 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning
Jun 05, 2025Zero-shot Event Detection (ED), the task of identifying event mentions in natural language text without any training data, is critical for document understanding in specialized domains. Understanding the complex event ontology, extracting domain-specific triggers from the passage, and structuring them appropriately overloads and limits the utility of Large Language Models (LLMs) for zero-shot ED. To this end, we propose DiCoRe, a divergent-convergent reasoning framework that decouples the task of ED using Dreamer and Grounder. Dreamer encourages divergent reasoning through open-ended event discovery, which helps to boost event coverage. Conversely, Grounder introduces convergent reasoning to align the free-form predictions with the task-specific instructions using finite-state machine guided constrained decoding. Additionally, an LLM-Judge verifies the final outputs to ensure high precision. Through extensive experiments on six datasets across five domains and nine LLMs, we demonstrate how DiCoRe consistently outperforms prior zero-shot, transfer-learning, and reasoning baselines, achieving 4-7% average F1 gains over the best baseline -- establishing DiCoRe as a strong zero-shot ED framework.
FIG: Forward-Inverse Generation for Low-Resource Domain-specific Event Detection
Feb 24, 2025



Event Detection (ED) is the task of identifying typed event mentions of interest from natural language text, which benefits domain-specific reasoning in biomedical, legal, and epidemiological domains. However, procuring supervised data for thousands of events for various domains is a laborious and expensive task. To this end, existing works have explored synthetic data generation via forward (generating labels for unlabeled sentences) and inverse (generating sentences from generated labels) generations. However, forward generation often produces noisy labels, while inverse generation struggles with domain drift and incomplete event annotations. To address these challenges, we introduce FIG, a hybrid approach that leverages inverse generation for high-quality data synthesis while anchoring it to domain-specific cues extracted via forward generation on unlabeled target data. FIG further enhances its synthetic data by adding missing annotations through forward generation-based refinement. Experimentation on three ED datasets from diverse domains reveals that FIG outperforms the best baseline achieving average gains of 3.3% F1 and 5.4% F1 in the zero-shot and few-shot settings respectively. Analyzing the generated trigger hit rate and human evaluation substantiates FIG's superior domain alignment and data quality compared to existing baselines.
Dynamic Strategy Planning for Efficient Question Answering with Large Language Models
Oct 30, 2024



Research has shown the effectiveness of reasoning (e.g., Chain-of-Thought), planning (e.g., SelfAsk), and retrieval augmented generation strategies to improve the performance of Large Language Models (LLMs) on various tasks, such as question answering. However, using a single fixed strategy to answer different kinds of questions is suboptimal in performance and inefficient in terms of generated output tokens and performed retrievals. In our work, we propose a novel technique DyPlan, to induce a dynamic strategy selection process in LLMs, to improve performance and reduce costs in question-answering. DyPlan incorporates an initial decision step to select the most suitable strategy conditioned on the input question and guides the LLM's response generation accordingly. We extend DyPlan to DyPlan-verify, adding an internal verification and correction process to further enrich the generated answer. Experiments on three prominent multi-hop question answering (MHQA) datasets reveal how DyPlan can improve model performance by 7-13% while reducing the cost by 11-32% relative to the best baseline model.
SPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness
Oct 24, 2024



Social media is often the first place where communities discuss the latest societal trends. Prior works have utilized this platform to extract epidemic-related information (e.g. infections, preventive measures) to provide early warnings for epidemic prediction. However, these works only focused on English posts, while epidemics can occur anywhere in the world, and early discussions are often in the local, non-English languages. In this work, we introduce the first multilingual Event Extraction (EE) framework SPEED++ for extracting epidemic event information for a wide range of diseases and languages. To this end, we extend a previous epidemic ontology with 20 argument roles; and curate our multilingual EE dataset SPEED++ comprising 5.1K tweets in four languages for four diseases. Annotating data in every language is infeasible; thus we develop zero-shot cross-lingual cross-disease models (i.e., training only on English COVID data) utilizing multilingual pre-training and show their efficacy in extracting epidemic-related events for 65 diverse languages across different diseases. Experiments demonstrate that our framework can provide epidemic warnings for COVID-19 in its earliest stages in Dec 2019 (3 weeks before global discussions) from Chinese Weibo posts without any training in Chinese. Furthermore, we exploit our framework's argument extraction capabilities to aggregate community epidemic discussions like symptoms and cure measures, aiding misinformation detection and public attention monitoring. Overall, we lay a strong foundation for multilingual epidemic preparedness.
QUDSELECT: Selective Decoding for Questions Under Discussion Parsing
Aug 02, 2024



Question Under Discussion (QUD) is a discourse framework that uses implicit questions to reveal discourse relationships between sentences. In QUD parsing, each sentence is viewed as an answer to a question triggered by an anchor sentence in prior context. The resulting QUD structure is required to conform to several theoretical criteria like answer compatibility (how well the question is answered), making QUD parsing a challenging task. Previous works construct QUD parsers in a pipelined manner (i.e. detect the trigger sentence in context and then generate the question). However, these parsers lack a holistic view of the task and can hardly satisfy all the criteria. In this work, we introduce QUDSELECT, a joint-training framework that selectively decodes the QUD dependency structures considering the QUD criteria. Using instruction-tuning, we train models to simultaneously predict the anchor sentence and generate the associated question. To explicitly incorporate the criteria, we adopt a selective decoding strategy of sampling multiple QUD candidates during inference, followed by selecting the best one with criteria scorers. Our method outperforms the state-of-the-art baseline models by 9% in human evaluation and 4% in automatic evaluation, demonstrating the effectiveness of our framework.
Event Detection from Social Media for Epidemic Prediction
Apr 02, 2024Social media is an easy-to-access platform providing timely updates about societal trends and events. Discussions regarding epidemic-related events such as infections, symptoms, and social interactions can be crucial for informing policymaking during epidemic outbreaks. In our work, we pioneer exploiting Event Detection (ED) for better preparedness and early warnings of any upcoming epidemic by developing a framework to extract and analyze epidemic-related events from social media posts. To this end, we curate an epidemic event ontology comprising seven disease-agnostic event types and construct a Twitter dataset SPEED with human-annotated events focused on the COVID-19 pandemic. Experimentation reveals how ED models trained on COVID-based SPEED can effectively detect epidemic events for three unseen epidemics of Monkeypox, Zika, and Dengue; while models trained on existing ED datasets fail miserably. Furthermore, we show that reporting sharp increases in the extracted events by our framework can provide warnings 4-9 weeks earlier than the WHO epidemic declaration for Monkeypox. This utility of our framework lays the foundations for better preparedness against emerging epidemics.
A Reevaluation of Event Extraction: Past, Present, and Future Challenges
Nov 16, 2023



Event extraction has attracted much attention in recent years due to its potential for many applications. However, recent studies observe some evaluation challenges, suggesting that reported scores might not reflect the true performance. In this work, we first identify and discuss these evaluation challenges, including the unfair comparisons resulting from different assumptions about data or different data preprocessing steps, the incompleteness of the current evaluation framework leading to potential dataset bias or data split bias, and low reproducibility of prior studies. To address these challenges, we propose TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE contains standardized data preprocessing scripts and splits for more than ten datasets across different domains. In addition, we aggregate and re-implement over ten event extraction approaches published in recent years and conduct a comprehensive reevaluation. Finally, we explore the capability of large language models in event extraction and discuss some future challenges. We expect TextEE will serve as a reliable benchmark for event extraction, facilitating future research in the field.
Contextual Label Projection for Cross-Lingual Structure Extraction
Sep 16, 2023Translating training data into target languages has proven beneficial for cross-lingual transfer. However, for structure extraction tasks, translating data requires a label projection step, which translates input text and obtains translated labels in the translated text jointly. Previous research in label projection mostly compromises translation quality by either facilitating easy identification of translated labels from translated text or using word-level alignment between translation pairs to assemble translated phrase-level labels from the aligned words. In this paper, we introduce CLAP, which first translates text to the target language and performs contextual translation on the labels using the translated text as the context, ensuring better accuracy for the translated labels. We leverage instruction-tuned language models with multilingual capabilities as our contextual translator, imposing the constraint of the presence of translated labels in the translated text via instructions. We compare CLAP with other label projection techniques for creating pseudo-training data in target languages on event argument extraction, a representative structure extraction task. Results show that CLAP improves by 2-2.5 F1-score over other methods on the Chinese and Arabic ACE05 datasets.
GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types
May 25, 2022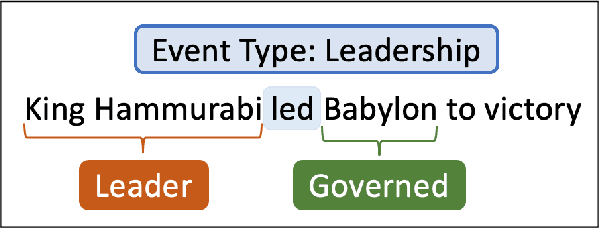
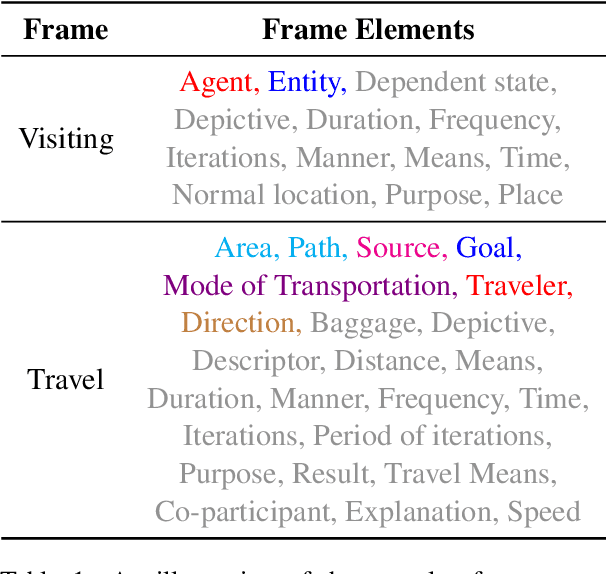
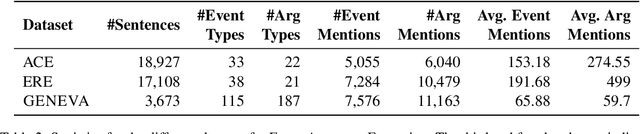
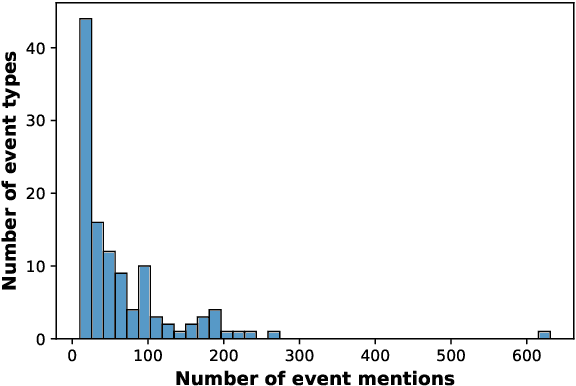
Numerous events occur worldwide and are documented in the news, social media, and various online platforms in raw text. Extracting useful and succinct information about these events is crucial to various downstream applications. Event Argument Extraction (EAE) deals with the task of extracting event-specific information from natural language text. In order to cater to new events and domains in a realistic low-data setting, there is a growing urgency for EAE models to be generalizable. Consequentially, there is a necessity for benchmarking setups to evaluate the generalizability of EAE models. But most existing benchmarking datasets like ACE and ERE have limited coverage in terms of events and cannot adequately evaluate the generalizability of EAE models. To alleviate this issue, we introduce a new dataset GENEVA covering a diverse range of 115 events and 187 argument roles. Using this dataset, we create four benchmarking test suites to assess the model's generalization capability from different perspectives. We benchmark various representative models on these test suites and compare their generalizability relatively. Finally, we propose a new model SCAD that outperforms the previous models and serves as a strong benchmark for these test suites.
Politeness Transfer: A Tag and Generate Approach
May 01, 2020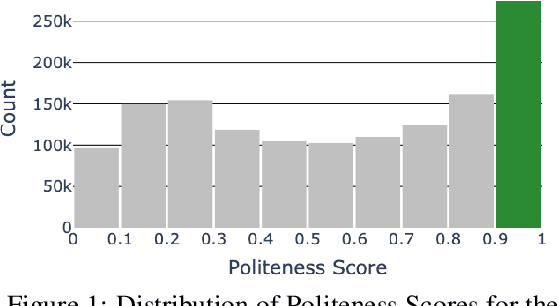
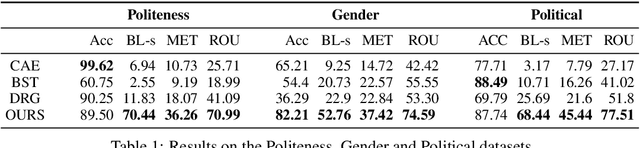
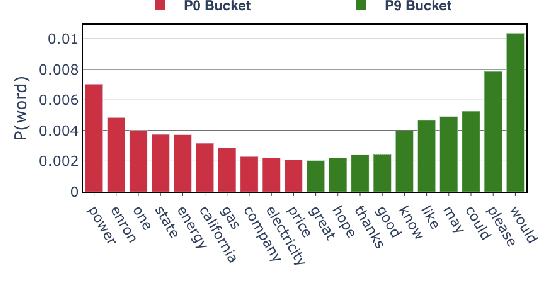

This paper introduces a new task of politeness transfer which involves converting non-polite sentences to polite sentences while preserving the meaning. We also provide a dataset of more than 1.39 instances automatically labeled for politeness to encourage benchmark evaluations on this new task. We design a tag and generate pipeline that identifies stylistic attributes and subsequently generates a sentence in the target style while preserving most of the source content. For politeness as well as five other transfer tasks, our model outperforms the state-of-the-art methods on automatic metrics for content preservation, with a comparable or better performance on style transfer accuracy. Additionally, our model surpasses existing methods on human evaluations for grammaticality, meaning preservation and transfer accuracy across all the six style transfer tasks. The data and code is located at https://github.com/tag-and-generate.