 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Learning Graph Tasks with Just LLMs
Aug 13, 2025For large language models (LLMs), reasoning over graphs could help solve many problems. Prior work has tried to improve LLM graph reasoning by examining how best to serialize graphs as text and by combining GNNs and LLMs. However, the merits of such approaches remain unclear, so we empirically answer the following research questions: (1) Can LLMs learn to solve fundamental graph tasks without specialized graph encoding models?, (2) Can LLMs generalize learned solutions to unseen graph structures or tasks?, and (3) What are the merits of competing approaches to learn graph tasks? We show that even small LLMs can learn to solve graph tasks by training them with instructive chain-of-thought solutions, and this training generalizes, without specialized graph encoders, to new tasks and graph structures.
Can Cross Encoders Produce Useful Sentence Embeddings?
Feb 05, 2025Cross encoders (CEs) are trained with sentence pairs to detect relatedness. As CEs require sentence pairs at inference, the prevailing view is that they can only be used as re-rankers in information retrieval pipelines. Dual encoders (DEs) are instead used to embed sentences, where sentence pairs are encoded by two separate encoders with shared weights at training, and a loss function that ensures the pair's embeddings lie close in vector space if the sentences are related. DEs however, require much larger datasets to train, and are less accurate than CEs. We report a curious finding that embeddings from earlier layers of CEs can in fact be used within an information retrieval pipeline. We show how to exploit CEs to distill a lighter-weight DE, with a 5.15x speedup in inference time.
TabSketchFM: Sketch-based Tabular Representation Learning for Data Discovery over Data Lakes
Jun 28, 2024



Enterprises have a growing need to identify relevant tables in data lakes; e.g. tables that are unionable, joinable, or subsets of each other. Tabular neural models can be helpful for such data discovery tasks. In this paper, we present TabSketchFM, a neural tabular model for data discovery over data lakes. First, we propose a novel pre-training sketch-based approach to enhance the effectiveness of data discovery techniques in neural tabular models. Second, to further finetune the pretrained model for several downstream tasks, we develop LakeBench, a collection of 8 benchmarks to help with different data discovery tasks such as finding tasks that are unionable, joinable, or subsets of each other. We then show on these finetuning tasks that TabSketchFM achieves state-of-the art performance compared to existing neural models. Third, we use these finetuned models to search for tables that are unionable, joinable, or can be subsets of each other. Our results demonstrate improvements in F1 scores for search compared to state-of-the-art techniques (even up to 70% improvement in a joinable search benchmark). Finally, we show significant transfer across datasets and tasks establishing that our model can generalize across different tasks over different data lakes
Out of style: Misadventures with LLMs and code style transfer
Jun 14, 2024



Like text, programs have styles, and certain programming styles are more desirable than others for program readability, maintainability, and performance. Code style transfer, however, is difficult to automate except for trivial style guidelines such as limits on line length. Inspired by the success of using language models for text style transfer, we investigate if code language models can perform code style transfer. Code style transfer, unlike text transfer, has rigorous requirements: the system needs to identify lines of code to change, change them correctly, and leave the rest of the program untouched. We designed CSB (Code Style Benchmark), a benchmark suite of code style transfer tasks across five categories including converting for-loops to list comprehensions, eliminating duplication in code, adding decorators to methods, etc. We then used these tests to see if large pre-trained code language models or fine-tuned models perform style transfer correctly, based on rigorous metrics to test that the transfer did occur, and the code still passes functional tests. Surprisingly, language models failed to perform all of the tasks, suggesting that they perform poorly on tasks that require code understanding. We will make available the large-scale corpora to help the community build better code models.
LakeBench: Benchmarks for Data Discovery over Data Lakes
Jul 09, 2023



Within enterprises, there is a growing need to intelligently navigate data lakes, specifically focusing on data discovery. Of particular importance to enterprises is the ability to find related tables in data repositories. These tables can be unionable, joinable, or subsets of each other. There is a dearth of benchmarks for these tasks in the public domain, with related work targeting private datasets. In LakeBench, we develop multiple benchmarks for these tasks by using the tables that are drawn from a diverse set of data sources such as government data from CKAN, Socrata, and the European Central Bank. We compare the performance of 4 publicly available tabular foundational models on these tasks. None of the existing models had been trained on the data discovery tasks that we developed for this benchmark; not surprisingly, their performance shows significant room for improvement. The results suggest that the establishment of such benchmarks may be useful to the community to build tabular models usable for data discovery in data lakes.
Serenity: Library Based Python Code Analysis for Code Completion and Automated Machine Learning
Jan 05, 2023



Dynamically typed languages such as Python have become very popular. Among other strengths, Python's dynamic nature and its straightforward linking to native code have made it the de-facto language for many research areas such as Artificial Intelligence. This flexibility, however, makes static analysis very hard. While creating a sound, or a soundy, analysis for Python remains an open problem, we present in this work Serenity, a framework for static analysis of Python that turns out to be sufficient for some tasks. The Serenity framework exploits two basic mechanisms: (a) reliance on dynamic dispatch at the core of language translation, and (b) extreme abstraction of libraries, to generate an abstraction of the code. We demonstrate the efficiency and usefulness of Serenity's analysis in two applications: code completion and automated machine learning. In these two applications, we demonstrate that such analysis has a strong signal, and can be leveraged to establish state-of-the-art performance, comparable to neural models and dynamic analysis respectively.
A Scalable AutoML Approach Based on Graph Neural Networks
Oct 29, 2021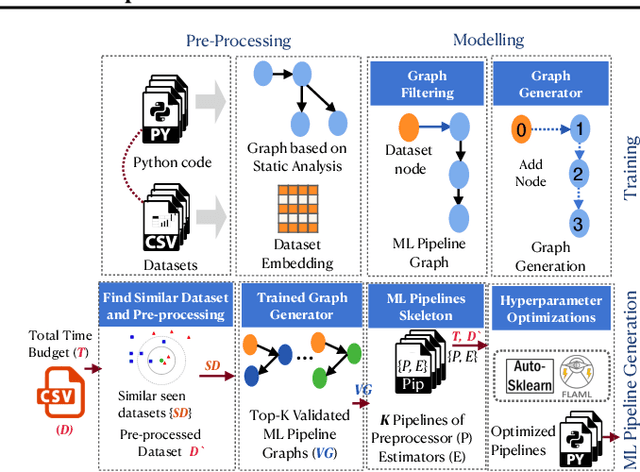

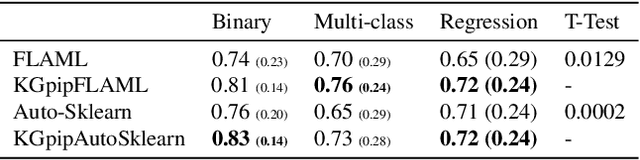
AutoML systems build machine learning models automatically by performing a search over valid data transformations and learners, along with hyper-parameter optimization for each learner. We present a system called KGpip for the selection of transformations and learners, which (1) builds a database of datasets and corresponding historically used pipelines using effective static analysis instead of the typical use of actual runtime information, (2) uses dataset embeddings to find similar datasets in the database based on its content instead of metadata-based features, (3) models AutoML pipeline creation as a graph generation problem, to succinctly characterize the diverse pipelines seen for a single dataset. KGpip is designed as a sub-component for AutoML systems. We demonstrate this ability via integrating KGpip with two AutoML systems and show that it does significantly enhance the performance of existing state-of-the-art systems.
Can Machines Read Coding Manuals Yet? -- A Benchmark for Building Better Language Models for Code Understanding
Sep 15, 2021
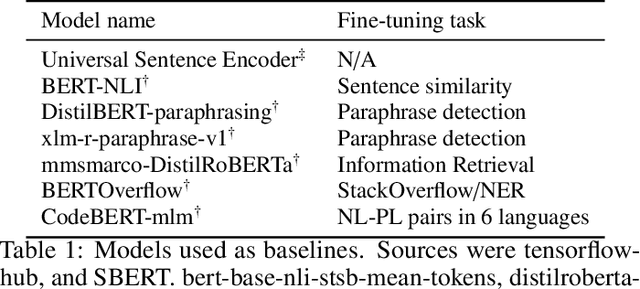
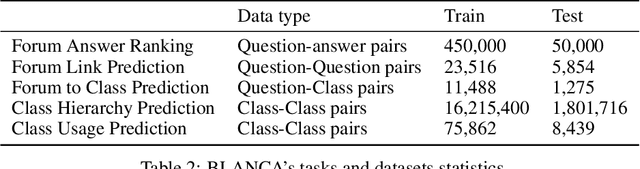
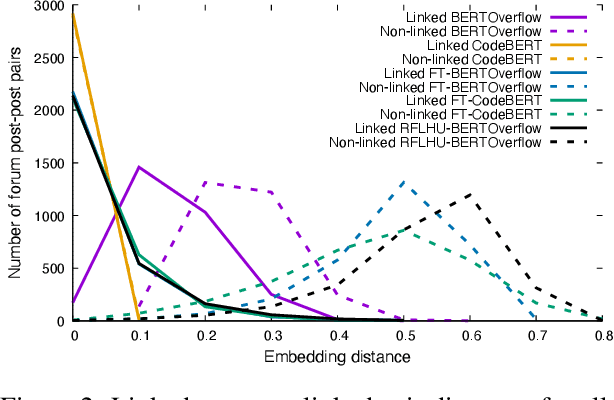
Code understanding is an increasingly important application of Artificial Intelligence. A fundamental aspect of understanding code is understanding text about code, e.g., documentation and forum discussions. Pre-trained language models (e.g., BERT) are a popular approach for various NLP tasks, and there are now a variety of benchmarks, such as GLUE, to help improve the development of such models for natural language understanding. However, little is known about how well such models work on textual artifacts about code, and we are unaware of any systematic set of downstream tasks for such an evaluation. In this paper, we derive a set of benchmarks (BLANCA - Benchmarks for LANguage models on Coding Artifacts) that assess code understanding based on tasks such as predicting the best answer to a question in a forum post, finding related forum posts, or predicting classes related in a hierarchy from class documentation. We evaluate the performance of current state-of-the-art language models on these tasks and show that there is a significant improvement on each task from fine tuning. We also show that multi-task training over BLANCA tasks helps build better language models for code understanding.
Project CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks
May 25, 2021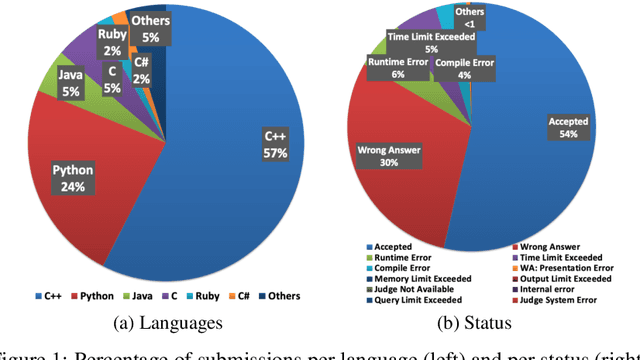
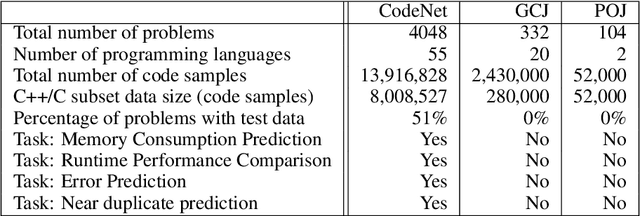
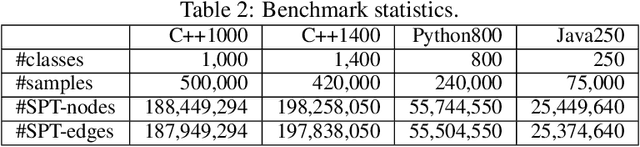
Advancements in deep learning and machine learning algorithms have enabled breakthrough progress in computer vision, speech recognition, natural language processing and beyond. In addition, over the last several decades, software has been built into the fabric of every aspect of our society. Together, these two trends have generated new interest in the fast-emerging research area of AI for Code. As software development becomes ubiquitous across all industries and code infrastructure of enterprise legacy applications ages, it is more critical than ever to increase software development productivity and modernize legacy applications. Over the last decade, datasets like ImageNet, with its large scale and diversity, have played a pivotal role in algorithmic advancements from computer vision to language and speech understanding. In this paper, we present Project CodeNet, a first-of-its-kind, very large scale, diverse, and high-quality dataset to accelerate the algorithmic advancements in AI for Code. It consists of 14M code samples and about 500M lines of code in 55 different programming languages. Project CodeNet is not only unique in its scale, but also in the diversity of coding tasks it can help benchmark: from code similarity and classification for advances in code recommendation algorithms, and code translation between a large variety programming languages, to advances in code performance (both runtime, and memory) improvement techniques. CodeNet also provides sample input and output test sets for over 7M code samples, which can be critical for determining code equivalence in different languages. As a usability feature, we provide several preprocessing tools in Project CodeNet to transform source codes into representations that can be readily used as inputs into machine learning models.
Graph4Code: A Machine Interpretable Knowledge Graph for Code
Feb 21, 2020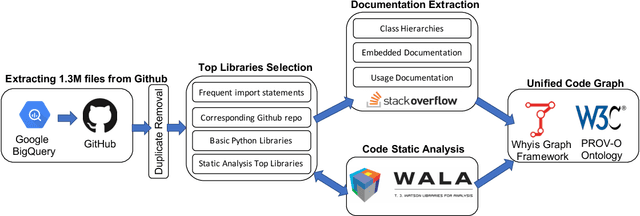
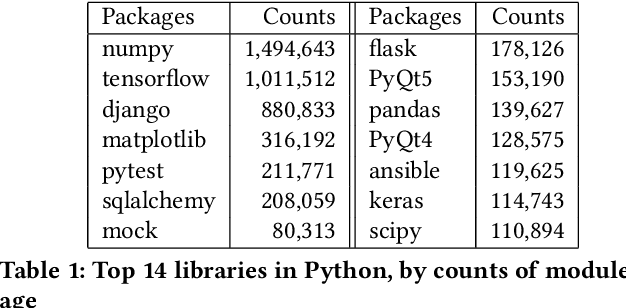
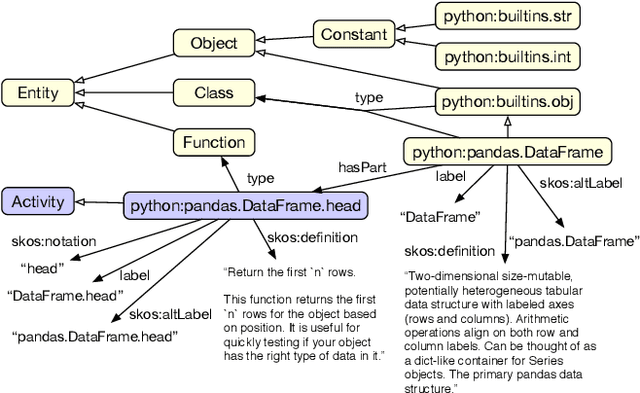

Knowledge graphs have proven to be extremely useful in powering diverse applications in semantic search, natural language understanding, and even image classification. Graph4Code attempts to build well structured knowledge graphs about program code to similarly revolutionize diverse applications such as code search, code understanding, refactoring, bug detection, and code automation. We build such a graph by applying a set of generic code analysis techniques to Python code on the web. Since use of popular Python modules is ubiquitous in code, calls to functions in Python modules serve as key nodes of the knowledge graph. The edges in the graph are based on 1) function usage in the wild (e.g., which other function tends to call this one, or which function tends to precede this one, as gleaned from program analysis), 2) documentation about the function (e.g., code documentation, usage documentation, or forum discussions such as StackOverflow), and 3) program specific features such as class hierarchies. We use the Whyis knowledge graph management framework to make the graph easily extensible. We apply these techniques to 1.3M Python files drawn from GitHub, and associated documentation on the web for over 400 popular libraries, as well as StackOverflow posts about the same set of libraries. This knowledge graph will be made available soon to the larger community for use.