 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing Earlier what Right Means to You: A Comprehensive VQA Dataset for Grounding Relative Directions via Multi-Task Learning
Jul 06, 2022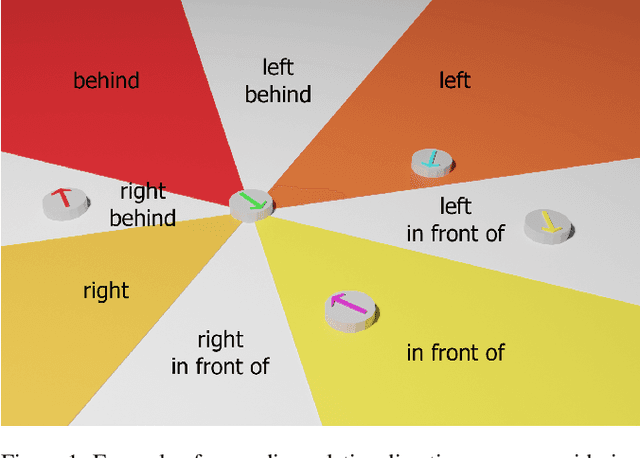

Spatial reasoning poses a particular challenge for intelligent agents and is at the same time a prerequisite for their successful interaction and communication in the physical world. One such reasoning task is to describe the position of a target object with respect to the intrinsic orientation of some reference object via relative directions. In this paper, we introduce GRiD-A-3D, a novel diagnostic visual question-answering (VQA) dataset based on abstract objects. Our dataset allows for a fine-grained analysis of end-to-end VQA models' capabilities to ground relative directions. At the same time, model training requires considerably fewer computational resources compared with existing datasets, yet yields a comparable or even higher performance. Along with the new dataset, we provide a thorough evaluation based on two widely known end-to-end VQA architectures trained on GRiD-A-3D. We demonstrate that within a few epochs, the subtasks required to reason over relative directions, such as recognizing and locating objects in a scene and estimating their intrinsic orientations, are learned in the order in which relative directions are intuitively processed.
GASP: Gated Attention For Saliency Prediction
Jun 09, 2022
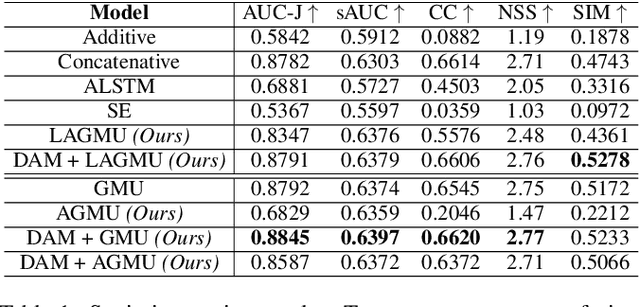
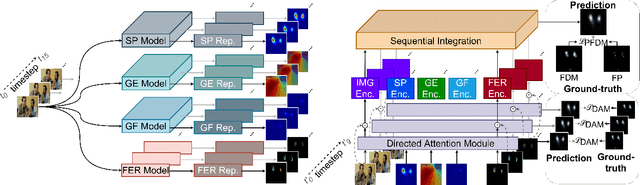
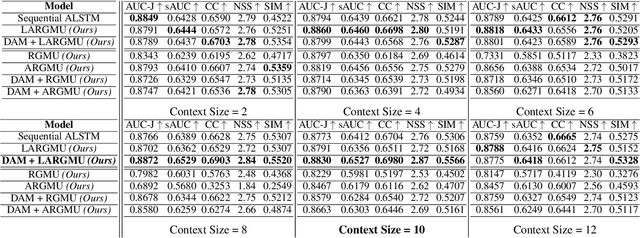
Saliency prediction refers to the computational task of modeling overt attention. Social cues greatly influence our attention, consequently altering our eye movements and behavior. To emphasize the efficacy of such features, we present a neural model for integrating social cues and weighting their influences. Our model consists of two stages. During the first stage, we detect two social cues by following gaze, estimating gaze direction, and recognizing affect. These features are then transformed into spatiotemporal maps through image processing operations. The transformed representations are propagated to the second stage (GASP) where we explore various techniques of late fusion for integrating social cues and introduce two sub-networks for directing attention to relevant stimuli. Our experiments indicate that fusion approaches achieve better results for static integration methods, whereas non-fusion approaches for which the influence of each modality is unknown, result in better outcomes when coupled with recurrent models for dynamic saliency prediction. We show that gaze direction and affective representations contribute a prediction to ground-truth correspondence improvement of at least 5% compared to dynamic saliency models without social cues. Furthermore, affective representations improve GASP, supporting the necessity of considering affect-biased attention in predicting saliency.
* International Joint Conference on Artificial Intelligence (IJCAI-21)
Snapture -- A Novel Neural Architecture for Combined Static and Dynamic Hand Gesture Recognition
May 28, 2022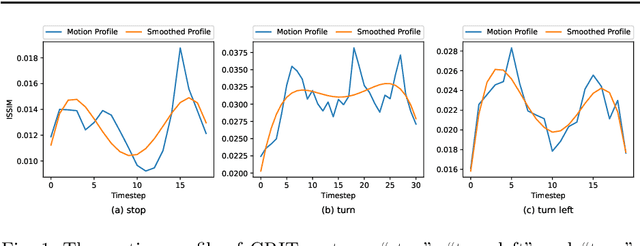

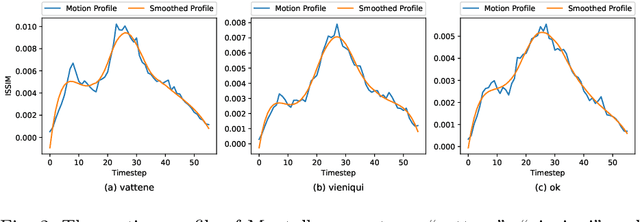
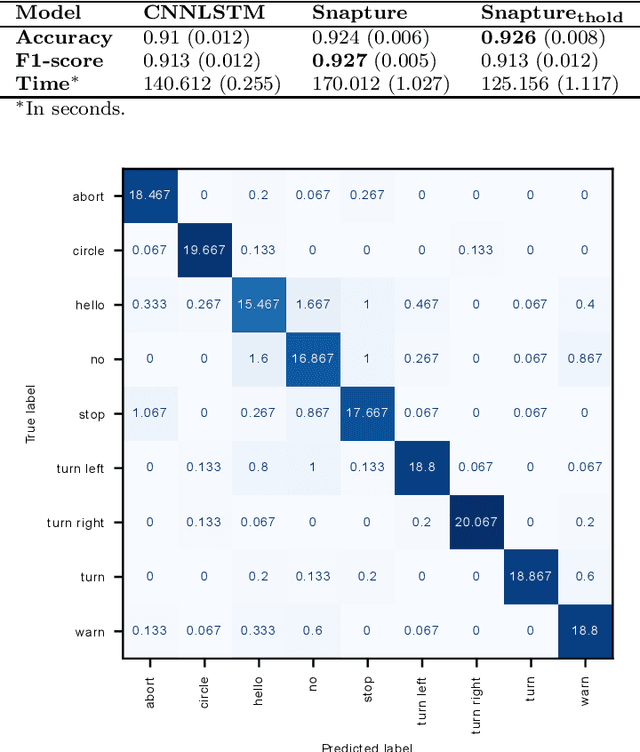
As robots are expected to get more involved in people's everyday lives, frameworks that enable intuitive user interfaces are in demand. Hand gesture recognition systems provide a natural way of communication and, thus, are an integral part of seamless Human-Robot Interaction (HRI). Recent years have witnessed an immense evolution of computational models powered by deep learning. However, state-of-the-art models fall short in expanding across different gesture domains, such as emblems and co-speech. In this paper, we propose a novel hybrid hand gesture recognition system. Our architecture enables learning both static and dynamic gestures: by capturing a so-called "snapshot" of the gesture performance at its peak, we integrate the hand pose along with the dynamic movement. Moreover, we present a method for analyzing the motion profile of a gesture to uncover its dynamic characteristics and which allows regulating a static channel based on the amount of motion. Our evaluation demonstrates the superiority of our approach on two gesture benchmarks compared to a CNNLSTM baseline. We also provide an analysis on a gesture class basis that unveils the potential of our Snapture architecture for performance improvements. Thanks to its modular implementation, our framework allows the integration of other multimodal data like facial expressions and head tracking, which are important cues in HRI scenarios, into one architecture. Thus, our work contributes both to gesture recognition research and machine learning applications for non-verbal communication with robots.
Conversational Analysis of Daily Dialog Data using Polite Emotional Dialogue Acts
May 11, 2022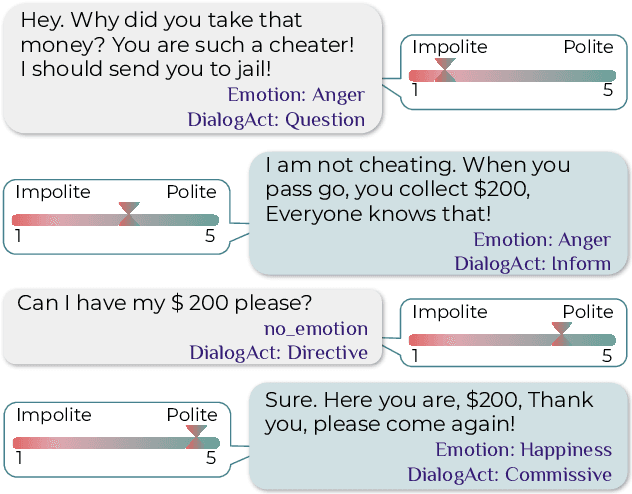
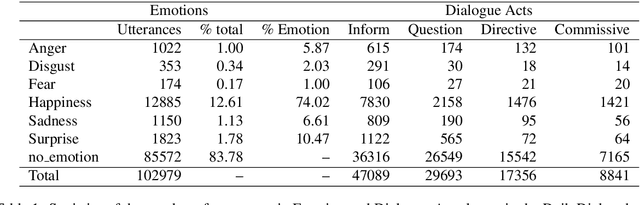
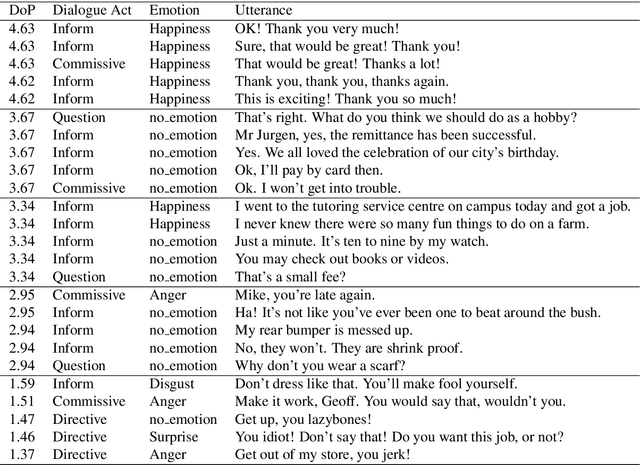
Many socio-linguistic cues are used in conversational analysis, such as emotion, sentiment, and dialogue acts. One of the fundamental cues is politeness, which linguistically possesses properties such as social manners useful in conversational analysis. This article presents findings of polite emotional dialogue act associations, where we can correlate the relationships between the socio-linguistic cues. We confirm our hypothesis that the utterances with the emotion classes Anger and Disgust are more likely to be impolite. At the same time, Happiness and Sadness are more likely to be polite. A less expectable phenomenon occurs with dialogue acts Inform and Commissive which contain more polite utterances than Question and Directive. Finally, we conclude on the future work of these findings to extend the learning of social behaviours using politeness.
What is Right for Me is Not Yet Right for You: A Dataset for Grounding Relative Directions via Multi-Task Learning
May 05, 2022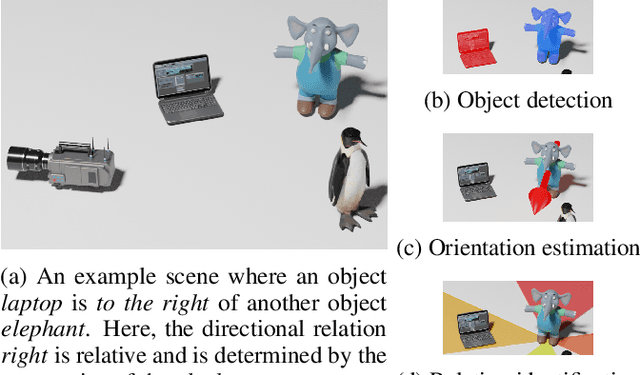


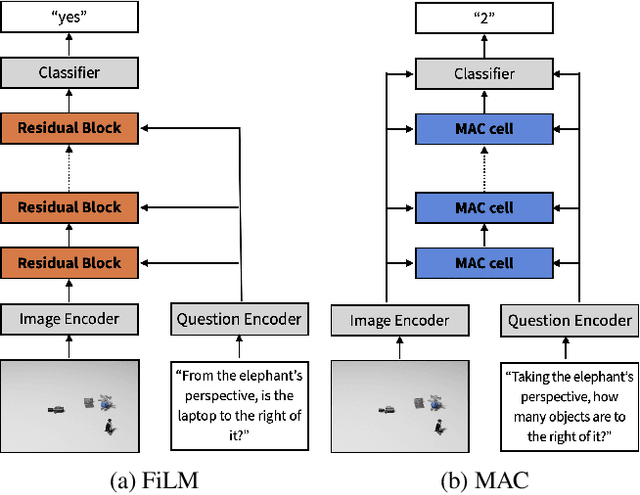
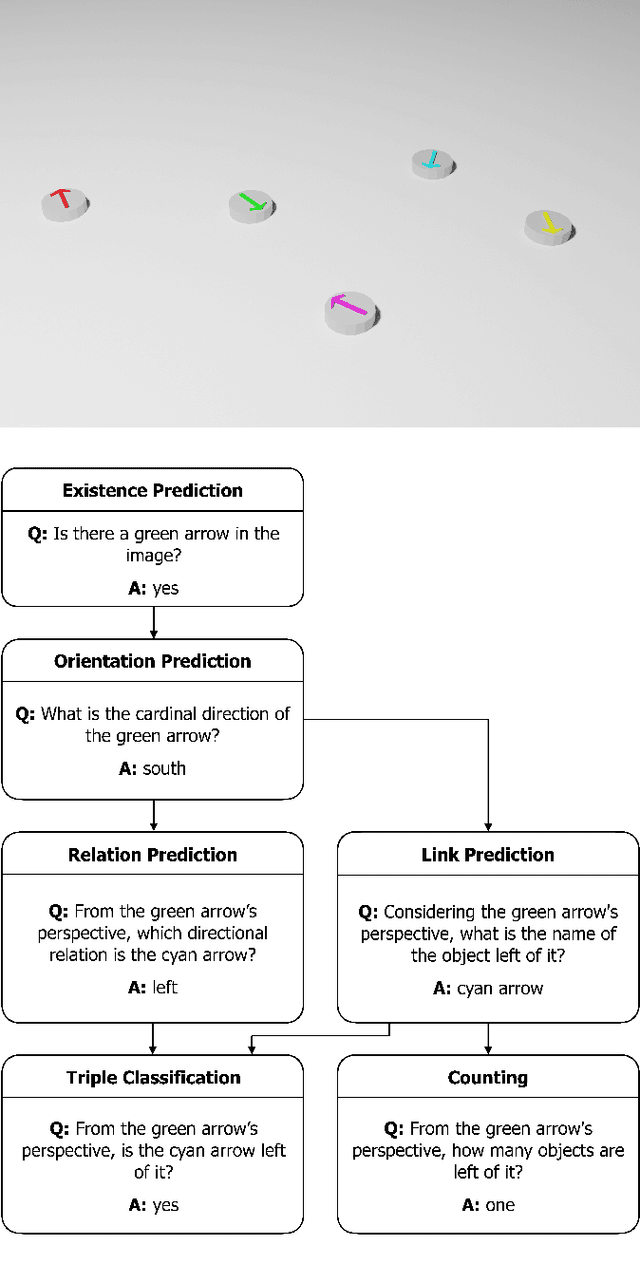
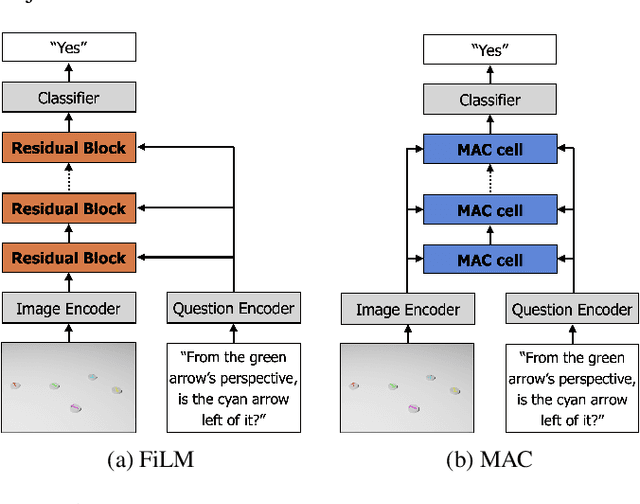
Understanding spatial relations is essential for intelligent agents to act and communicate in the physical world. Relative directions are spatial relations that describe the relative positions of target objects with regard to the intrinsic orientation of reference objects. Grounding relative directions is more difficult than grounding absolute directions because it not only requires a model to detect objects in the image and to identify spatial relation based on this information, but it also needs to recognize the orientation of objects and integrate this information into the reasoning process. We investigate the challenging problem of grounding relative directions with end-to-end neural networks. To this end, we provide GRiD-3D, a novel dataset that features relative directions and complements existing visual question answering (VQA) datasets, such as CLEVR, that involve only absolute directions. We also provide baselines for the dataset with two established end-to-end VQA models. Experimental evaluations show that answering questions on relative directions is feasible when questions in the dataset simulate the necessary subtasks for grounding relative directions. We discover that those subtasks are learned in an order that reflects the steps of an intuitive pipeline for processing relative directions.
Explain yourself! Effects of Explanations in Human-Robot Interaction
Apr 09, 2022

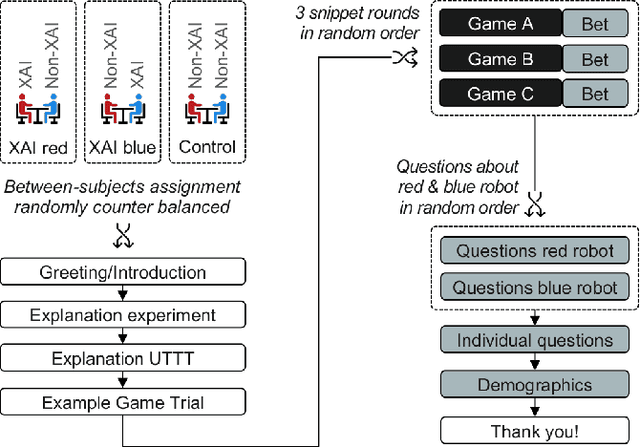
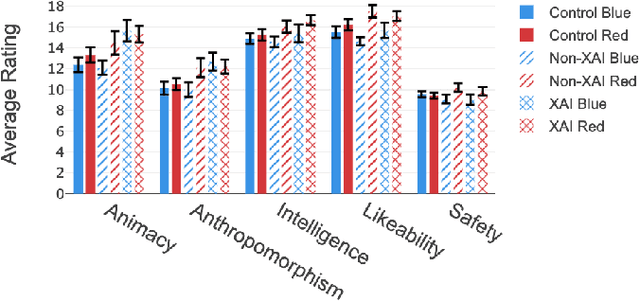
Recent developments in explainable artificial intelligence promise the potential to transform human-robot interaction: Explanations of robot decisions could affect user perceptions, justify their reliability, and increase trust. However, the effects on human perceptions of robots that explain their decisions have not been studied thoroughly. To analyze the effect of explainable robots, we conduct a study in which two simulated robots play a competitive board game. While one robot explains its moves, the other robot only announces them. Providing explanations for its actions was not sufficient to change the perceived competence, intelligence, likeability or safety ratings of the robot. However, the results show that the robot that explains its moves is perceived as more lively and human-like. This study demonstrates the need for and potential of explainable human-robot interaction and the wider assessment of its effects as a novel research direction.
Grounding Hindsight Instructions in Multi-Goal Reinforcement Learning for Robotics
Apr 08, 2022

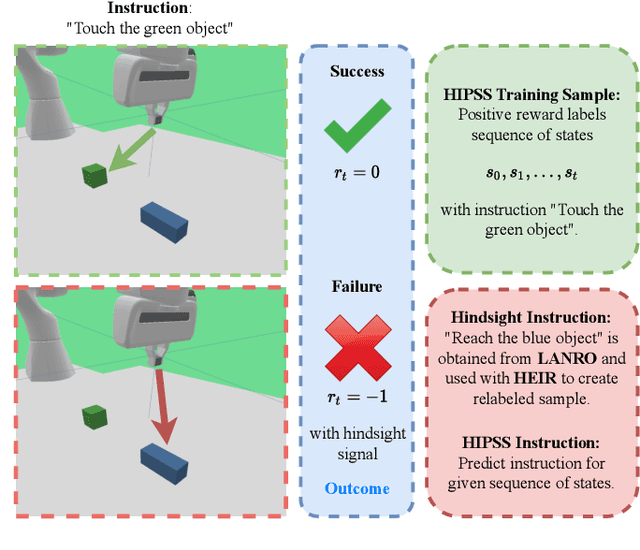
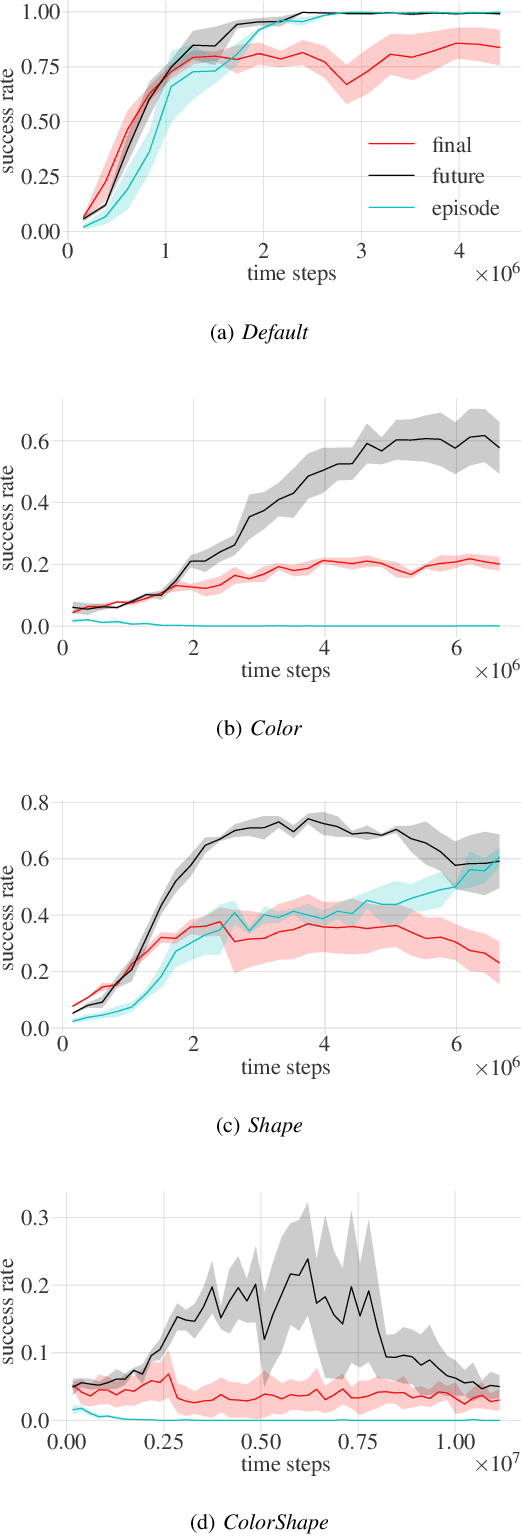
This paper focuses on robotic reinforcement learning with sparse rewards for natural language goal representations. An open problem is the sample-inefficiency that stems from the compositionality of natural language, and from the grounding of language in sensory data and actions. We address these issues with three contributions. We first present a mechanism for hindsight instruction replay utilizing expert feedback. Second, we propose a seq2seq model to generate linguistic hindsight instructions. Finally, we present a novel class of language-focused learning tasks. We show that hindsight instructions improve the learning performance, as expected. In addition, we also provide an unexpected result: We show that the learning performance of our agent can be improved by one third if, in a sense, the agent learns to talk to itself in a self-supervised manner. We achieve this by learning to generate linguistic instructions that would have been appropriate as a natural language goal for an originally unintended behavior. Our results indicate that the performance gain increases with the task-complexity.
Integrating Statistical Uncertainty into Neural Network-Based Speech Enhancement
Mar 04, 2022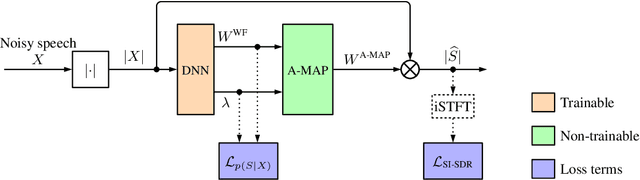
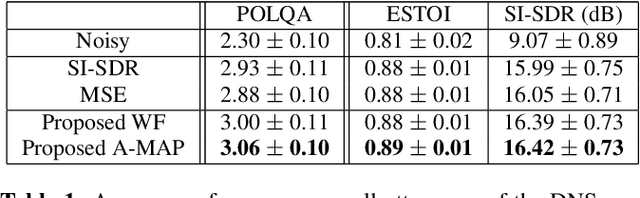
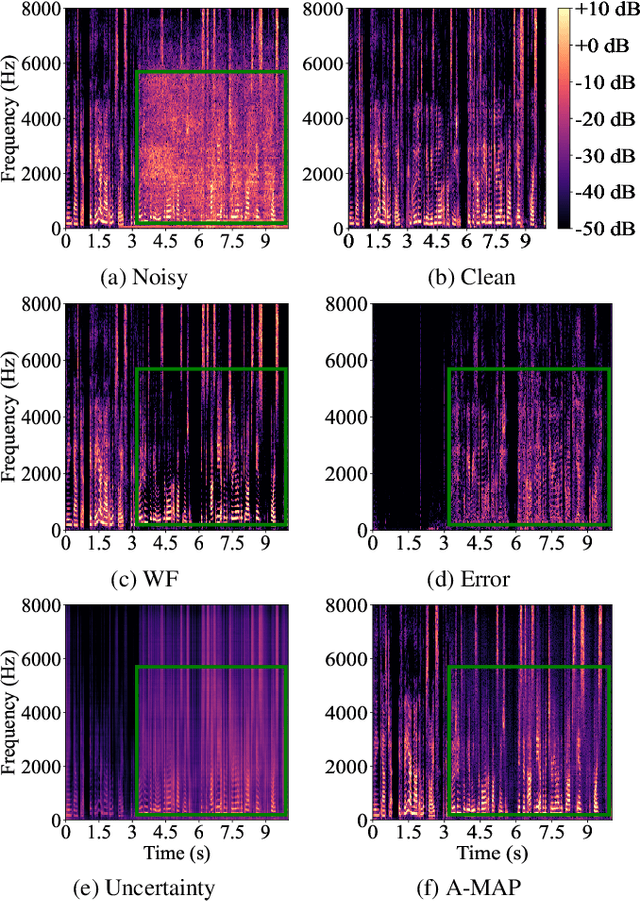
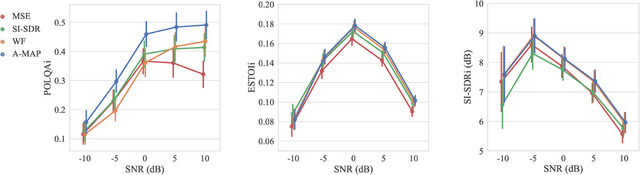
Speech enhancement in the time-frequency domain is often performed by estimating a multiplicative mask to extract clean speech. However, most neural network-based methods perform point estimation, i.e., their output consists of a single mask. In this paper, we study the benefits of modeling uncertainty in neural network-based speech enhancement. For this, our neural network is trained to map a noisy spectrogram to the Wiener filter and its associated variance, which quantifies uncertainty, based on the maximum a posteriori (MAP) inference of spectral coefficients. By estimating the distribution instead of the point estimate, one can model the uncertainty associated with each estimate. We further propose to use the estimated Wiener filter and its uncertainty to build an approximate MAP (A-MAP) estimator of spectral magnitudes, which in turn is combined with the MAP inference of spectral coefficients to form a hybrid loss function to jointly reinforce the estimation. Experimental results on different datasets show that the proposed method can not only capture the uncertainty associated with the estimated filters, but also yield a higher enhancement performance over comparable models that do not take uncertainty into account.
* \copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
A Multimodal German Dataset for Automatic Lip Reading Systems and Transfer Learning
Feb 27, 2022
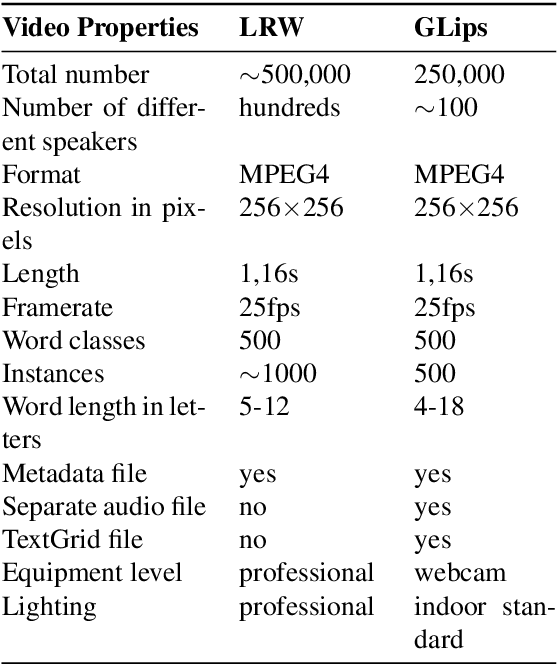
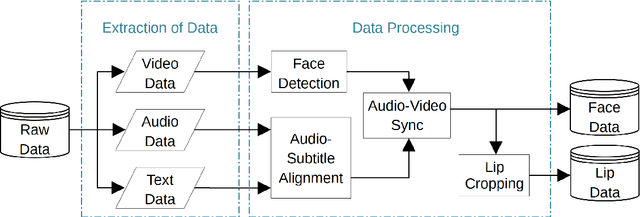

Large datasets as required for deep learning of lip reading do not exist in many languages. In this paper we present the dataset GLips (German Lips) consisting of 250,000 publicly available videos of the faces of speakers of the Hessian Parliament, which was processed for word-level lip reading using an automatic pipeline. The format is similar to that of the English language LRW (Lip Reading in the Wild) dataset, with each video encoding one word of interest in a context of 1.16 seconds duration, which yields compatibility for studying transfer learning between both datasets. By training a deep neural network, we investigate whether lip reading has language-independent features, so that datasets of different languages can be used to improve lip reading models. We demonstrate learning from scratch and show that transfer learning from LRW to GLips and vice versa improves learning speed and performance, in particular for the validation set.
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Jan 17, 2022
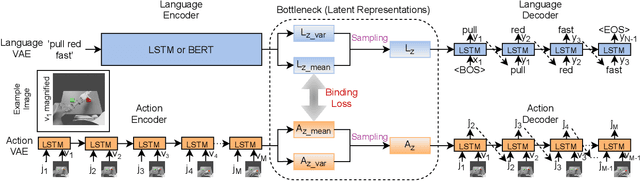
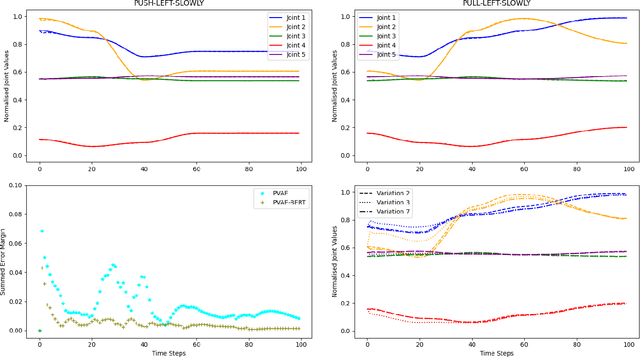
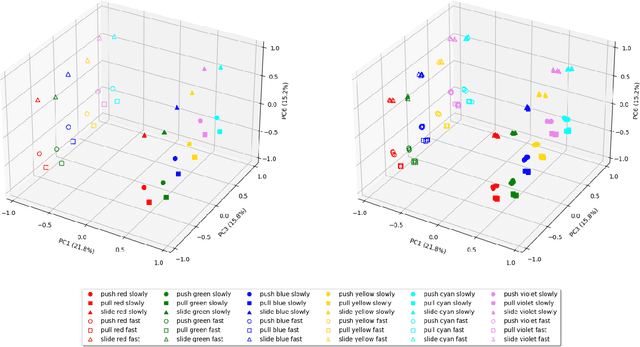
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.