Human-Object Interaction (HOI) detection techniques have been highly influenced by Transformer-based object detector (i.e., DETR). Nevertheless, most of them directly map parametric interaction queries into a set of HOI predictions through vanilla Transformer in a one-stage manner. This leaves rich inter- or intra-interaction structure under-exploited. In this work, we design a novel Transformer-style HOI detector, i.e., Structure-aware Transformer over Interaction Proposals (STIP), for HOI detection. Such design decomposes the process of HOI set prediction into two subsequent phases, i.e., an interaction proposal generation is first performed, and then followed by transforming the non-parametric interaction proposals into HOI predictions via a structure-aware Transformer. The structure-aware Transformer upgrades vanilla Transformer by encoding additionally the holistically semantic structure among interaction proposals as well as the locally spatial structure of human/object within each interaction proposal, so as to strengthen HOI predictions. Extensive experiments conducted on V-COCO and HICO-DET benchmarks have demonstrated the effectiveness of STIP, and superior results are reported when comparing with the state-of-the-art HOI detectors. Source code is available at \url{https://github.com/zyong812/STIP}.
Silver-Bullet-3D at ManiSkill 2021: Learning-from-Demonstrations and Heuristic Rule-based Methods for Object Manipulation
Jun 13, 2022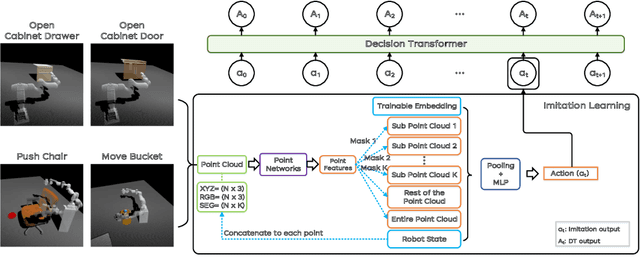



This paper presents an overview and comparative analysis of our systems designed for the following two tracks in SAPIEN ManiSkill Challenge 2021: No Interaction Track: The No Interaction track targets for learning policies from pre-collected demonstration trajectories. We investigate both imitation learning-based approach, i.e., imitating the observed behavior using classical supervised learning techniques, and offline reinforcement learning-based approaches, for this track. Moreover, the geometry and texture structures of objects and robotic arms are exploited via Transformer-based networks to facilitate imitation learning. No Restriction Track: In this track, we design a Heuristic Rule-based Method (HRM) to trigger high-quality object manipulation by decomposing the task into a series of sub-tasks. For each sub-task, the simple rule-based controlling strategies are adopted to predict actions that can be applied to robotic arms. To ease the implementations of our systems, all the source codes and pre-trained models are available at \url{https://github.com/caiqi/Silver-Bullet-3D/}.
Structured Two-stream Attention Network for Video Question Answering
Jun 02, 2022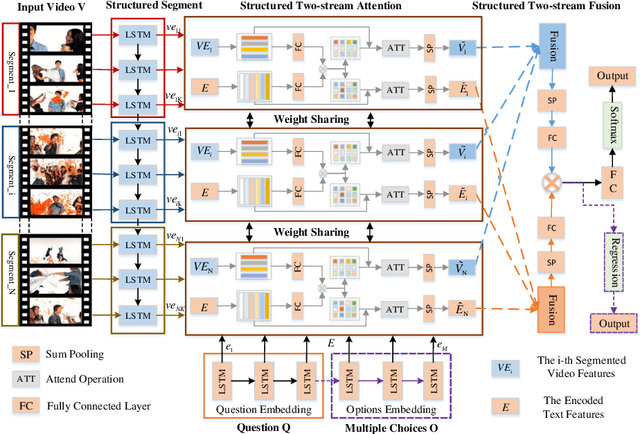
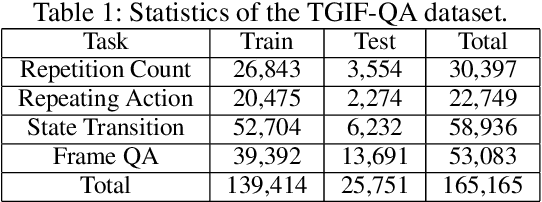
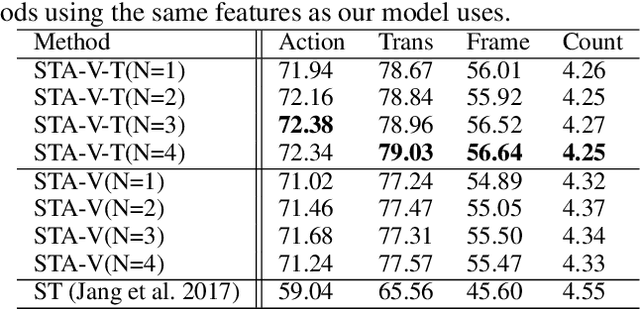

To date, visual question answering (VQA) (i.e., image QA and video QA) is still a holy grail in vision and language understanding, especially for video QA. Compared with image QA that focuses primarily on understanding the associations between image region-level details and corresponding questions, video QA requires a model to jointly reason across both spatial and long-range temporal structures of a video as well as text to provide an accurate answer. In this paper, we specifically tackle the problem of video QA by proposing a Structured Two-stream Attention network, namely STA, to answer a free-form or open-ended natural language question about the content of a given video. First, we infer rich long-range temporal structures in videos using our structured segment component and encode text features. Then, our structured two-stream attention component simultaneously localizes important visual instance, reduces the influence of background video and focuses on the relevant text. Finally, the structured two-stream fusion component incorporates different segments of query and video aware context representation and infers the answers. Experiments on the large-scale video QA dataset \textit{TGIF-QA} show that our proposed method significantly surpasses the best counterpart (i.e., with one representation for the video input) by 13.0%, 13.5%, 11.0% and 0.3 for Action, Trans., TrameQA and Count tasks. It also outperforms the best competitor (i.e., with two representations) on the Action, Trans., TrameQA tasks by 4.1%, 4.7%, and 5.1%.
Gait Recognition in the Wild with Dense 3D Representations and A Benchmark
Apr 06, 2022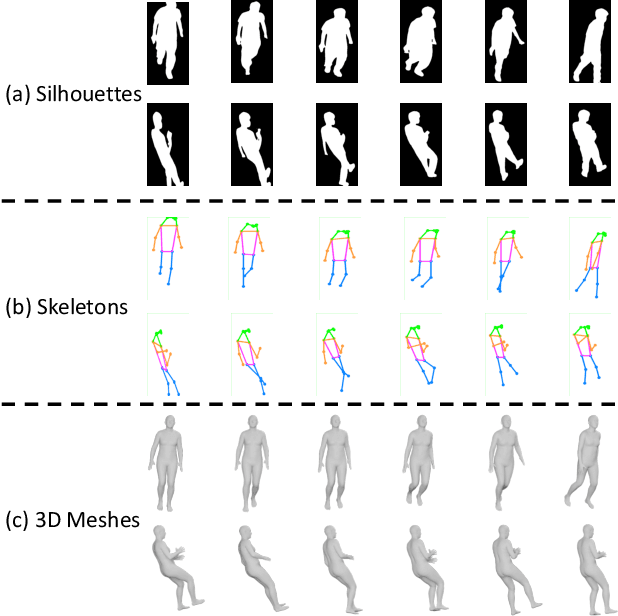
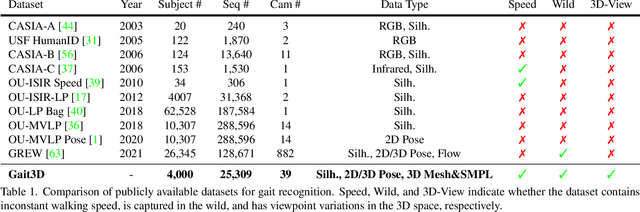
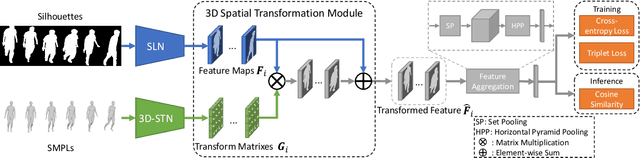
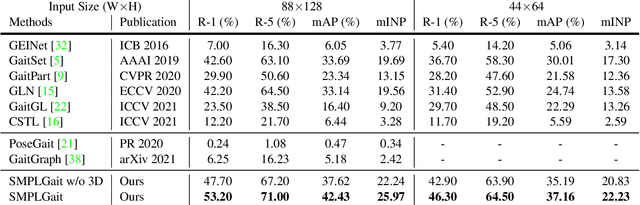
Existing studies for gait recognition are dominated by 2D representations like the silhouette or skeleton of the human body in constrained scenes. However, humans live and walk in the unconstrained 3D space, so projecting the 3D human body onto the 2D plane will discard a lot of crucial information like the viewpoint, shape, and dynamics for gait recognition. Therefore, this paper aims to explore dense 3D representations for gait recognition in the wild, which is a practical yet neglected problem. In particular, we propose a novel framework to explore the 3D Skinned Multi-Person Linear (SMPL) model of the human body for gait recognition, named SMPLGait. Our framework has two elaborately-designed branches of which one extracts appearance features from silhouettes, the other learns knowledge of 3D viewpoints and shapes from the 3D SMPL model. In addition, due to the lack of suitable datasets, we build the first large-scale 3D representation-based gait recognition dataset, named Gait3D. It contains 4,000 subjects and over 25,000 sequences extracted from 39 cameras in an unconstrained indoor scene. More importantly, it provides 3D SMPL models recovered from video frames which can provide dense 3D information of body shape, viewpoint, and dynamics. Based on Gait3D, we comprehensively compare our method with existing gait recognition approaches, which reflects the superior performance of our framework and the potential of 3D representations for gait recognition in the wild. The code and dataset are available at https://gait3d.github.io.
A-ACT: Action Anticipation through Cycle Transformations
Apr 02, 2022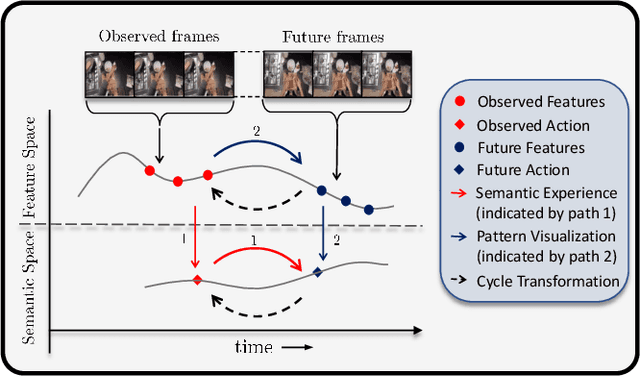
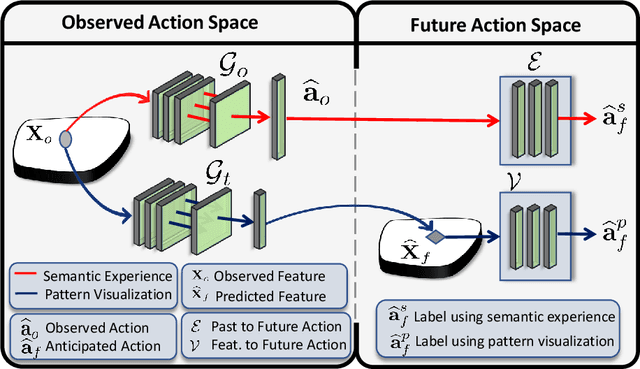
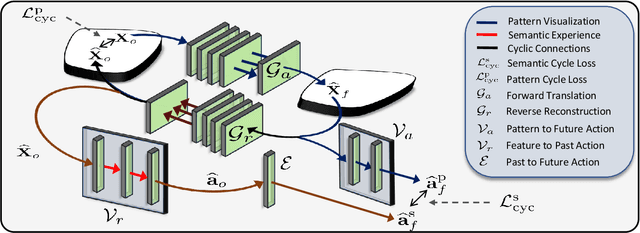
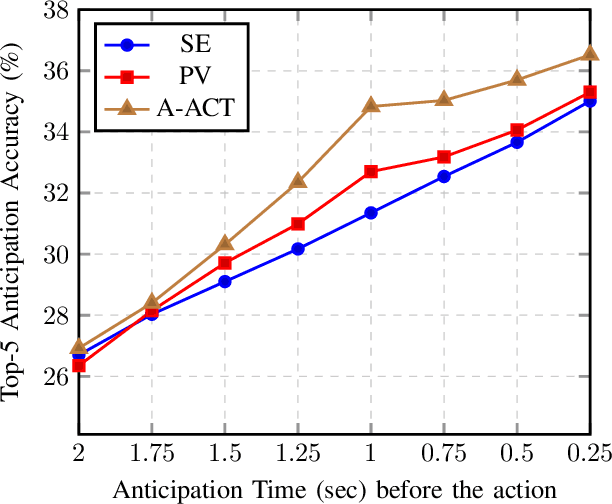
While action anticipation has garnered a lot of research interest recently, most of the works focus on anticipating future action directly through observed visual cues only. In this work, we take a step back to analyze how the human capability to anticipate the future can be transferred to machine learning algorithms. To incorporate this ability in intelligent systems a question worth pondering upon is how exactly do we anticipate? Is it by anticipating future actions from past experiences? Or is it by simulating possible scenarios based on cues from the present? A recent study on human psychology explains that, in anticipating an occurrence, the human brain counts on both systems. In this work, we study the impact of each system for the task of action anticipation and introduce a paradigm to integrate them in a learning framework. We believe that intelligent systems designed by leveraging the psychological anticipation models will do a more nuanced job at the task of human action prediction. Furthermore, we introduce cyclic transformation in the temporal dimension in feature and semantic label space to instill the human ability of reasoning of past actions based on the predicted future. Experiments on Epic-Kitchen, Breakfast, and 50Salads dataset demonstrate that the action anticipation model learned using a combination of the two systems along with the cycle transformation performs favorably against various state-of-the-art approaches.
Visualizing and Understanding Patch Interactions in Vision Transformer
Mar 11, 2022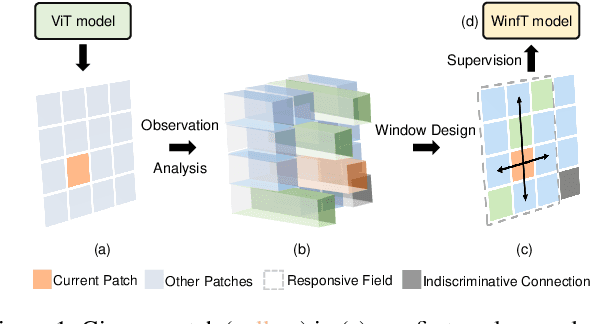
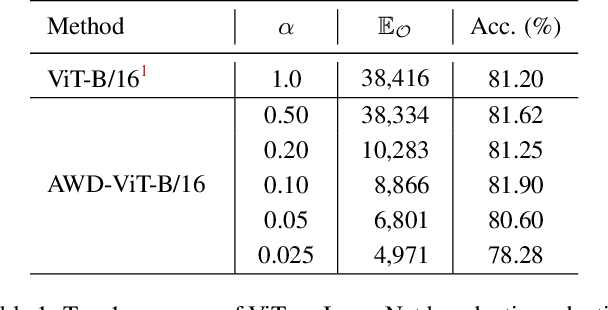
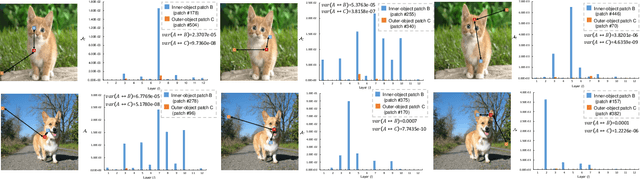
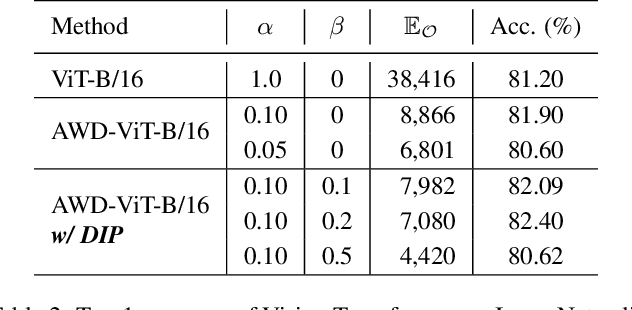
Vision Transformer (ViT) has become a leading tool in various computer vision tasks, owing to its unique self-attention mechanism that learns visual representations explicitly through cross-patch information interactions. Despite having good success, the literature seldom explores the explainability of vision transformer, and there is no clear picture of how the attention mechanism with respect to the correlation across comprehensive patches will impact the performance and what is the further potential. In this work, we propose a novel explainable visualization approach to analyze and interpret the crucial attention interactions among patches for vision transformer. Specifically, we first introduce a quantification indicator to measure the impact of patch interaction and verify such quantification on attention window design and indiscriminative patches removal. Then, we exploit the effective responsive field of each patch in ViT and devise a window-free transformer architecture accordingly. Extensive experiments on ImageNet demonstrate that the exquisitely designed quantitative method is shown able to facilitate ViT model learning, leading the top-1 accuracy by 4.28% at most. Moreover, the results on downstream fine-grained recognition tasks further validate the generalization of our proposal.
Part-level Action Parsing via a Pose-guided Coarse-to-Fine Framework
Mar 09, 2022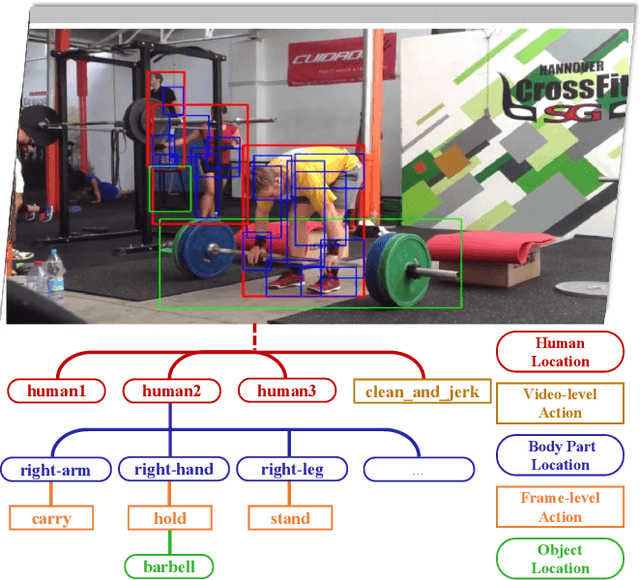
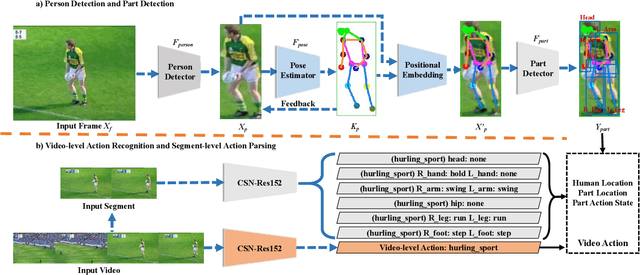
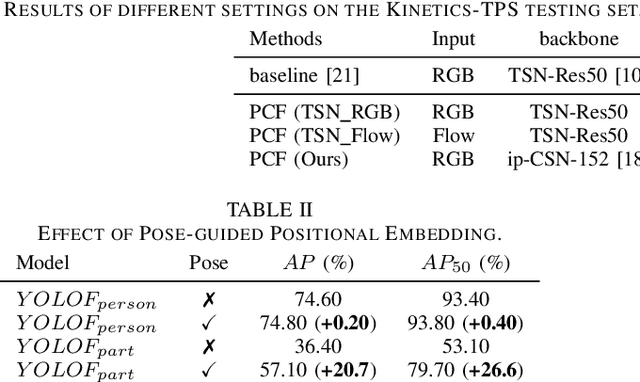
Action recognition from videos, i.e., classifying a video into one of the pre-defined action types, has been a popular topic in the communities of artificial intelligence, multimedia, and signal processing. However, existing methods usually consider an input video as a whole and learn models, e.g., Convolutional Neural Networks (CNNs), with coarse video-level class labels. These methods can only output an action class for the video, but cannot provide fine-grained and explainable cues to answer why the video shows a specific action. Therefore, researchers start to focus on a new task, Part-level Action Parsing (PAP), which aims to not only predict the video-level action but also recognize the frame-level fine-grained actions or interactions of body parts for each person in the video. To this end, we propose a coarse-to-fine framework for this challenging task. In particular, our framework first predicts the video-level class of the input video, then localizes the body parts and predicts the part-level action. Moreover, to balance the accuracy and computation in part-level action parsing, we propose to recognize the part-level actions by segment-level features. Furthermore, to overcome the ambiguity of body parts, we propose a pose-guided positional embedding method to accurately localize body parts. Through comprehensive experiments on a large-scale dataset, i.e., Kinetics-TPS, our framework achieves state-of-the-art performance and outperforms existing methods over a 31.10% ROC score.
Freeform Body Motion Generation from Speech
Mar 04, 2022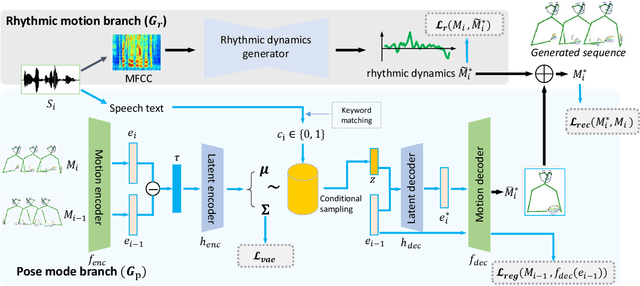
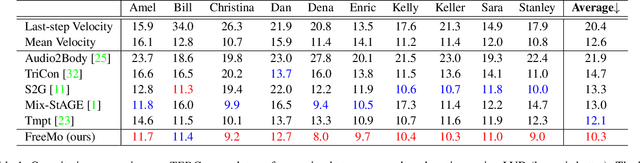
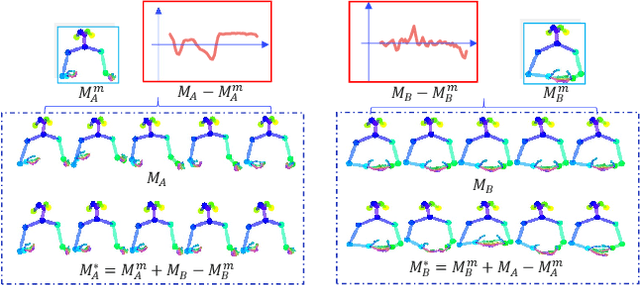
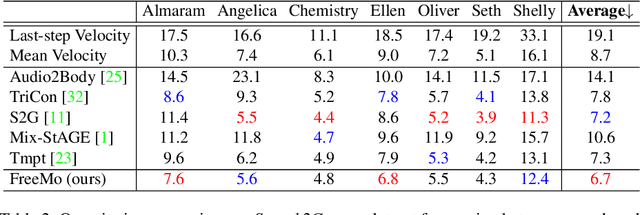
People naturally conduct spontaneous body motions to enhance their speeches while giving talks. Body motion generation from speech is inherently difficult due to the non-deterministic mapping from speech to body motions. Most existing works map speech to motion in a deterministic way by conditioning on certain styles, leading to sub-optimal results. Motivated by studies in linguistics, we decompose the co-speech motion into two complementary parts: pose modes and rhythmic dynamics. Accordingly, we introduce a novel freeform motion generation model (FreeMo) by equipping a two-stream architecture, i.e., a pose mode branch for primary posture generation, and a rhythmic motion branch for rhythmic dynamics synthesis. On one hand, diverse pose modes are generated by conditional sampling in a latent space, guided by speech semantics. On the other hand, rhythmic dynamics are synced with the speech prosody. Extensive experiments demonstrate the superior performance against several baselines, in terms of motion diversity, quality and syncing with speech. Code and pre-trained models will be publicly available through https://github.com/TheTempAccount/Co-Speech-Motion-Generation.