 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Rigid-Body Approximation of Human Hands with Application to Digital Twin
Dec 08, 2025Human hand simulation plays a critical role in digital twin applications, requiring models that balance anatomical fidelity with computational efficiency. We present a complete pipeline for constructing multi-rigid-body approximations of human hands that preserve realistic appearance while enabling real-time physics simulation. Starting from optical motion capture of a specific human hand, we construct a personalized MANO (Multi-Abstracted hand model with Neural Operations) model and convert it to a URDF (Unified Robot Description Format) representation with anatomically consistent joint axes. The key technical challenge is projecting MANO's unconstrained SO(3) joint rotations onto the kinematically constrained joints of the rigid-body model. We derive closed-form solutions for single degree-of-freedom joints and introduce a Baker-Campbell-Hausdorff (BCH)-corrected iterative method for two degree-of-freedom joints that properly handles the non-commutativity of rotations. We validate our approach through digital twin experiments where reinforcement learning policies control the multi-rigid-body hand to replay captured human demonstrations. Quantitative evaluation shows sub-centimeter reconstruction error and successful grasp execution across diverse manipulation tasks.
Development of the Bioinspired Tendon-Driven DexHand 021 with Proprioceptive Compliance Control
Nov 05, 2025The human hand plays a vital role in daily life and industrial applications, yet replicating its multifunctional capabilities-including motion, sensing, and coordinated manipulation-with robotic systems remains a formidable challenge. Developing a dexterous robotic hand requires balancing human-like agility with engineering constraints such as complexity, size-to-weight ratio, durability, and force-sensing performance. This letter presents Dex-Hand 021, a high-performance, cable-driven five-finger robotic hand with 12 active and 7 passive degrees of freedom (DoFs), achieving 19 DoFs dexterity in a lightweight 1 kg design. We propose a proprioceptive force-sensing-based admittance control method to enhance manipulation. Experimental results demonstrate its superior performance: a single-finger load capacity exceeding 10 N, fingertip repeatability under 0.001 m, and force estimation errors below 0.2 N. Compared to PID control, joint torques in multi-object grasping are reduced by 31.19%, significantly improves force-sensing capability while preventing overload during collisions. The hand excels in both power and precision grasps, successfully executing 33 GRASP taxonomy motions and complex manipulation tasks. This work advances the design of lightweight, industrial-grade dexterous hands and enhances proprioceptive control, contributing to robotic manipulation and intelligent manufacturing.
SLATE: A Sequence Labeling Approach for Task Extraction from Free-form Inked Content
Nov 17, 2022



We present SLATE, a sequence labeling approach for extracting tasks from free-form content such as digitally handwritten (or "inked") notes on a virtual whiteboard. Our approach allows us to create a single, low-latency model to simultaneously perform sentence segmentation and classification of these sentences into task/non-task sentences. SLATE greatly outperforms a baseline two-model (sentence segmentation followed by classification model) approach, achieving a task F1 score of 84.4%, a sentence segmentation (boundary similarity) score of 88.4% and three times lower latency compared to the baseline. Furthermore, we provide insights into tackling challenges of performing NLP on the inking domain. We release both our code and dataset for this novel task.
Only Train Once: A One-Shot Neural Network Training And Pruning Framework
Jul 15, 2021

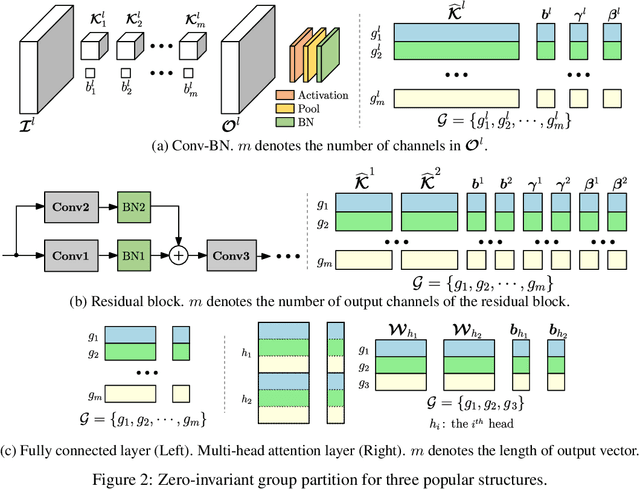
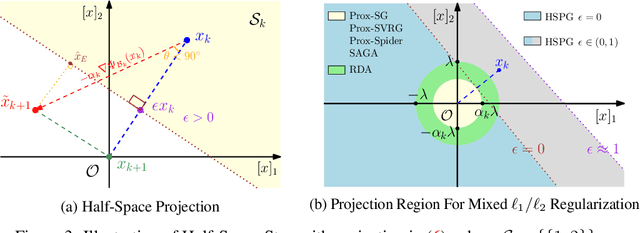
Structured pruning is a commonly used technique in deploying deep neural networks (DNNs) onto resource-constrained devices. However, the existing pruning methods are usually heuristic, task-specified, and require an extra fine-tuning procedure. To overcome these limitations, we propose a framework that compresses DNNs into slimmer architectures with competitive performances and significant FLOPs reductions by Only-Train-Once (OTO). OTO contains two keys: (i) we partition the parameters of DNNs into zero-invariant groups, enabling us to prune zero groups without affecting the output; and (ii) to promote zero groups, we then formulate a structured-sparsity optimization problem and propose a novel optimization algorithm, Half-Space Stochastic Projected Gradient (HSPG), to solve it, which outperforms the standard proximal methods on group sparsity exploration and maintains comparable convergence. To demonstrate the effectiveness of OTO, we train and compress full models simultaneously from scratch without fine-tuning for inference speedup and parameter reduction, and achieve state-of-the-art results on VGG16 for CIFAR10, ResNet50 for CIFAR10/ImageNet and Bert for SQuAD.
Neural Network Compression Via Sparse Optimization
Nov 11, 2020
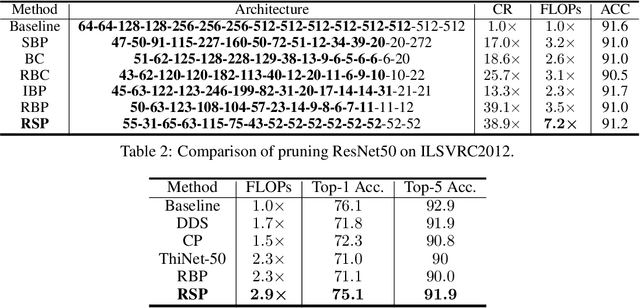
The compression of deep neural networks (DNNs) to reduce inference cost becomes increasingly important to meet realistic deployment requirements of various applications. There have been a significant amount of work regarding network compression, while most of them are heuristic rule-based or typically not friendly to be incorporated into varying scenarios. On the other hand, sparse optimization yielding sparse solutions naturally fits the compression requirement, but due to the limited study of sparse optimization in stochastic learning, its extension and application onto model compression is rarely well explored. In this work, we propose a model compression framework based on the recent progress on sparse stochastic optimization. Compared to existing model compression techniques, our method is effective and requires fewer extra engineering efforts to incorporate with varying applications, and has been numerically demonstrated on benchmark compression tasks. Particularly, we achieve up to 7.2 and 2.9 times FLOPs reduction with the same level of evaluation accuracy on VGG16 for CIFAR10 and ResNet50 for ImageNet compared to the baseline heavy models, respectively.
Orthant Based Proximal Stochastic Gradient Method for $\ell_1$-Regularized Optimization
Apr 07, 2020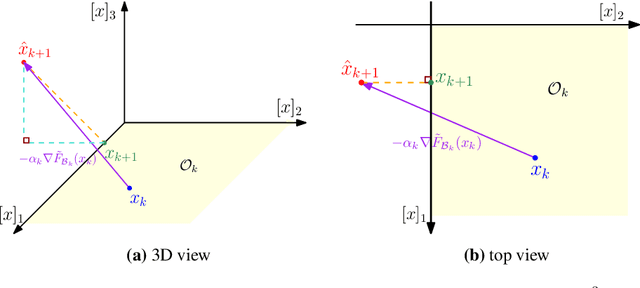
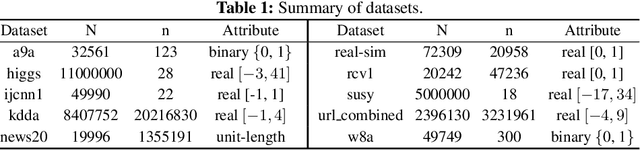

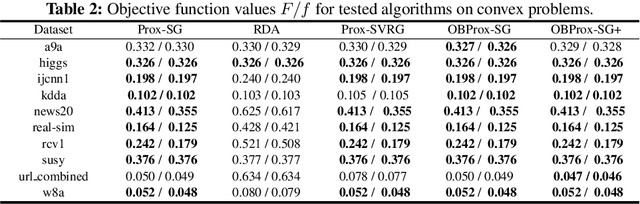
Sparsity-inducing regularization problems are ubiquitous in machine learning applications, ranging from feature selection to model compression. In this paper, we present a novel stochastic method -- Orthant Based Proximal Stochastic Gradient Method (OBProx-SG) -- to solve perhaps the most popular instance, i.e., the l1-regularized problem. The OBProx-SG method contains two steps: (i) a proximal stochastic gradient step to predict a support cover of the solution; and (ii) an orthant step to aggressively enhance the sparsity level via orthant face projection. Compared to the state-of-the-art methods, e.g., Prox-SG, RDA and Prox-SVRG, the OBProx-SG not only converges to the global optimal solutions (in convex scenario) or the stationary points (in non-convex scenario), but also promotes the sparsity of the solutions substantially. Particularly, on a large number of convex problems, OBProx-SG outperforms the existing methods comprehensively in the aspect of sparsity exploration and objective values. Moreover, the experiments on non-convex deep neural networks, e.g., MobileNetV1 and ResNet18, further demonstrate its superiority by achieving the solutions of much higher sparsity without sacrificing generalization accuracy.
Realizing Pixel-Level Semantic Learning in Complex Driving Scenes based on Only One Annotated Pixel per Class
Mar 10, 2020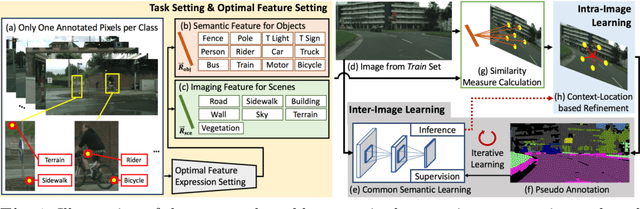


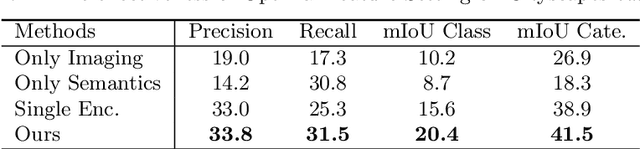
Semantic segmentation tasks based on weakly supervised condition have been put forward to achieve a lightweight labeling process. For simple images that only include a few categories, researches based on image-level annotations have achieved acceptable performance. However, when facing complex scenes, since image contains a large amount of classes, it becomes difficult to learn visual appearance based on image tags. In this case, image-level annotations are not effective in providing information. Therefore, we set up a new task in which only one annotated pixel is provided for each category. Based on the more lightweight and informative condition, a three step process is built for pseudo labels generation, which progressively implement optimal feature representation for each category, image inference and context-location based refinement. In particular, since high-level semantics and low-level imaging feature have different discriminative ability for each class under driving scenes, we divide each category into "object" or "scene" and then provide different operations for the two types separately. Further, an alternate iterative structure is established to gradually improve segmentation performance, which combines CNN-based inter-image common semantic learning and imaging prior based intra-image modification process. Experiments on Cityscapes dataset demonstrate that the proposed method provides a feasible way to solve weakly supervised semantic segmentation task under complex driving scenes.
WSOD with PSNet and Box Regression
Nov 26, 2019
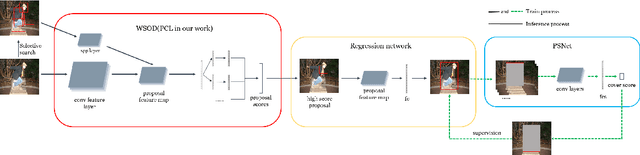
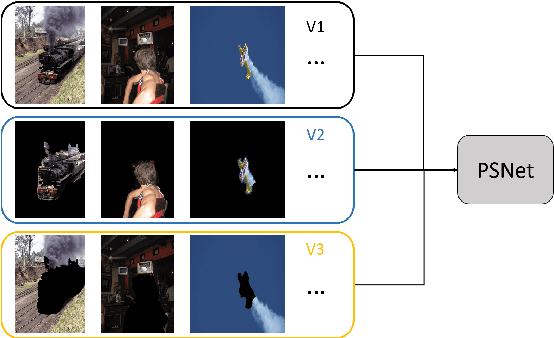

Weakly supervised object detection(WSOD) task uses only image-level annotations to train object detection task. WSOD does not require time-consuming instance-level annotations, so the study of this task has attracted more and more attention. Previous weakly supervised object detection methods iteratively update detectors and pseudo-labels, or use feature-based mask-out methods. Most of these methods do not generate complete and accurate proposals, often only the most discriminative parts of the object, or too many background areas. To solve this problem, we added the box regression module to the weakly supervised object detection network and proposed a proposal scoring network (PSNet) to supervise it. The box regression module modifies proposal to improve the IoU of proposal and ground truth. PSNet scores the proposal output from the box regression network and utilize the score to improve the box regression module. In addition, we take advantage of the PRS algorithm for generating a more accurate pseudo label to train the box regression module. Using these methods, we train the detector on the PASCAL VOC 2007 and 2012 and obtain significantly improved results.
A Invertible Dimension Reduction of Curves on a Manifold
Jul 29, 2011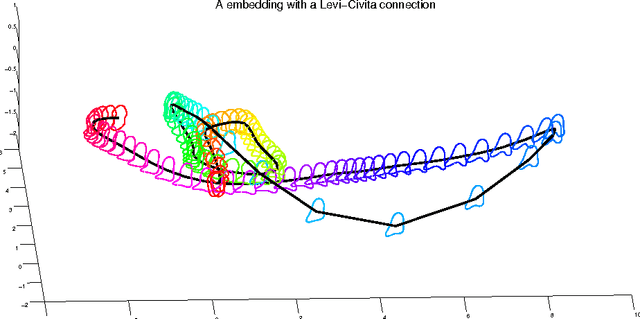
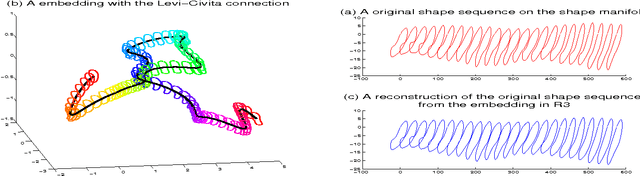
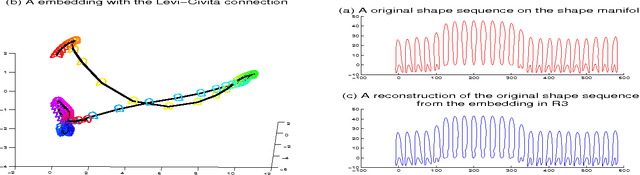
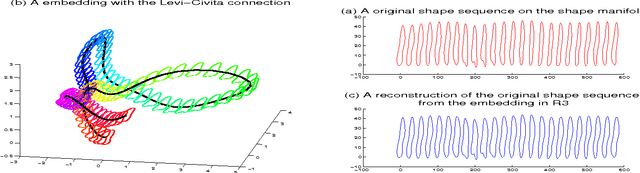
In this paper, we propose a novel lower dimensional representation of a shape sequence. The proposed dimension reduction is invertible and computationally more efficient in comparison to other related works. Theoretically, the differential geometry tools such as moving frame and parallel transportation are successfully adapted into the dimension reduction problem of high dimensional curves. Intuitively, instead of searching for a global flat subspace for curve embedding, we deployed a sequence of local flat subspaces adaptive to the geometry of both of the curve and the manifold it lies on. In practice, the experimental results of the dimension reduction and reconstruction algorithms well illustrate the advantages of the proposed theoretical innovation.