 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020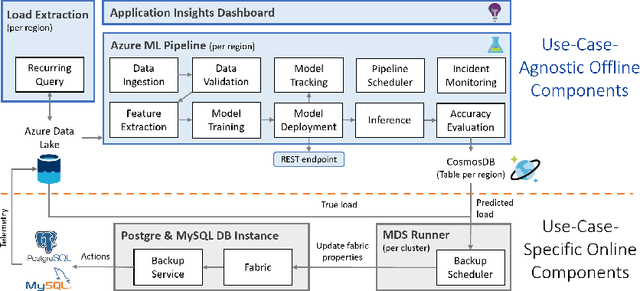
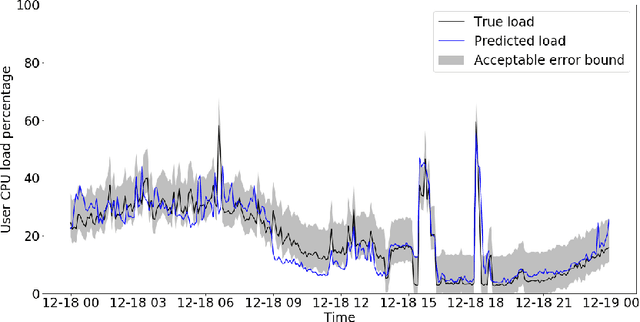
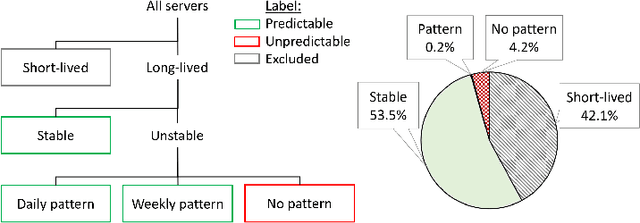
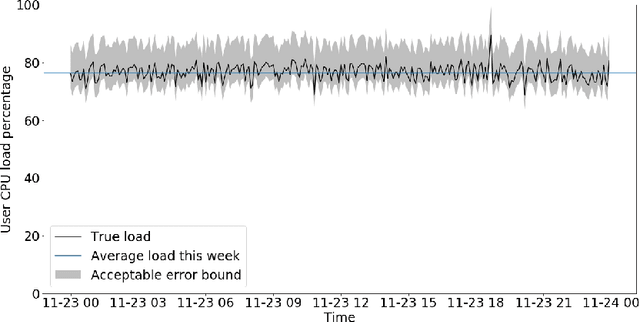
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.
MMLSpark: Unifying Machine Learning Ecosystems at Massive Scales
Oct 20, 2018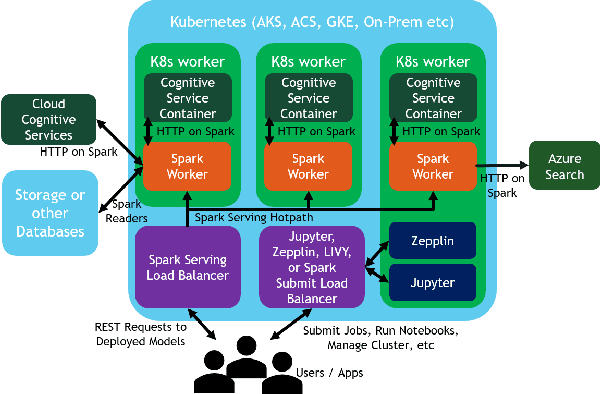

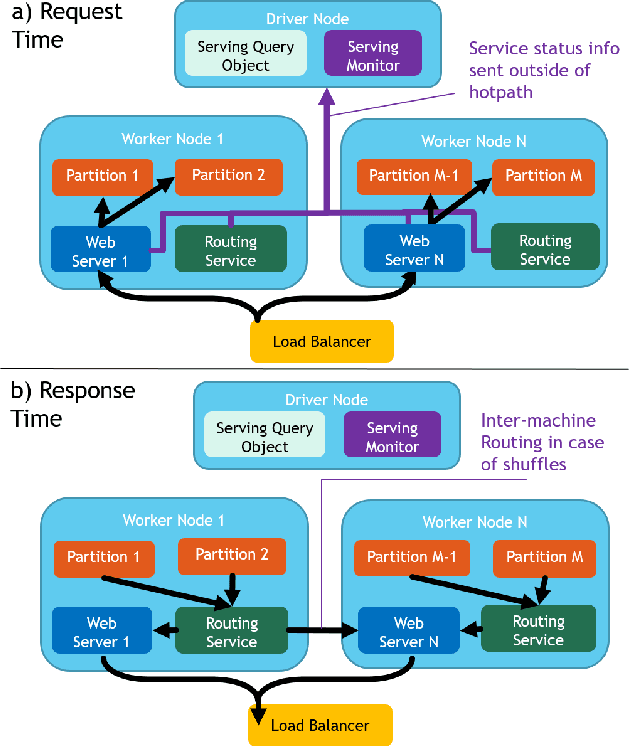
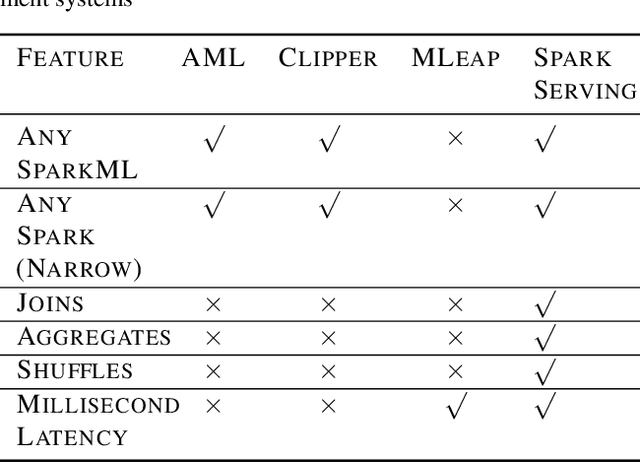
We introduce Microsoft Machine Learning for Apache Spark (MMLSpark), an ecosystem of enhancements that expand the Apache Spark distributed computing library to tackle problems in Deep Learning, Micro-Service Orchestration, Gradient Boosting, Model Interpretability, and other areas of modern computation. Furthermore, we present a novel system called Spark Serving that allows users to run any Apache Spark program as a distributed, sub-millisecond latency web service backed by their existing Spark Cluster. All MMLSpark contributions have the same API to enable simple composition across frameworks and usage across batch, streaming, and RESTful web serving scenarios on static, elastic, or serverless clusters. We showcase MMLSpark by creating a method for deep object detection capable of learning without human labeled data and demonstrate its effectiveness for Snow Leopard conservation.