 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024



Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Feb 23, 2024There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
On the Convergence and Sample Complexity Analysis of Deep Q-Networks with $ε$-Greedy Exploration
Oct 24, 2023This paper provides a theoretical understanding of Deep Q-Network (DQN) with the $\varepsilon$-greedy exploration in deep reinforcement learning. Despite the tremendous empirical achievement of the DQN, its theoretical characterization remains underexplored. First, the exploration strategy is either impractical or ignored in the existing analysis. Second, in contrast to conventional Q-learning algorithms, the DQN employs the target network and experience replay to acquire an unbiased estimation of the mean-square Bellman error (MSBE) utilized in training the Q-network. However, the existing theoretical analysis of DQNs lacks convergence analysis or bypasses the technical challenges by deploying a significantly overparameterized neural network, which is not computationally efficient. This paper provides the first theoretical convergence and sample complexity analysis of the practical setting of DQNs with $\epsilon$-greedy policy. We prove an iterative procedure with decaying $\epsilon$ converges to the optimal Q-value function geometrically. Moreover, a higher level of $\epsilon$ values enlarges the region of convergence but slows down the convergence, while the opposite holds for a lower level of $\epsilon$ values. Experiments justify our established theoretical insights on DQNs.
LakeBench: Benchmarks for Data Discovery over Data Lakes
Jul 09, 2023



Within enterprises, there is a growing need to intelligently navigate data lakes, specifically focusing on data discovery. Of particular importance to enterprises is the ability to find related tables in data repositories. These tables can be unionable, joinable, or subsets of each other. There is a dearth of benchmarks for these tasks in the public domain, with related work targeting private datasets. In LakeBench, we develop multiple benchmarks for these tasks by using the tables that are drawn from a diverse set of data sources such as government data from CKAN, Socrata, and the European Central Bank. We compare the performance of 4 publicly available tabular foundational models on these tasks. None of the existing models had been trained on the data discovery tasks that we developed for this benchmark; not surprisingly, their performance shows significant room for improvement. The results suggest that the establishment of such benchmarks may be useful to the community to build tabular models usable for data discovery in data lakes.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023



Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
MISMATCH: Fine-grained Evaluation of Machine-generated Text with Mismatch Error Types
Jun 18, 2023



With the growing interest in large language models, the need for evaluating the quality of machine text compared to reference (typically human-generated) text has become focal attention. Most recent works focus either on task-specific evaluation metrics or study the properties of machine-generated text captured by the existing metrics. In this work, we propose a new evaluation scheme to model human judgments in 7 NLP tasks, based on the fine-grained mismatches between a pair of texts. Inspired by the recent efforts in several NLP tasks for fine-grained evaluation, we introduce a set of 13 mismatch error types such as spatial/geographic errors, entity errors, etc, to guide the model for better prediction of human judgments. We propose a neural framework for evaluating machine texts that uses these mismatch error types as auxiliary tasks and re-purposes the existing single-number evaluation metrics as additional scalar features, in addition to textual features extracted from the machine and reference texts. Our experiments reveal key insights about the existing metrics via the mismatch errors. We show that the mismatch errors between the sentence pairs on the held-out datasets from 7 NLP tasks align well with the human evaluation.
Scalable Learning of Latent Language Structure With Logical Offline Cycle Consistency
May 31, 2023



We introduce Logical Offline Cycle Consistency Optimization (LOCCO), a scalable, semi-supervised method for training a neural semantic parser. Conceptually, LOCCO can be viewed as a form of self-learning where the semantic parser being trained is used to generate annotations for unlabeled text that are then used as new supervision. To increase the quality of annotations, our method utilizes a count-based prior over valid formal meaning representations and a cycle-consistency score produced by a neural text generation model as additional signals. Both the prior and semantic parser are updated in an alternate fashion from full passes over the training data, which can be seen as approximating the marginalization of latent structures through stochastic variational inference. The use of a count-based prior, frozen text generation model, and offline annotation process yields an approach with negligible complexity and latency increases as compared to conventional self-learning. As an added bonus, the annotations produced by LOCCO can be trivially repurposed to train a neural text generation model. We demonstrate the utility of LOCCO on the well-known WebNLG benchmark where we obtain an improvement of 2 points against a self-learning parser under equivalent conditions, an improvement of 1.3 points against the previous state-of-the-art parser, and competitive text generation performance in terms of BLEU score.
Laziness Is a Virtue When It Comes to Compositionality in Neural Semantic Parsing
May 07, 2023



Nearly all general-purpose neural semantic parsers generate logical forms in a strictly top-down autoregressive fashion. Though such systems have achieved impressive results across a variety of datasets and domains, recent works have called into question whether they are ultimately limited in their ability to compositionally generalize. In this work, we approach semantic parsing from, quite literally, the opposite direction; that is, we introduce a neural semantic parsing generation method that constructs logical forms from the bottom up, beginning from the logical form's leaves. The system we introduce is lazy in that it incrementally builds up a set of potential semantic parses, but only expands and processes the most promising candidate parses at each generation step. Such a parsimonious expansion scheme allows the system to maintain an arbitrarily large set of parse hypotheses that are never realized and thus incur minimal computational overhead. We evaluate our approach on compositional generalization; specifically, on the challenging CFQ dataset and three Text-to-SQL datasets where we show that our novel, bottom-up semantic parsing technique outperforms general-purpose semantic parsers while also being competitive with comparable neural parsers that have been designed for each task.
Mitigating Gradient Bias in Multi-objective Learning: A Provably Convergent Stochastic Approach
Oct 23, 2022Machine learning problems with multiple objective functions appear either in learning with multiple criteria where learning has to make a trade-off between multiple performance metrics such as fairness, safety and accuracy; or, in multi-task learning where multiple tasks are optimized jointly, sharing inductive bias between them. This problems are often tackled by the multi-objective optimization framework. However, existing stochastic multi-objective gradient methods and its variants (e.g., MGDA, PCGrad, CAGrad, etc.) all adopt a biased noisy gradient direction, which leads to degraded empirical performance. To this end, we develop a stochastic Multi-objective gradient Correction (MoCo) method for multi-objective optimization. The unique feature of our method is that it can guarantee convergence without increasing the batch size even in the non-convex setting. Simulations on multi-task supervised and reinforcement learning demonstrate the effectiveness of our method relative to state-of-the-art methods.
LOA: Logical Optimal Actions for Text-based Interaction Games
Oct 21, 2021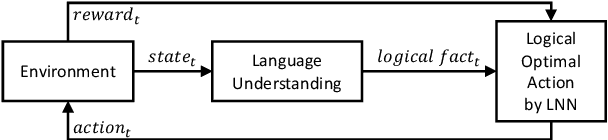
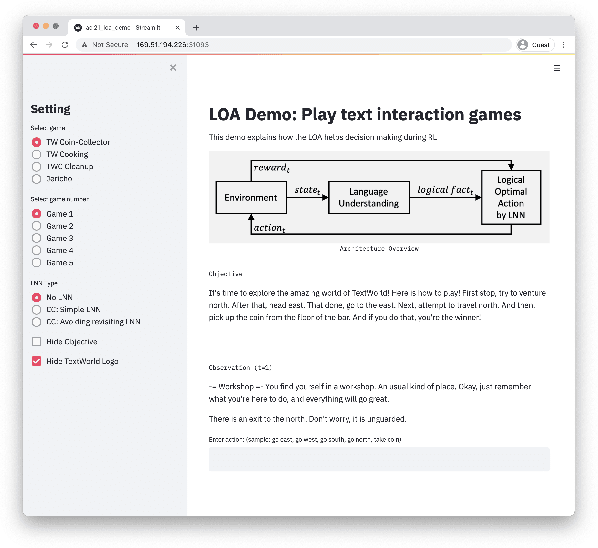
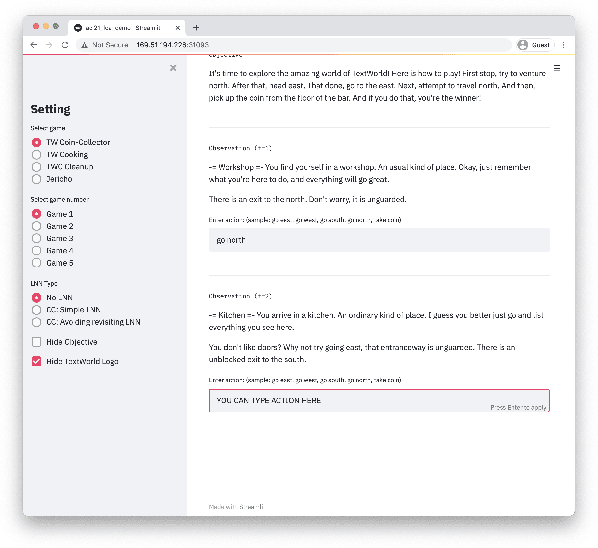
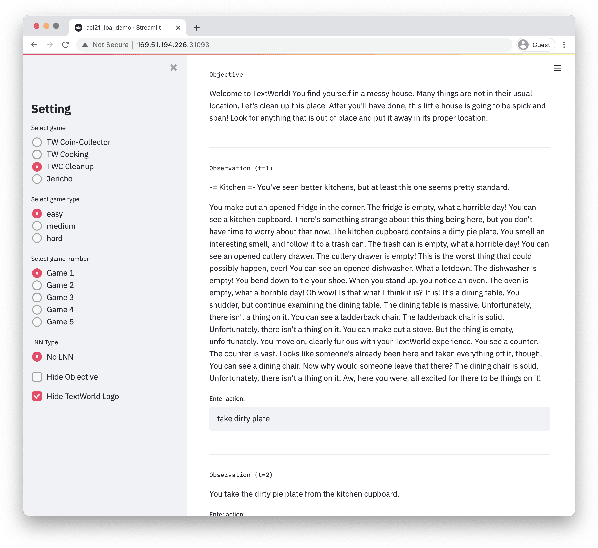
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Code: https://github.com/ibm/loa