 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrca: Progressive Learning from Complex Explanation Traces of GPT-4
Jun 05, 2023



Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation signals from shallow LFM outputs; small scale homogeneous training data; and most notably a lack of rigorous evaluation resulting in overestimating the small model's capability as they tend to learn to imitate the style, but not the reasoning process of LFMs. To address these challenges, we develop Orca (We are working with our legal team to publicly release a diff of the model weights in accordance with LLaMA's release policy to be published at https://aka.ms/orca-lm), a 13-billion parameter model that learns to imitate the reasoning process of LFMs. Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. To promote this progressive learning, we tap into large-scale and diverse imitation data with judicious sampling and selection. Orca surpasses conventional state-of-the-art instruction-tuned models such as Vicuna-13B by more than 100% in complex zero-shot reasoning benchmarks like Big-Bench Hard (BBH) and 42% on AGIEval. Moreover, Orca reaches parity with ChatGPT on the BBH benchmark and shows competitive performance (4 pts gap with optimized system message) in professional and academic examinations like the SAT, LSAT, GRE, and GMAT, both in zero-shot settings without CoT; while trailing behind GPT-4. Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills.
GRILL: Grounded Vision-language Pre-training via Aligning Text and Image Regions
May 24, 2023



Generalization to unseen tasks is an important ability for few-shot learners to achieve better zero-/few-shot performance on diverse tasks. However, such generalization to vision-language tasks including grounding and generation tasks has been under-explored; existing few-shot VL models struggle to handle tasks that involve object grounding and multiple images such as visual commonsense reasoning or NLVR2. In this paper, we introduce GRILL, GRounded vIsion Language aLigning, a novel VL model that can be generalized to diverse tasks including visual question answering, captioning, and grounding tasks with no or very few training instances. Specifically, GRILL learns object grounding and localization by exploiting object-text alignments, which enables it to transfer to grounding tasks in a zero-/few-shot fashion. We evaluate our model on various zero-/few-shot VL tasks and show that it consistently surpasses the state-of-the-art few-shot methods.
A Systematic Study of Knowledge Distillation for Natural Language Generation with Pseudo-Target Training
May 03, 2023



Modern Natural Language Generation (NLG) models come with massive computational and storage requirements. In this work, we study the potential of compressing them, which is crucial for real-world applications serving millions of users. We focus on Knowledge Distillation (KD) techniques, in which a small student model learns to imitate a large teacher model, allowing to transfer knowledge from the teacher to the student. In contrast to much of the previous work, our goal is to optimize the model for a specific NLG task and a specific dataset. Typically, in real-world applications, in addition to labeled data there is abundant unlabeled task-specific data, which is crucial for attaining high compression rates via KD. In this work, we conduct a systematic study of task-specific KD techniques for various NLG tasks under realistic assumptions. We discuss the special characteristics of NLG distillation and particularly the exposure bias problem. Following, we derive a family of Pseudo-Target (PT) augmentation methods, substantially extending prior work on sequence-level KD. We propose the Joint-Teaching method for NLG distillation, which applies word-level KD to multiple PTs generated by both the teacher and the student. Our study provides practical model design observations and demonstrates the effectiveness of PT training for task-specific KD in NLG.
Accelerating Dataset Distillation via Model Augmentation
Dec 12, 2022



Dataset Distillation (DD), a newly emerging field, aims at generating much smaller and high-quality synthetic datasets from large ones. Existing DD methods based on gradient matching achieve leading performance; however, they are extremely computationally intensive as they require continuously optimizing a dataset among thousands of randomly initialized models. In this paper, we assume that training the synthetic data with diverse models leads to better generalization performance. Thus we propose two \textbf{model augmentation} techniques, ~\ie using \textbf{early-stage models} and \textbf{weight perturbation} to learn an informative synthetic set with significantly reduced training cost. Extensive experiments demonstrate that our method achieves up to 20$\times$ speedup and comparable performance on par with state-of-the-art baseline methods.
AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning
Nov 02, 2022



Standard fine-tuning of large pre-trained language models (PLMs) for downstream tasks requires updating hundreds of millions to billions of parameters, and storing a large copy of the PLM weights for every task resulting in increased cost for storing, sharing and serving the models. To address this, parameter-efficient fine-tuning (PEFT) techniques were introduced where small trainable components are injected in the PLM and updated during fine-tuning. We propose AdaMix as a general PEFT method that tunes a mixture of adaptation modules -- given the underlying PEFT method of choice -- introduced in each Transformer layer while keeping most of the PLM weights frozen. For instance, AdaMix can leverage a mixture of adapters like Houlsby or a mixture of low rank decomposition matrices like LoRA to improve downstream task performance over the corresponding PEFT methods for fully supervised and few-shot NLU and NLG tasks. Further, we design AdaMix such that it matches the same computational cost and the number of tunable parameters as the underlying PEFT method. By only tuning 0.1-0.2% of PLM parameters, we show that AdaMix outperforms SOTA parameter-efficient fine-tuning and full model fine-tuning for both NLU and NLG tasks.
AutoMoE: Neural Architecture Search for Efficient Sparsely Activated Transformers
Oct 14, 2022
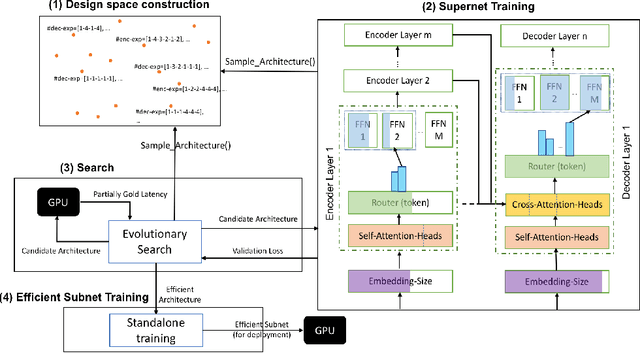


Neural architecture search (NAS) has demonstrated promising results on identifying efficient Transformer architectures which outperform manually designed ones for natural language tasks like neural machine translation (NMT). Existing NAS methods operate on a space of dense architectures, where all of the sub-architecture weights are activated for every input. Motivated by the recent advances in sparsely activated models like the Mixture-of-Experts (MoE) model, we introduce sparse architectures with conditional computation into the NAS search space. Given this expressive search space which subsumes prior densely activated architectures, we develop a new framework AutoMoE to search for efficient sparsely activated sub-Transformers. AutoMoE-generated sparse models obtain (i) 3x FLOPs reduction over manually designed dense Transformers and (ii) 23% FLOPs reduction over state-of-the-art NAS-generated dense sub-Transformers with parity in BLEU score on benchmark datasets for NMT. AutoMoE consists of three training phases: (a) Heterogeneous search space design with dense and sparsely activated Transformer modules (e.g., how many experts? where to place them? what should be their sizes?); (b) SuperNet training that jointly trains several subnetworks sampled from the large search space by weight-sharing; (c) Evolutionary search for the architecture with the optimal trade-off between task performance and computational constraint like FLOPs and latency. AutoMoE code, data and trained models are available at https://github.com/microsoft/AutoMoE.
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
Oct 06, 2022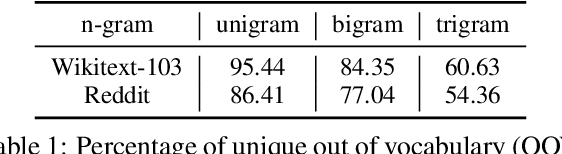
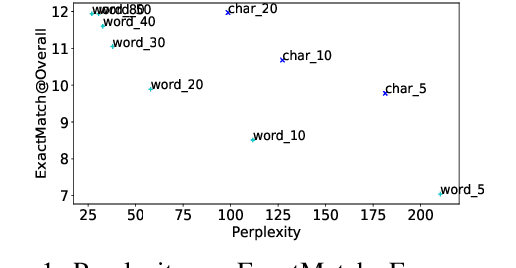
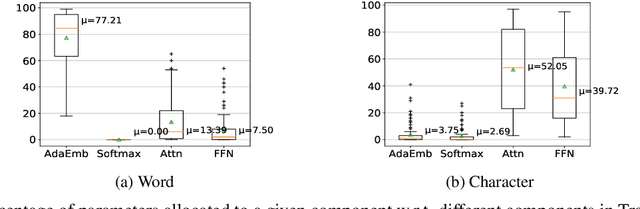
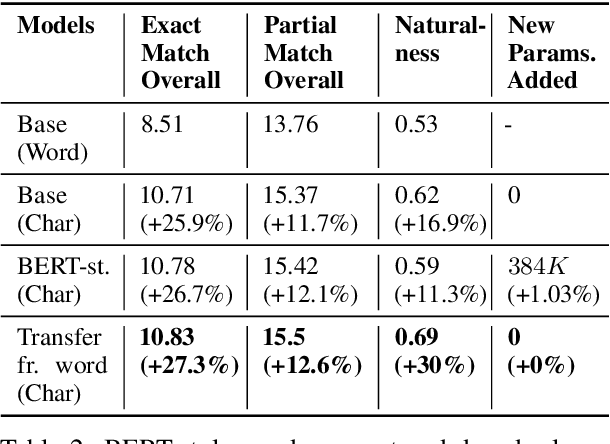
Autocomplete is a task where the user inputs a piece of text, termed prompt, which is conditioned by the model to generate semantically coherent continuation. Existing works for this task have primarily focused on datasets (e.g., email, chat) with high frequency user prompt patterns (or focused prompts) where word-based language models have been quite effective. In this work, we study the more challenging setting consisting of low frequency user prompt patterns (or broad prompts, e.g., prompt about 93rd academy awards) and demonstrate the effectiveness of character-based language models. We study this problem under memory-constrained settings (e.g., edge devices and smartphones), where character-based representation is effective in reducing the overall model size (in terms of parameters). We use WikiText-103 benchmark to simulate broad prompts and demonstrate that character models rival word models in exact match accuracy for the autocomplete task, when controlled for the model size. For instance, we show that a 20M parameter character model performs similar to an 80M parameter word model in the vanilla setting. We further propose novel methods to improve character models by incorporating inductive bias in the form of compositional information and representation transfer from large word models.
ADMoE: Anomaly Detection with Mixture-of-Experts from Noisy Labels
Aug 24, 2022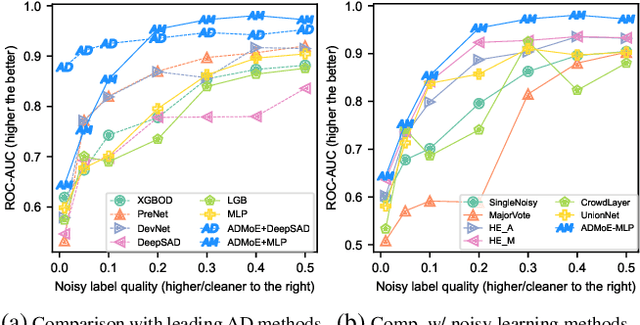
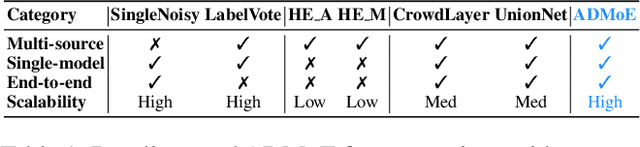
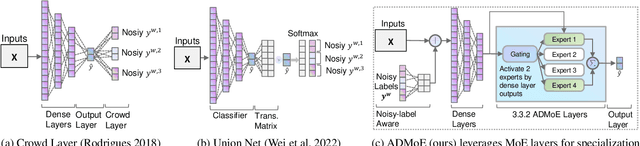
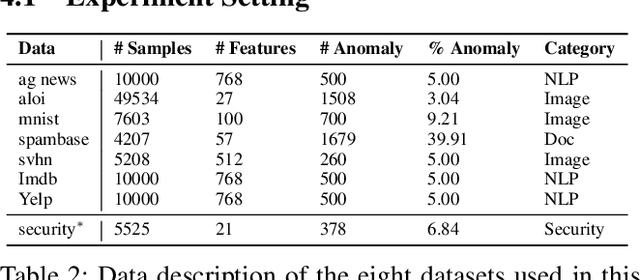
Existing works on anomaly detection (AD) rely on clean labels from human annotators that are expensive to acquire in practice. In this work, we propose a method to leverage weak/noisy labels (e.g., risk scores generated by machine rules for detecting malware) that are cheaper to obtain for anomaly detection. Specifically, we propose ADMoE, the first framework for anomaly detection algorithms to learn from noisy labels. In a nutshell, ADMoE leverages mixture-of-experts (MoE) architecture to encourage specialized and scalable learning from multiple noisy sources. It captures the similarities among noisy labels by sharing most model parameters, while encouraging specialization by building "expert" sub-networks. To further juice out the signals from noisy labels, ADMoE uses them as input features to facilitate expert learning. Extensive results on eight datasets (including a proprietary enterprise security dataset) demonstrate the effectiveness of ADMoE, where it brings up to 34% performance improvement over not using it. Also, it outperforms a total of 13 leading baselines with equivalent network parameters and FLOPS. Notably, ADMoE is model-agnostic to enable any neural network-based detection methods to handle noisy labels, where we showcase its results on both multiple-layer perceptron (MLP) and the leading AD method DeepSAD.
AdaMix: Mixture-of-Adapter for Parameter-efficient Tuning of Large Language Models
May 24, 2022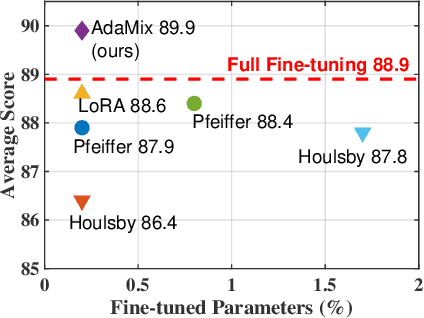
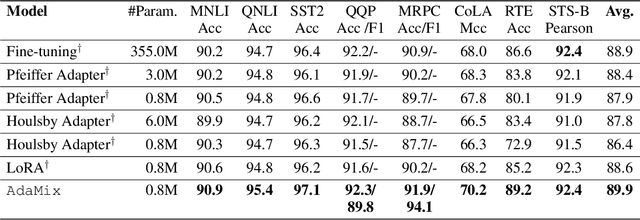
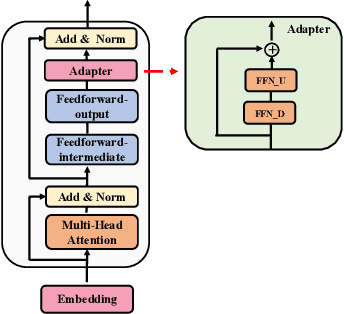
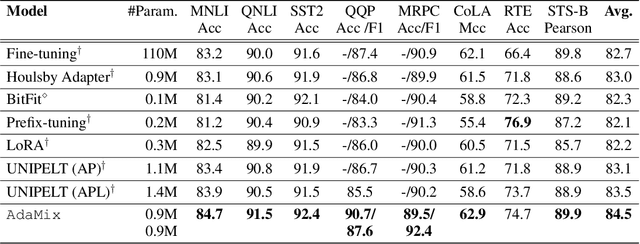
Fine-tuning large-scale pre-trained language models to downstream tasks require updating hundreds of millions of parameters. This not only increases the serving cost to store a large copy of the model weights for every task, but also exhibits instability during few-shot task adaptation. Parameter-efficient techniques have been developed that tune small trainable components (e.g., adapters) injected in the large model while keeping most of the model weights frozen. The prevalent mechanism to increase adapter capacity is to increase the bottleneck dimension which increases the adapter parameters. In this work, we introduce a new mechanism to improve adapter capacity without increasing parameters or computational cost by two key techniques. (i) We introduce multiple shared adapter components in each layer of the Transformer architecture. We leverage sparse learning via random routing to update the adapter parameters (encoder is kept frozen) resulting in the same amount of computational cost (FLOPs) as that of training a single adapter. (ii) We propose a simple merging mechanism to average the weights of multiple adapter components to collapse to a single adapter in each Transformer layer, thereby, keeping the overall parameters also the same but with significant performance improvement. We demonstrate these techniques to work well across multiple task settings including fully supervised and few-shot Natural Language Understanding tasks. By only tuning 0.23% of a pre-trained language model's parameters, our model outperforms the full model fine-tuning performance and several competing methods.
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners
Apr 16, 2022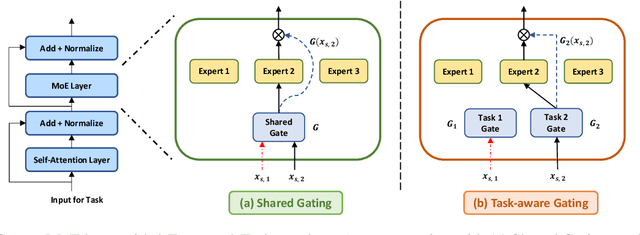
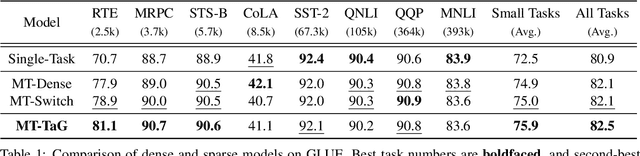
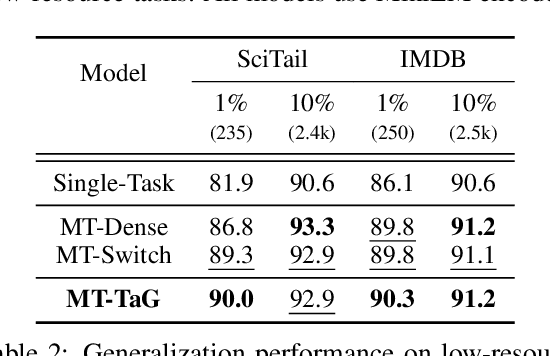
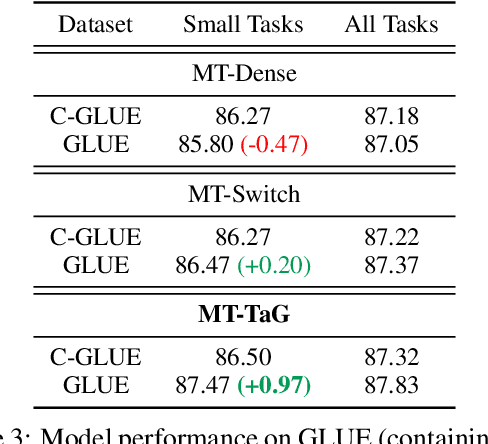
Traditional multi-task learning (MTL) methods use dense networks that use the same set of shared weights across several different tasks. This often creates interference where two or more tasks compete to pull model parameters in different directions. In this work, we study whether sparsely activated Mixture-of-Experts (MoE) improve multi-task learning by specializing some weights for learning shared representations and using the others for learning task-specific information. To this end, we devise task-aware gating functions to route examples from different tasks to specialized experts which share subsets of network weights conditioned on the task. This results in a sparsely activated multi-task model with a large number of parameters, but with the same computational cost as that of a dense model. We demonstrate such sparse networks to improve multi-task learning along three key dimensions: (i) transfer to low-resource tasks from related tasks in the training mixture; (ii) sample-efficient generalization to tasks not seen during training by making use of task-aware routing from seen related tasks; (iii) robustness to the addition of unrelated tasks by avoiding catastrophic forgetting of existing tasks.