 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Auxiliary Tasks Improves Reference-Free Hallucination Detection in Open-Domain Long-Form Generation
May 18, 2025Hallucination, the generation of factually incorrect information, remains a significant challenge for large language models (LLMs), especially in open-domain long-form generation. Existing approaches for detecting hallucination in long-form tasks either focus on limited domains or rely heavily on external fact-checking tools, which may not always be available. In this work, we systematically investigate reference-free hallucination detection in open-domain long-form responses. Our findings reveal that internal states (e.g., model's output probability and entropy) alone are insufficient for reliably (i.e., better than random guessing) distinguishing between factual and hallucinated content. To enhance detection, we explore various existing approaches, including prompting-based methods, probing, and fine-tuning, with fine-tuning proving the most effective. To further improve the accuracy, we introduce a new paradigm, named RATE-FT, that augments fine-tuning with an auxiliary task for the model to jointly learn with the main task of hallucination detection. With extensive experiments and analysis using a variety of model families & datasets, we demonstrate the effectiveness and generalizability of our method, e.g., +3% over general fine-tuning methods on LongFact.
Dynamic Strategy Planning for Efficient Question Answering with Large Language Models
Oct 30, 2024



Research has shown the effectiveness of reasoning (e.g., Chain-of-Thought), planning (e.g., SelfAsk), and retrieval augmented generation strategies to improve the performance of Large Language Models (LLMs) on various tasks, such as question answering. However, using a single fixed strategy to answer different kinds of questions is suboptimal in performance and inefficient in terms of generated output tokens and performed retrievals. In our work, we propose a novel technique DyPlan, to induce a dynamic strategy selection process in LLMs, to improve performance and reduce costs in question-answering. DyPlan incorporates an initial decision step to select the most suitable strategy conditioned on the input question and guides the LLM's response generation accordingly. We extend DyPlan to DyPlan-verify, adding an internal verification and correction process to further enrich the generated answer. Experiments on three prominent multi-hop question answering (MHQA) datasets reveal how DyPlan can improve model performance by 7-13% while reducing the cost by 11-32% relative to the best baseline model.
Efficient CDF Approximations for Normalizing Flows
Feb 23, 2022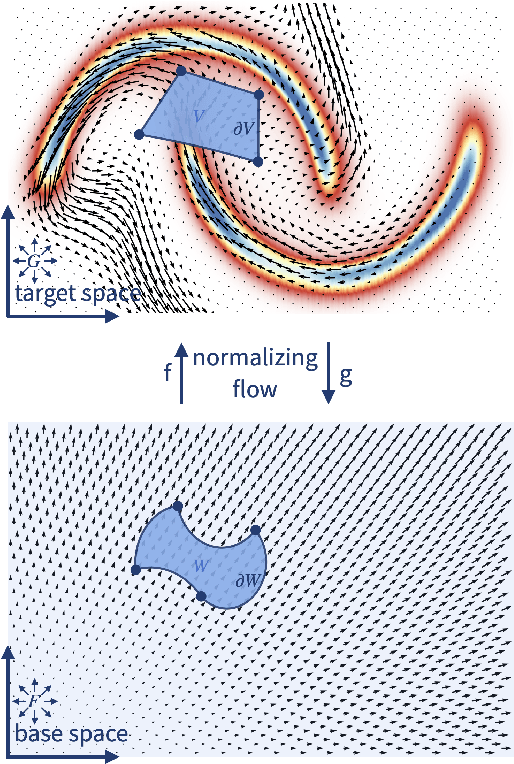

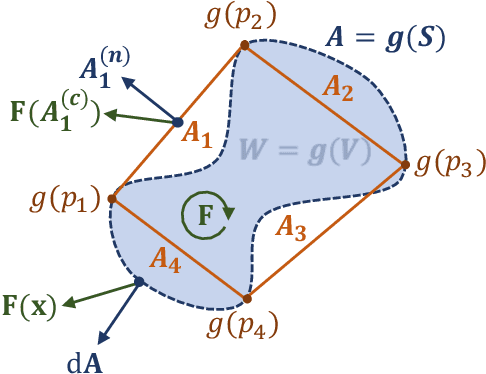
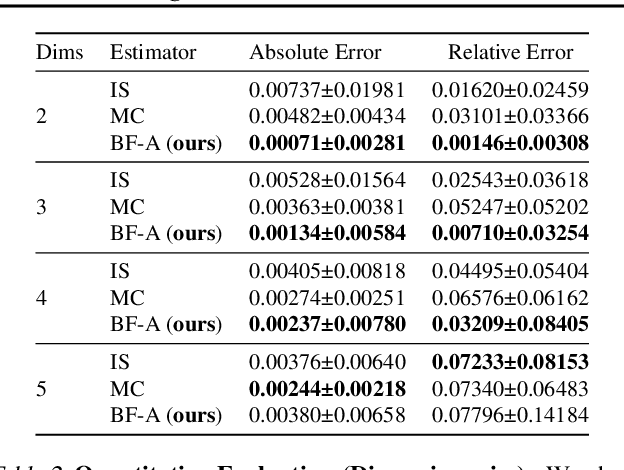
Normalizing flows model a complex target distribution in terms of a bijective transform operating on a simple base distribution. As such, they enable tractable computation of a number of important statistical quantities, particularly likelihoods and samples. Despite these appealing properties, the computation of more complex inference tasks, such as the cumulative distribution function (CDF) over a complex region (e.g., a polytope) remains challenging. Traditional CDF approximations using Monte-Carlo techniques are unbiased but have unbounded variance and low sample efficiency. Instead, we build upon the diffeomorphic properties of normalizing flows and leverage the divergence theorem to estimate the CDF over a closed region in target space in terms of the flux across its \emph{boundary}, as induced by the normalizing flow. We describe both deterministic and stochastic instances of this estimator: while the deterministic variant iteratively improves the estimate by strategically subdividing the boundary, the stochastic variant provides unbiased estimates. Our experiments on popular flow architectures and UCI benchmark datasets show a marked improvement in sample efficiency as compared to traditional estimators.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018
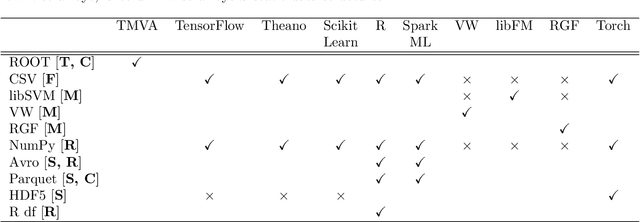

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.