 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2O-Calib: Camera-LiDAR Calibration Using Point-Pair Spatial Occlusion Relationship
Nov 04, 2023The accurate and robust calibration result of sensors is considered as an important building block to the follow-up research in the autonomous driving and robotics domain. The current works involving extrinsic calibration between 3D LiDARs and monocular cameras mainly focus on target-based and target-less methods. The target-based methods are often utilized offline because of restrictions, such as additional target design and target placement limits. The current target-less methods suffer from feature indeterminacy and feature mismatching in various environments. To alleviate these limitations, we propose a novel target-less calibration approach which is based on the 2D-3D edge point extraction using the occlusion relationship in 3D space. Based on the extracted 2D-3D point pairs, we further propose an occlusion-guided point-matching method that improves the calibration accuracy and reduces computation costs. To validate the effectiveness of our approach, we evaluate the method performance qualitatively and quantitatively on real images from the KITTI dataset. The results demonstrate that our method outperforms the existing target-less methods and achieves low error and high robustness that can contribute to the practical applications relying on high-quality Camera-LiDAR calibration.
* Accepted to IROS 2023. Presentation page: https://events.infovaya.com/presentation?id=103943
Davidsonian Scene Graph: Improving Reliability in Fine-grained Evaluation for Text-to-Image Generation
Oct 30, 2023



Evaluating text-to-image models is notoriously difficult. A strong recent approach for assessing text-image faithfulness is based on QG/A (question generation and answering), which uses pre-trained foundational models to automatically generate a set of questions and answers from the prompt, and output images are scored based on whether these answers extracted with a visual question answering model are consistent with the prompt-based answers. This kind of evaluation is naturally dependent on the quality of the underlying QG and QA models. We identify and address several reliability challenges in existing QG/A work: (a) QG questions should respect the prompt (avoiding hallucinations, duplications, and omissions) and (b) VQA answers should be consistent (not asserting that there is no motorcycle in an image while also claiming the motorcycle is blue). We address these issues with Davidsonian Scene Graph (DSG), an empirically grounded evaluation framework inspired by formal semantics. DSG is an automatic, graph-based QG/A that is modularly implemented to be adaptable to any QG/A module. DSG produces atomic and unique questions organized in dependency graphs, which (i) ensure appropriate semantic coverage and (ii) sidestep inconsistent answers. With extensive experimentation and human evaluation on a range of model configurations (LLM, VQA, and T2I), we empirically demonstrate that DSG addresses the challenges noted above. Finally, we present DSG-1k, an open-sourced evaluation benchmark that includes 1,060 prompts, covering a wide range of fine-grained semantic categories with a balanced distribution. We release the DSG-1k prompts and the corresponding DSG questions.
Mitigating Evasion Attacks in Federated Learning-Based Signal Classifiers
Jun 08, 2023There has been recent interest in leveraging federated learning (FL) for radio signal classification tasks. In FL, model parameters are periodically communicated from participating devices, which train on local datasets, to a central server which aggregates them into a global model. While FL has privacy/security advantages due to raw data not leaving the devices, it is still susceptible to adversarial attacks. In this work, we first reveal the susceptibility of FL-based signal classifiers to model poisoning attacks, which compromise the training process despite not observing data transmissions. In this capacity, we develop an attack framework that significantly degrades the training process of the global model. Our attack framework induces a more potent model poisoning attack to the global classifier than existing baselines while also being able to compromise existing server-driven defenses. In response to this gap, we develop Underlying Server Defense of Federated Learning (USD-FL), a novel defense methodology for FL-based signal classifiers. We subsequently compare the defensive efficacy, runtimes, and false positive detection rates of USD-FL relative to existing server-driven defenses, showing that USD-FL has notable advantages over the baseline defenses in all three areas.
Multi-Source to Multi-Target Decentralized Federated Domain Adaptation
Apr 24, 2023Heterogeneity across devices in federated learning (FL) typically refers to statistical (e.g., non-i.i.d. data distributions) and resource (e.g., communication bandwidth) dimensions. In this paper, we focus on another important dimension that has received less attention: varying quantities/distributions of labeled and unlabeled data across devices. In order to leverage all data, we develop a decentralized federated domain adaptation methodology which considers the transfer of ML models from devices with high quality labeled data (called sources) to devices with low quality or unlabeled data (called targets). Our methodology, Source-Target Determination and Link Formation (ST-LF), optimizes both (i) classification of devices into sources and targets and (ii) source-target link formation, in a manner that considers the trade-off between ML model accuracy and communication energy efficiency. To obtain a concrete objective function, we derive a measurable generalization error bound that accounts for estimates of source-target hypothesis deviations and divergences between data distributions. The resulting optimization problem is a mixed-integer signomial program, a class of NP-hard problems, for which we develop an algorithm based on successive convex approximations to solve it tractably. Subsequent numerical evaluations of ST-LF demonstrate that it improves classification accuracy and energy efficiency over state-of-the-art baselines.
Towards Cooperative Federated Learning over Heterogeneous Edge/Fog Networks
Mar 15, 2023



Federated learning (FL) has been promoted as a popular technique for training machine learning (ML) models over edge/fog networks. Traditional implementations of FL have largely neglected the potential for inter-network cooperation, treating edge/fog devices and other infrastructure participating in ML as separate processing elements. Consequently, FL has been vulnerable to several dimensions of network heterogeneity, such as varying computation capabilities, communication resources, data qualities, and privacy demands. We advocate for cooperative federated learning (CFL), a cooperative edge/fog ML paradigm built on device-to-device (D2D) and device-to-server (D2S) interactions. Through D2D and D2S cooperation, CFL counteracts network heterogeneity in edge/fog networks through enabling a model/data/resource pooling mechanism, which will yield substantial improvements in ML model training quality and network resource consumption. We propose a set of core methodologies that form the foundation of D2D and D2S cooperation and present preliminary experiments that demonstrate their benefits. We also discuss new FL functionalities enabled by this cooperative framework such as the integration of unlabeled data and heterogeneous device privacy into ML model training. Finally, we describe some open research directions at the intersection of cooperative edge/fog and FL.
Scaling Robot Learning with Semantically Imagined Experience
Feb 22, 2023



Recent advances in robot learning have shown promise in enabling robots to perform a variety of manipulation tasks and generalize to novel scenarios. One of the key contributing factors to this progress is the scale of robot data used to train the models. To obtain large-scale datasets, prior approaches have relied on either demonstrations requiring high human involvement or engineering-heavy autonomous data collection schemes, both of which are challenging to scale. To mitigate this issue, we propose an alternative route and leverage text-to-image foundation models widely used in computer vision and natural language processing to obtain meaningful data for robot learning without requiring additional robot data. We term our method Robot Learning with Semantically Imagened Experience (ROSIE). Specifically, we make use of the state of the art text-to-image diffusion models and perform aggressive data augmentation on top of our existing robotic manipulation datasets via inpainting various unseen objects for manipulation, backgrounds, and distractors with text guidance. Through extensive real-world experiments, we show that manipulation policies trained on data augmented this way are able to solve completely unseen tasks with new objects and can behave more robustly w.r.t. novel distractors. In addition, we find that we can improve the robustness and generalization of high-level robot learning tasks such as success detection through training with the diffusion-based data augmentation. The project's website and videos can be found at diffusion-rosie.github.io
How Potent are Evasion Attacks for Poisoning Federated Learning-Based Signal Classifiers?
Jan 21, 2023



There has been recent interest in leveraging federated learning (FL) for radio signal classification tasks. In FL, model parameters are periodically communicated from participating devices, training on their own local datasets, to a central server which aggregates them into a global model. While FL has privacy/security advantages due to raw data not leaving the devices, it is still susceptible to several adversarial attacks. In this work, we reveal the susceptibility of FL-based signal classifiers to model poisoning attacks, which compromise the training process despite not observing data transmissions. In this capacity, we develop an attack framework in which compromised FL devices perturb their local datasets using adversarial evasion attacks. As a result, the training process of the global model significantly degrades on in-distribution signals (i.e., signals received over channels with identical distributions at each edge device). We compare our work to previously proposed FL attacks and reveal that as few as one adversarial device operating with a low-powered perturbation under our attack framework can induce the potent model poisoning attack to the global classifier. Moreover, we find that more devices partaking in adversarial poisoning will proportionally degrade the classification performance.
Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022



Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.
A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning
Oct 06, 2022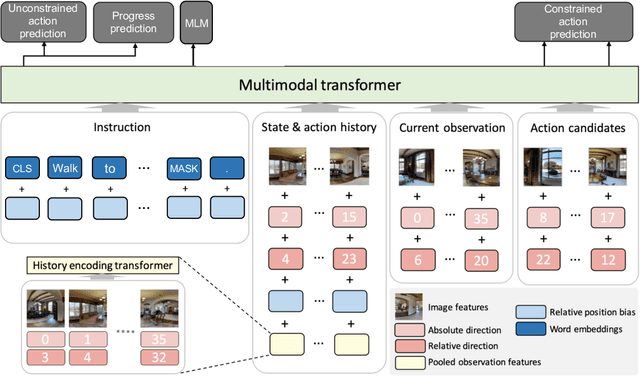
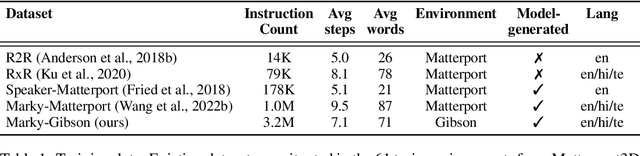
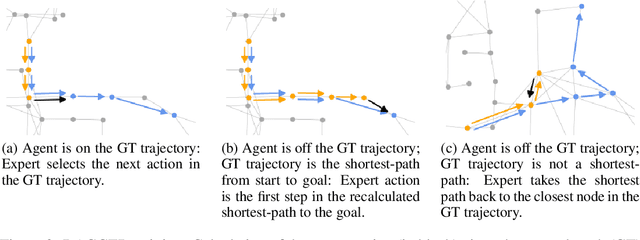

Recent studies in Vision-and-Language Navigation (VLN) train RL agents to execute natural-language navigation instructions in photorealistic environments, as a step towards intelligent agents or robots that can follow human instructions. However, given the scarcity of human instruction data and limited diversity in the training environments, these agents still struggle with complex language grounding and spatial language understanding. Pre-training on large text and image-text datasets from the web has been extensively explored but the improvements are limited. To address the scarcity of in-domain instruction data, we investigate large-scale augmentation with synthetic instructions. We take 500+ indoor environments captured in densely-sampled 360 deg panoramas, construct navigation trajectories through these panoramas, and generate a visually-grounded instruction for each trajectory using Marky (Wang et al., 2022), a high-quality multilingual navigation instruction generator. To further increase the variability of the trajectories, we also synthesize image observations from novel viewpoints using an image-to-image GAN. The resulting dataset of 4.2M instruction-trajectory pairs is two orders of magnitude larger than existing human-annotated datasets, and contains a wider variety of environments and viewpoints. To efficiently leverage data at this scale, we train a transformer agent with imitation learning for over 700M steps of experience. On the challenging Room-across-Room dataset, our approach outperforms all existing RL agents, improving the state-of-the-art NDTW from 71.1 to 79.1 in seen environments, and from 64.6 to 66.8 in unseen test environments. Our work points to a new path to improving instruction-following agents, emphasizing large-scale imitation learning and the development of synthetic instruction generation capabilities.
Parallel Successive Learning for Dynamic Distributed Model Training over Heterogeneous Wireless Networks
Feb 12, 2022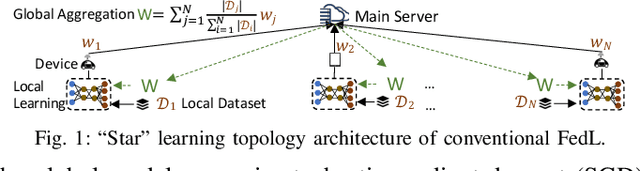
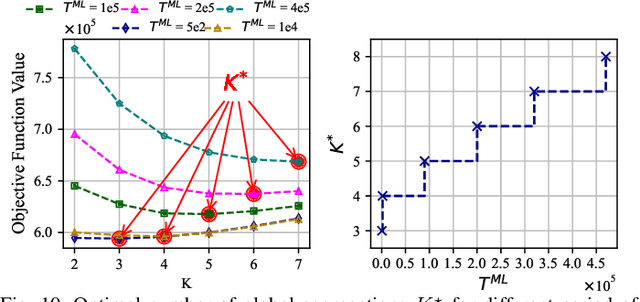
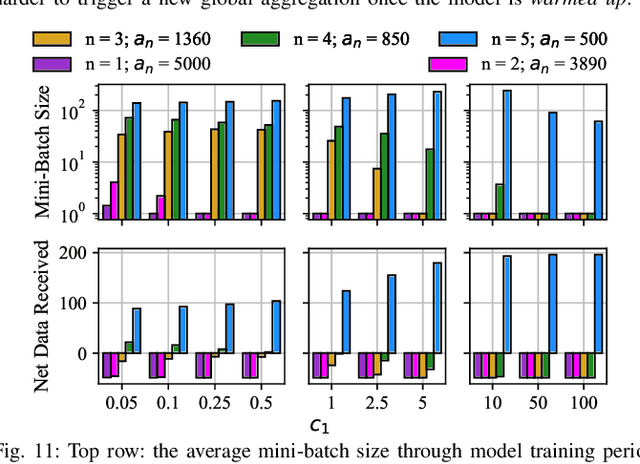
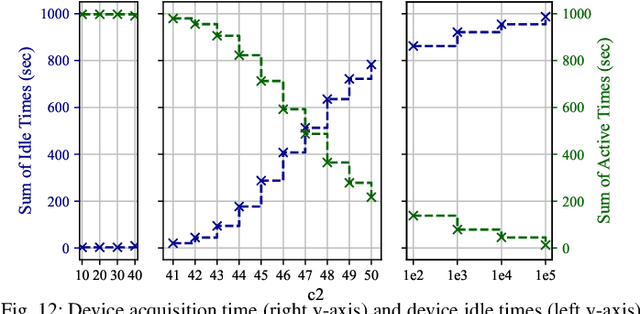
Federated learning (FedL) has emerged as a popular technique for distributing model training over a set of wireless devices, via iterative local updates (at devices) and global aggregations (at the server). In this paper, we develop parallel successive learning (PSL), which expands the FedL architecture along three dimensions: (i) Network, allowing decentralized cooperation among the devices via device-to-device (D2D) communications. (ii) Heterogeneity, interpreted at three levels: (ii-a) Learning: PSL considers heterogeneous number of stochastic gradient descent iterations with different mini-batch sizes at the devices; (ii-b) Data: PSL presumes a dynamic environment with data arrival and departure, where the distributions of local datasets evolve over time, captured via a new metric for model/concept drift. (ii-c) Device: PSL considers devices with different computation and communication capabilities. (iii) Proximity, where devices have different distances to each other and the access point. PSL considers the realistic scenario where global aggregations are conducted with idle times in-between them for resource efficiency improvements, and incorporates data dispersion and model dispersion with local model condensation into FedL. Our analysis sheds light on the notion of cold vs. warmed up models, and model inertia in distributed machine learning. We then propose network-aware dynamic model tracking to optimize the model learning vs. resource efficiency tradeoff, which we show is an NP-hard signomial programming problem. We finally solve this problem through proposing a general optimization solver. Our numerical results reveal new findings on the interdependencies between the idle times in-between the global aggregations, model/concept drift, and D2D cooperation configuration.