 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Diagnostic CT to DTI Tractography labels: Using Deep Learning for Corticospinal Tract Injury Assessment and Outcome Prediction in Intracerebral Haemorrhage
Aug 12, 2024



The preservation of the corticospinal tract (CST) is key to good motor recovery after stroke. The gold standard method of assessing the CST with imaging is diffusion tensor tractography. However, this is not available for most intracerebral haemorrhage (ICH) patients. Non-contrast CT scans are routinely available in most ICH diagnostic pipelines, but delineating white matter from a CT scan is challenging. We utilise nnU-Net, trained on paired diagnostic CT scans and high-directional diffusion tractography maps, to segment the CST from diagnostic CT scans alone, and we show our model reproduces diffusion based tractography maps of the CST with a Dice similarity coefficient of 57%. Surgical haematoma evacuation is sometimes performed after ICH, but published clinical trials to date show that whilst surgery reduces mortality, there is no evidence of improved functional recovery. Restricting surgery to patients with an intact CST may reveal a subset of patients for whom haematoma evacuation improves functional outcome. We investigated the clinical utility of our model in the MISTIE III clinical trial dataset. We found that our model's CST integrity measure significantly predicted outcome after ICH in the acute and chronic time frames, therefore providing a prognostic marker for patients to whom advanced diffusion tensor imaging is unavailable. This will allow for future probing of subgroups who may benefit from surgery.
Deploying a Steered Query Optimizer in Production at Microsoft
Oct 24, 2022



Modern analytical workloads are highly heterogeneous and massively complex, making generic query optimizers untenable for many customers and scenarios. As a result, it is important to specialize these optimizers to instances of the workloads. In this paper, we continue a recent line of work in steering a query optimizer towards better plans for a given workload, and make major strides in pushing previous research ideas to production deployment. Along the way we solve several operational challenges including, making steering actions more manageable, keeping the costs of steering within budget, and avoiding unexpected performance regressions in production. Our resulting system, QQ-advisor, essentially externalizes the query planner to a massive offline pipeline for better exploration and specialization. We discuss various aspects of our design and show detailed results over production SCOPE workloads at Microsoft, where the system is currently enabled by default.
Phoebe: A Learning-based Checkpoint Optimizer
Oct 05, 2021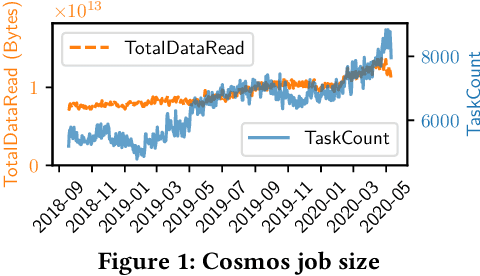
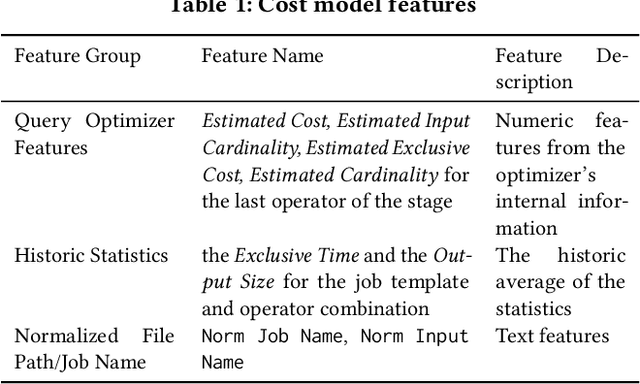

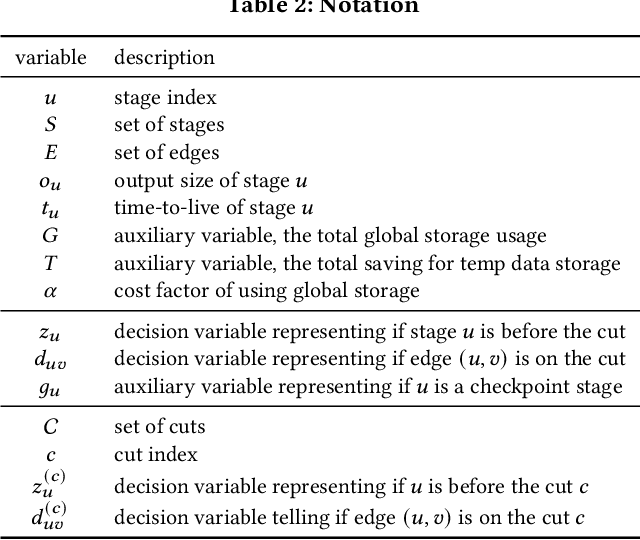
Easy-to-use programming interfaces paired with cloud-scale processing engines have enabled big data system users to author arbitrarily complex analytical jobs over massive volumes of data. However, as the complexity and scale of analytical jobs increase, they encounter a number of unforeseen problems, hotspots with large intermediate data on temporary storage, longer job recovery time after failures, and worse query optimizer estimates being examples of issues that we are facing at Microsoft. To address these issues, we propose Phoebe, an efficient learning-based checkpoint optimizer. Given a set of constraints and an objective function at compile-time, Phoebe is able to determine the decomposition of job plans, and the optimal set of checkpoints to preserve their outputs to durable global storage. Phoebe consists of three machine learning predictors and one optimization module. For each stage of a job, Phoebe makes accurate predictions for: (1) the execution time, (2) the output size, and (3) the start/end time taking into account the inter-stage dependencies. Using these predictions, we formulate checkpoint optimization as an integer programming problem and propose a scalable heuristic algorithm that meets the latency requirement of the production environment. We demonstrate the effectiveness of Phoebe in production workloads, and show that we can free the temporary storage on hotspots by more than 70% and restart failed jobs 68% faster on average with minimum performance impact. Phoebe also illustrates that adding multiple sets of checkpoints is not cost-efficient, which dramatically reduces the complexity of the optimization.
Optimal Resource Allocation for Serverless Queries
Jul 19, 2021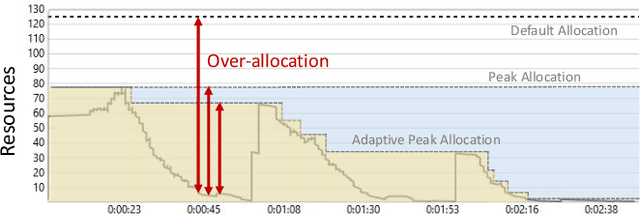
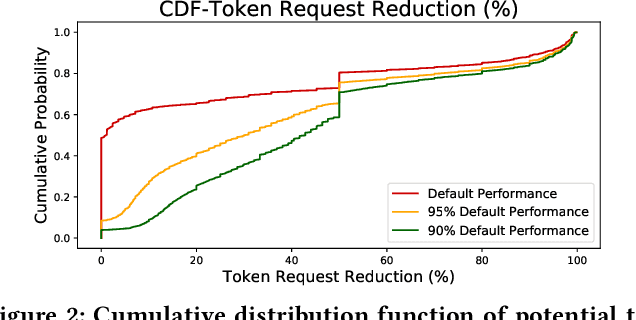

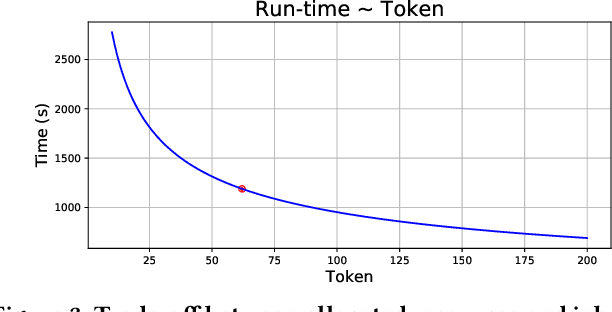
Optimizing resource allocation for analytical workloads is vital for reducing costs of cloud-data services. At the same time, it is incredibly hard for users to allocate resources per query in serverless processing systems, and they frequently misallocate by orders of magnitude. Unfortunately, prior work focused on predicting peak allocation while ignoring aggressive trade-offs between resource allocation and run-time. Additionally, these methods fail to predict allocation for queries that have not been observed in the past. In this paper, we tackle both these problems. We introduce a system for optimal resource allocation that can predict performance with aggressive trade-offs, for both new and past observed queries. We introduce the notion of a performance characteristic curve (PCC) as a parameterized representation that can compactly capture the relationship between resources and performance. To tackle training data sparsity, we introduce a novel data augmentation technique to efficiently synthesize the entire PCC using a single run of the query. Lastly, we demonstrate the advantages of a constrained loss function coupled with GNNs, over traditional ML methods, for capturing the domain specific behavior through an extensive experimental evaluation over SCOPE big data workloads at Microsoft.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019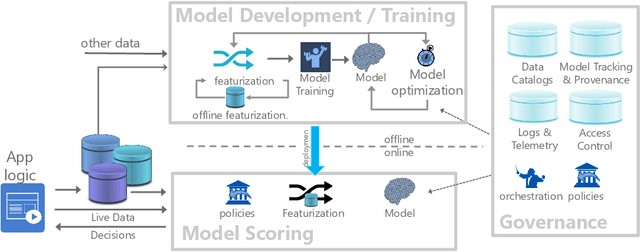
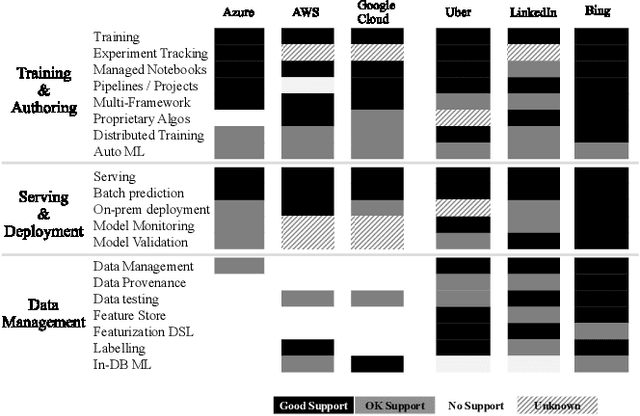
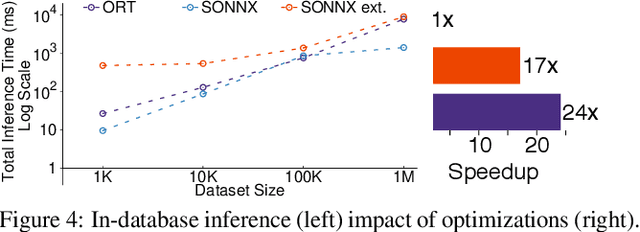
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.