 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQMC: Efficient SLM Edge Inference via Outlier-Aware Quantization and Emergent Memories Co-Design
Jan 21, 2026Deploying Small Language Models (SLMs) on edge platforms is critical for real-time, privacy-sensitive generative AI, yet constrained by memory, latency, and energy budgets. Quantization reduces model size and cost but suffers from device noise in emerging non-volatile memories, while conventional memory hierarchies further limit efficiency. SRAM provides fast access but has low density, DRAM must simultaneously accommodate static weights and dynamic KV caches, which creates bandwidth contention, and Flash, although dense, is primarily used for initialization and remains inactive during inference. These limitations highlight the need for hybrid memory organizations tailored to LLM inference. We propose Outlier-aware Quantization with Memory Co-design (QMC), a retraining-free quantization with a novel heterogeneous memory architecture. QMC identifies inlier and outlier weights in SLMs, storing inlier weights in compact multi-level Resistive-RAM (ReRAM) while preserving critical outliers in high-precision on-chip Magnetoresistive-RAM (MRAM), mitigating noise-induced degradation. On language modeling and reasoning benchmarks, QMC outperforms and matches state-of-the-art quantization methods using advanced algorithms and hybrid data formats, while achieving greater compression under both algorithm-only evaluation and realistic deployment settings. Specifically, compared against SoTA quantization methods on the latest edge AI platform, QMC reduces memory usage by 6.3x-7.3x, external data transfers by 7.6x, energy by 11.7x, and latency by 12.5x when compared to FP16, establishing QMC as a scalable, deployment-ready co-design for efficient on-device inference.
LifeAgentBench: A Multi-dimensional Benchmark and Agent for Personal Health Assistants in Digital Health
Jan 20, 2026Personalized digital health support requires long-horizon, cross-dimensional reasoning over heterogeneous lifestyle signals, and recent advances in mobile sensing and large language models (LLMs) make such support increasingly feasible. However, the capabilities of current LLMs in this setting remain unclear due to the lack of systematic benchmarks. In this paper, we introduce LifeAgentBench, a large-scale QA benchmark for long-horizon, cross-dimensional, and multi-user lifestyle health reasoning, containing 22,573 questions spanning from basic retrieval to complex reasoning. We release an extensible benchmark construction pipeline and a standardized evaluation protocol to enable reliable and scalable assessment of LLM-based health assistants. We then systematically evaluate 11 leading LLMs on LifeAgentBench and identify key bottlenecks in long-horizon aggregation and cross-dimensional reasoning. Motivated by these findings, we propose LifeAgent as a strong baseline agent for health assistant that integrates multi-step evidence retrieval with deterministic aggregation, achieving significant improvements compared with two widely used baselines. Case studies further demonstrate its potential in realistic daily-life scenarios. The benchmark is publicly available at https://anonymous.4open.science/r/LifeAgentBench-CE7B.
FaTRQ: Tiered Residual Quantization for LLM Vector Search in Far-Memory-Aware ANNS Systems
Jan 15, 2026Approximate Nearest-Neighbor Search (ANNS) is a key technique in retrieval-augmented generation (RAG), enabling rapid identification of the most relevant high-dimensional embeddings from massive vector databases. Modern ANNS engines accelerate this process using prebuilt indexes and store compressed vector-quantized representations in fast memory. However, they still rely on a costly second-pass refinement stage that reads full-precision vectors from slower storage like SSDs. For modern text and multimodal embeddings, these reads now dominate the latency of the entire query. We propose FaTRQ, a far-memory-aware refinement system using tiered memory that eliminates the need to fetch full vectors from storage. It introduces a progressive distance estimator that refines coarse scores using compact residuals streamed from far memory. Refinement stops early once a candidate is provably outside the top-k. To support this, we propose tiered residual quantization, which encodes residuals as ternary values stored efficiently in far memory. A custom accelerator is deployed in a CXL Type-2 device to perform low-latency refinement locally. Together, FaTRQ improves the storage efficiency by 2.4$\times$ and improves the throughput by up to 9$ \times$ than SOTA GPU ANNS system.
Fast and Accurate Causal Parallel Decoding using Jacobi Forcing
Dec 16, 2025Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion Large Language Models (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.
Towards Interpretable and Inference-Optimal COT Reasoning with Sparse Autoencoder-Guided Generation
Oct 02, 2025

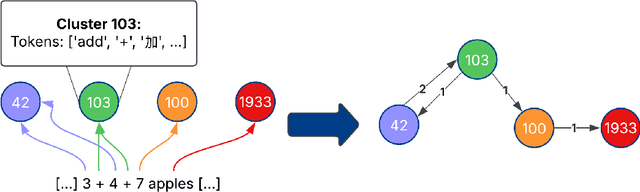

We propose a novel method that leverages sparse autoencoders (SAEs) and clustering techniques to analyze the internal token representations of large language models (LLMs) and guide generations in mathematical reasoning tasks. Our approach first trains an SAE to generate sparse vector representations for training tokens, then applies k-means clustering to construct a graph where vertices represent token clusters and weighted edges capture sequential token transitions. Using this graph, we define an edge-weight based reward function to quantify adherence to established reasoning traces, thereby identifying exploitative reasoning trajectories. Additionally, we measure generation diversity from clustering to assess the extent of exploration. Our findings indicate that balancing both exploitation and exploration is crucial for achieving high accuracy in mathematical reasoning tasks. During generation, the SAE can serve as a scalable reward model to guide generations, ensuring a balanced trade-off between exploitation and exploration. This prevents extreme behaviors in either direction, ultimately fostering a higher-quality reasoning process in LLMs.
Clo-HDnn: A 4.66 TFLOPS/W and 3.78 TOPS/W Continual On-Device Learning Accelerator with Energy-efficient Hyperdimensional Computing via Progressive Search
Jul 23, 2025Clo-HDnn is an on-device learning (ODL) accelerator designed for emerging continual learning (CL) tasks. Clo-HDnn integrates hyperdimensional computing (HDC) along with low-cost Kronecker HD Encoder and weight clustering feature extraction (WCFE) to optimize accuracy and efficiency. Clo-HDnn adopts gradient-free CL to efficiently update and store the learned knowledge in the form of class hypervectors. Its dual-mode operation enables bypassing costly feature extraction for simpler datasets, while progressive search reduces complexity by up to 61% by encoding and comparing only partial query hypervectors. Achieving 4.66 TFLOPS/W (FE) and 3.78 TOPS/W (classifier), Clo-HDnn delivers 7.77x and 4.85x higher energy efficiency compared to SOTA ODL accelerators.
lmgame-Bench: How Good are LLMs at Playing Games?
May 21, 2025Playing video games requires perception, memory, and planning, exactly the faculties modern large language model (LLM) agents are expected to master. We study the major challenges in using popular video games to evaluate modern LLMs and find that directly dropping LLMs into games cannot make an effective evaluation, for three reasons -- brittle vision perception, prompt sensitivity, and potential data contamination. We introduce lmgame-Bench to turn games into reliable evaluations. lmgame-Bench features a suite of platformer, puzzle, and narrative games delivered through a unified Gym-style API and paired with lightweight perception and memory scaffolds, and is designed to stabilize prompt variance and remove contamination. Across 13 leading models, we show lmgame-Bench is challenging while still separating models well. Correlation analysis shows that every game probes a unique blend of capabilities often tested in isolation elsewhere. More interestingly, performing reinforcement learning on a single game from lmgame-Bench transfers both to unseen games and to external planning tasks. Our evaluation code is available at https://github.com/lmgame-org/GamingAgent/lmgame-bench.
DPQ-HD: Post-Training Compression for Ultra-Low Power Hyperdimensional Computing
May 08, 2025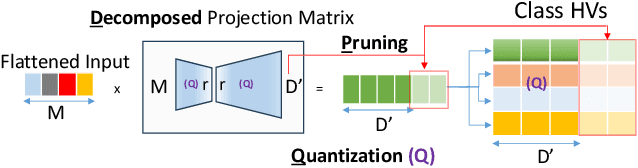

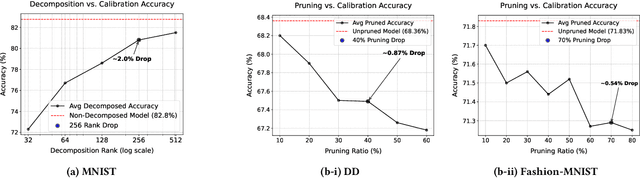
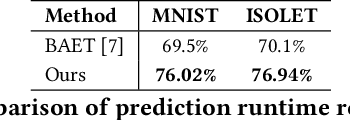
Hyperdimensional Computing (HDC) is emerging as a promising approach for edge AI, offering a balance between accuracy and efficiency. However, current HDC-based applications often rely on high-precision models and/or encoding matrices to achieve competitive performance, which imposes significant computational and memory demands, especially for ultra-low power devices. While recent efforts use techniques like precision reduction and pruning to increase the efficiency, most require retraining to maintain performance, making them expensive and impractical. To address this issue, we propose a novel Post Training Compression algorithm, Decomposition-Pruning-Quantization (DPQ-HD), which aims at compressing the end-to-end HDC system, achieving near floating point performance without the need of retraining. DPQ-HD reduces computational and memory overhead by uniquely combining the above three compression techniques and efficiently adapts to hardware constraints. Additionally, we introduce an energy-efficient inference approach that progressively evaluates similarity scores such as cosine similarity and performs early exit to reduce the computation, accelerating prediction inference while maintaining accuracy. We demonstrate that DPQ-HD achieves up to 20-100x reduction in memory for image and graph classification tasks with only a 1-2% drop in accuracy compared to uncompressed workloads. Lastly, we show that DPQ-HD outperforms the existing post-training compression methods and performs better or at par with retraining-based state-of-the-art techniques, requiring significantly less overall optimization time (up to 100x) and faster inference (up to 56x) on a microcontroller
Client Selection in Federated Learning with Data Heterogeneity and Network Latencies
Apr 02, 2025



Federated learning (FL) is a distributed machine learning paradigm where multiple clients conduct local training based on their private data, then the updated models are sent to a central server for global aggregation. The practical convergence of FL is challenged by multiple factors, with the primary hurdle being the heterogeneity among clients. This heterogeneity manifests as data heterogeneity concerning local data distribution and latency heterogeneity during model transmission to the server. While prior research has introduced various efficient client selection methods to alleviate the negative impacts of either of these heterogeneities individually, efficient methods to handle real-world settings where both these heterogeneities exist simultaneously do not exist. In this paper, we propose two novel theoretically optimal client selection schemes that can handle both these heterogeneities. Our methods involve solving simple optimization problems every round obtained by minimizing the theoretical runtime to convergence. Empirical evaluations on 9 datasets with non-iid data distributions, 2 practical delay distributions, and non-convex neural network models demonstrate that our algorithms are at least competitive to and at most 20 times better than best existing baselines.
ReLATE: Resilient Learner Selection for Multivariate Time-Series Classification Against Adversarial Attacks
Mar 10, 2025



Minimizing computational overhead in time-series classification, particularly in deep learning models, presents a significant challenge. This challenge is further compounded by adversarial attacks, emphasizing the need for resilient methods that ensure robust performance and efficient model selection. We introduce ReLATE, a framework that identifies robust learners based on dataset similarity, reduces computational overhead, and enhances resilience. ReLATE maintains multiple deep learning models in well-known adversarial attack scenarios, capturing model performance. ReLATE identifies the most analogous dataset to a given target using a similarity metric, then applies the optimal model from the most similar dataset. ReLATE reduces computational overhead by an average of 81.2%, enhancing adversarial resilience and streamlining robust model selection, all without sacrificing performance, within 4.2% of Oracle.