 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergence Minimization Preference Optimization for Diffusion Model Alignment
Jul 10, 2025Diffusion models have achieved remarkable success in generating realistic and versatile images from text prompts. Inspired by the recent advancements of language models, there is an increasing interest in further improving the models by aligning with human preferences. However, we investigate alignment from a divergence minimization perspective and reveal that existing preference optimization methods are typically trapped in suboptimal mean-seeking optimization. In this paper, we introduce Divergence Minimization Preference Optimization (DMPO), a novel and principled method for aligning diffusion models by minimizing reverse KL divergence, which asymptotically enjoys the same optimization direction as original RL. We provide rigorous analysis to justify the effectiveness of DMPO and conduct comprehensive experiments to validate its empirical strength across both human evaluations and automatic metrics. Our extensive results show that diffusion models fine-tuned with DMPO can consistently outperform or match existing techniques, specifically outperforming all existing diffusion alignment baselines by at least 64.6% in PickScore across all evaluation datasets, demonstrating the method's superiority in aligning generative behavior with desired outputs. Overall, DMPO unlocks a robust and elegant pathway for preference alignment, bridging principled theory with practical performance in diffusion models.
GeoAda: Efficiently Finetune Geometric Diffusion Models with Equivariant Adapters
Jul 02, 2025Geometric diffusion models have shown remarkable success in molecular dynamics and structure generation. However, efficiently fine-tuning them for downstream tasks with varying geometric controls remains underexplored. In this work, we propose an SE(3)-equivariant adapter framework ( GeoAda) that enables flexible and parameter-efficient fine-tuning for controlled generative tasks without modifying the original model architecture. GeoAda introduces a structured adapter design: control signals are first encoded through coupling operators, then processed by a trainable copy of selected pretrained model layers, and finally projected back via decoupling operators followed by an equivariant zero-initialized convolution. By fine-tuning only these lightweight adapter modules, GeoAda preserves the model's geometric consistency while mitigating overfitting and catastrophic forgetting. We theoretically prove that the proposed adapters maintain SE(3)-equivariance, ensuring that the geometric inductive biases of the pretrained diffusion model remain intact during adaptation. We demonstrate the wide applicability of GeoAda across diverse geometric control types, including frame control, global control, subgraph control, and a broad range of application domains such as particle dynamics, molecular dynamics, human motion prediction, and molecule generation. Empirical results show that GeoAda achieves state-of-the-art fine-tuning performance while preserving original task accuracy, whereas other baselines experience significant performance degradation due to overfitting and catastrophic forgetting.
Scaling Probabilistic Circuits via Monarch Matrices
Jun 14, 2025Probabilistic Circuits (PCs) are tractable representations of probability distributions allowing for exact and efficient computation of likelihoods and marginals. Recent advancements have improved the scalability of PCs either by leveraging their sparse properties or through the use of tensorized operations for better hardware utilization. However, no existing method fully exploits both aspects simultaneously. In this paper, we propose a novel sparse and structured parameterization for the sum blocks in PCs. By replacing dense matrices with sparse Monarch matrices, we significantly reduce the memory and computation costs, enabling unprecedented scaling of PCs. From a theory perspective, our construction arises naturally from circuit multiplication; from a practical perspective, compared to previous efforts on scaling up tractable probabilistic models, our approach not only achieves state-of-the-art generative modeling performance on challenging benchmarks like Text8, LM1B and ImageNet, but also demonstrates superior scaling behavior, achieving the same performance with substantially less compute as measured by the number of floating-point operations (FLOPs) during training.
Exploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
Reviving Any-Subset Autoregressive Models with Principled Parallel Sampling and Speculative Decoding
Apr 29, 2025



In arbitrary-order language models, it is an open question how to sample tokens in parallel from the correct joint distribution. With discrete diffusion models, the more tokens they generate in parallel, the less their predicted distributions adhere to the originally learned data distribution, as they rely on a conditional independence assumption that only works with infinitesimally small timesteps. We find that a different class of models, any-subset autoregressive models (AS-ARMs), holds the solution. As implied by the name, AS-ARMs can generate tokens in any order, and in parallel. Moreover, AS-ARMs support parallelized joint probability density estimation, allowing them to correct their own parallel-generated token distributions, via our Any-Subset Speculative Decoding (ASSD) algorithm. ASSD provably enables generation of tokens from the correct joint distribution, with the number of neural network calls upper bounded by the number of tokens predicted. We empirically verify that ASSD speeds up language generation, without sacrificing quality. Furthermore, we provide a mathematically justified scheme for training AS-ARMs for generation, and show that AS-ARMs achieve state-of-the-art performance among sub-200M parameter models on infilling benchmark tasks, and nearly match the performance of models 50X larger on code generation. Our theoretical and empirical results indicate that the once-forgotten AS-ARMs are a promising direction of language modeling.
Sharpe Ratio-Guided Active Learning for Preference Optimization in RLHF
Mar 28, 2025Reinforcement learning from human feedback (RLHF) has become a cornerstone of the training and alignment pipeline for large language models (LLMs). Recent advances, such as direct preference optimization (DPO), have simplified the preference learning step. However, collecting preference data remains a challenging and costly process, often requiring expert annotation. This cost can be mitigated by carefully selecting the data points presented for annotation. In this work, we propose an active learning approach to efficiently select prompt and preference pairs using a risk assessment strategy based on the Sharpe Ratio. To address the challenge of unknown preferences prior to annotation, our method evaluates the gradients of all potential preference annotations to assess their impact on model updates. These gradient-based evaluations enable risk assessment of data points regardless of the annotation outcome. By leveraging the DPO loss derivations, we derive a closed-form expression for computing these Sharpe ratios on a per-tuple basis, ensuring our approach remains both tractable and computationally efficient. We also introduce two variants of our method, each making different assumptions about prior information. Experimental results demonstrate that our method outperforms the baseline by up to 5% in win rates against the chosen completion with limited human preference data across several language models and real-world datasets.
Preference-Guided Diffusion for Multi-Objective Offline Optimization
Mar 21, 2025



Offline multi-objective optimization aims to identify Pareto-optimal solutions given a dataset of designs and their objective values. In this work, we propose a preference-guided diffusion model that generates Pareto-optimal designs by leveraging a classifier-based guidance mechanism. Our guidance classifier is a preference model trained to predict the probability that one design dominates another, directing the diffusion model toward optimal regions of the design space. Crucially, this preference model generalizes beyond the training distribution, enabling the discovery of Pareto-optimal solutions outside the observed dataset. We introduce a novel diversity-aware preference guidance, augmenting Pareto dominance preference with diversity criteria. This ensures that generated solutions are optimal and well-distributed across the objective space, a capability absent in prior generative methods for offline multi-objective optimization. We evaluate our approach on various continuous offline multi-objective optimization tasks and find that it consistently outperforms other inverse/generative approaches while remaining competitive with forward/surrogate-based optimization methods. Our results highlight the effectiveness of classifier-guided diffusion models in generating diverse and high-quality solutions that approximate the Pareto front well.
Inductive Moment Matching
Mar 11, 2025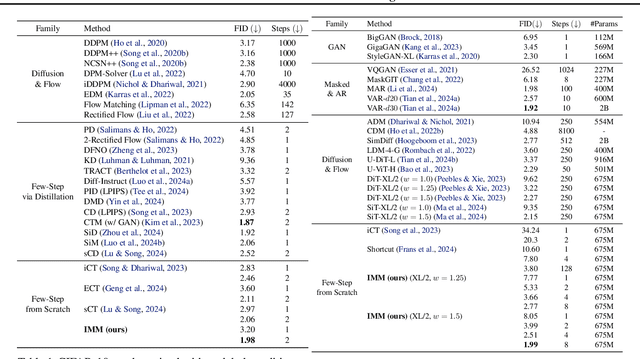
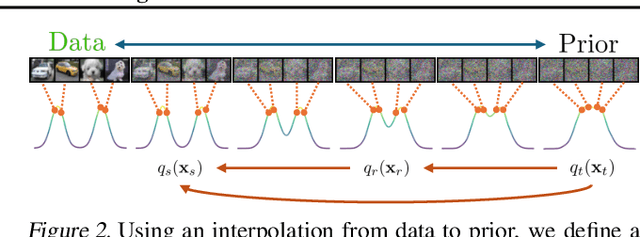
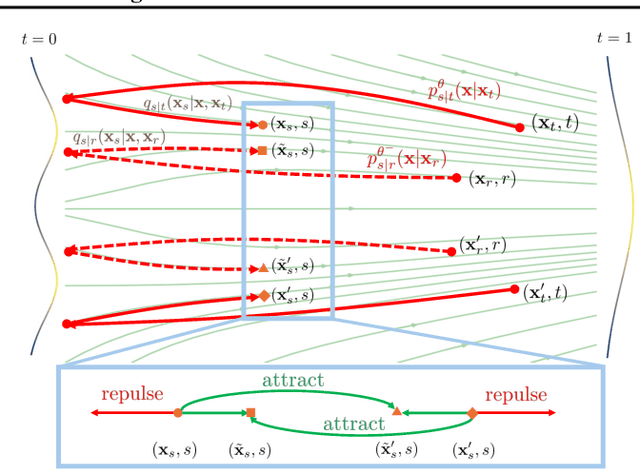
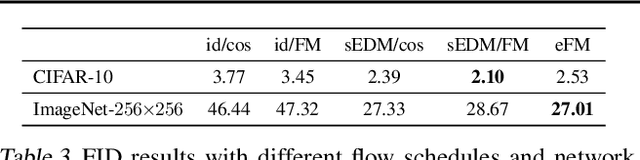
Diffusion models and Flow Matching generate high-quality samples but are slow at inference, and distilling them into few-step models often leads to instability and extensive tuning. To resolve these trade-offs, we propose Inductive Moment Matching (IMM), a new class of generative models for one- or few-step sampling with a single-stage training procedure. Unlike distillation, IMM does not require pre-training initialization and optimization of two networks; and unlike Consistency Models, IMM guarantees distribution-level convergence and remains stable under various hyperparameters and standard model architectures. IMM surpasses diffusion models on ImageNet-256x256 with 1.99 FID using only 8 inference steps and achieves state-of-the-art 2-step FID of 1.98 on CIFAR-10 for a model trained from scratch.
Data Unlearning in Diffusion Models
Mar 02, 2025Recent work has shown that diffusion models memorize and reproduce training data examples. At the same time, large copyright lawsuits and legislation such as GDPR have highlighted the need for erasing datapoints from diffusion models. However, retraining from scratch is often too expensive. This motivates the setting of data unlearning, i.e., the study of efficient techniques for unlearning specific datapoints from the training set. Existing concept unlearning techniques require an anchor prompt/class/distribution to guide unlearning, which is not available in the data unlearning setting. General-purpose machine unlearning techniques were found to be either unstable or failed to unlearn data. We therefore propose a family of new loss functions called Subtracted Importance Sampled Scores (SISS) that utilize importance sampling and are the first method to unlearn data with theoretical guarantees. SISS is constructed as a weighted combination between simpler objectives that are responsible for preserving model quality and unlearning the targeted datapoints. When evaluated on CelebA-HQ and MNIST, SISS achieved Pareto optimality along the quality and unlearning strength dimensions. On Stable Diffusion, SISS successfully mitigated memorization on nearly 90% of the prompts we tested.
FSPO: Few-Shot Preference Optimization of Synthetic Preference Data in LLMs Elicits Effective Personalization to Real Users
Feb 26, 2025Effective personalization of LLMs is critical for a broad range of user-interfacing applications such as virtual assistants and content curation. Inspired by the strong in-context learning capabilities of LLMs, we propose Few-Shot Preference Optimization (FSPO), which reframes reward modeling as a meta-learning problem. Under this framework, an LLM learns to quickly adapt to a user via a few labeled preferences from that user, constructing a personalized reward function for them. Additionally, since real-world preference data is scarce and challenging to collect at scale, we propose careful design choices to construct synthetic preference datasets for personalization, generating over 1M synthetic personalized preferences using publicly available LLMs. In particular, to successfully transfer from synthetic data to real users, we find it crucial for the data to exhibit both high diversity and coherent, self-consistent structure. We evaluate FSPO on personalized open-ended generation for up to 1,500 synthetic users across across three domains: movie reviews, pedagogical adaptation based on educational background, and general question answering, along with a controlled human study. Overall, FSPO achieves an 87% Alpaca Eval winrate on average in generating responses that are personalized to synthetic users and a 72% winrate with real human users in open-ended question answering.