 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cycle-Consistent Cooperative Networks via Alternating MCMC Teaching for Unsupervised Cross-Domain Translation
Mar 07, 2021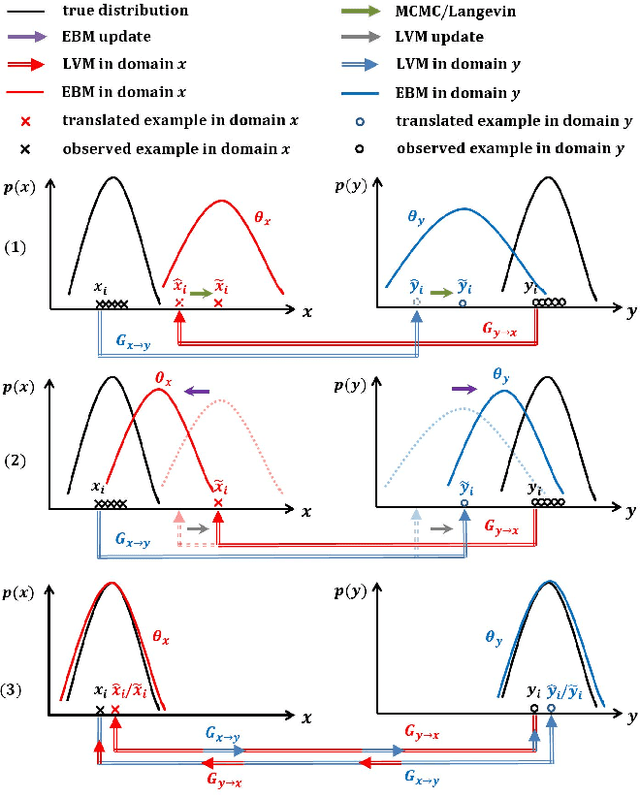
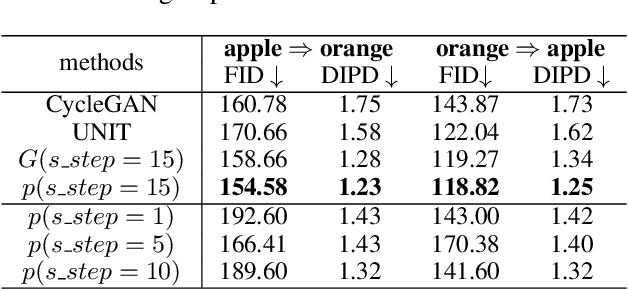

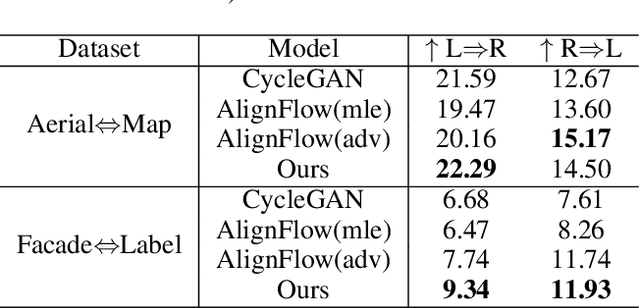
This paper studies the unsupervised cross-domain translation problem by proposing a generative framework, in which the probability distribution of each domain is represented by a generative cooperative network that consists of an energy-based model and a latent variable model. The use of generative cooperative network enables maximum likelihood learning of the domain model by MCMC teaching, where the energy-based model seeks to fit the data distribution of domain and distills its knowledge to the latent variable model via MCMC. Specifically, in the MCMC teaching process, the latent variable model parameterized by an encoder-decoder maps examples from the source domain to the target domain, while the energy-based model further refines the mapped results by Langevin revision such that the revised results match to the examples in the target domain in terms of the statistical properties, which are defined by the learned energy function. For the purpose of building up a correspondence between two unpaired domains, the proposed framework simultaneously learns a pair of cooperative networks with cycle consistency, accounting for a two-way translation between two domains, by alternating MCMC teaching. Experiments show that the proposed framework is useful for unsupervised image-to-image translation and unpaired image sequence translation.
Show Me What You Can Do: Capability Calibration on Reachable Workspace for Human-Robot Collaboration
Mar 06, 2021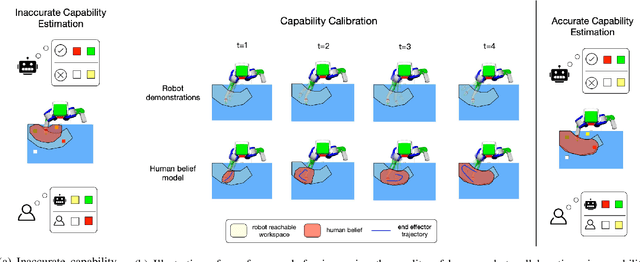
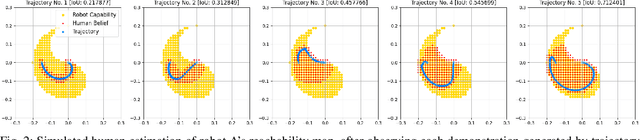
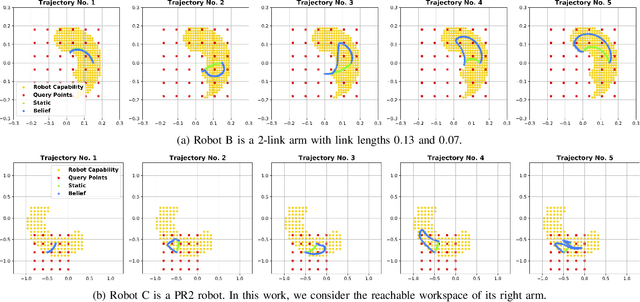

Aligning humans' assessment of what a robot can do with its true capability is crucial for establishing a common ground between human and robot partners when they collaborate on a joint task. In this work, we propose an approach to calibrate humans' estimate of a robot's reachable workspace through a small number of demonstrations before collaboration. We develop a novel motion planning method, REMP (Reachability-Expressive Motion Planning), which jointly optimizes the physical cost and the expressiveness of robot motion to reveal the robot's motion capability to a human observer. Our experiments with human participants demonstrate that a short calibration using REMP can effectively bridge the gap between what a non-expert user thinks a robot can reach and the ground-truth. We show that this calibration procedure not only results in better user perception, but also promotes more efficient human-robot collaborations in a subsequent joint task.
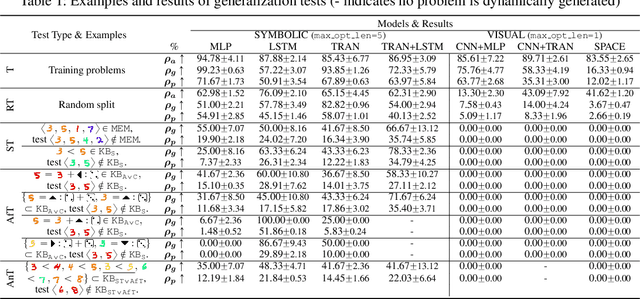
A HINT from Arithmetic: On Systematic Generalization of Perception, Syntax, and Semantics
Mar 02, 2021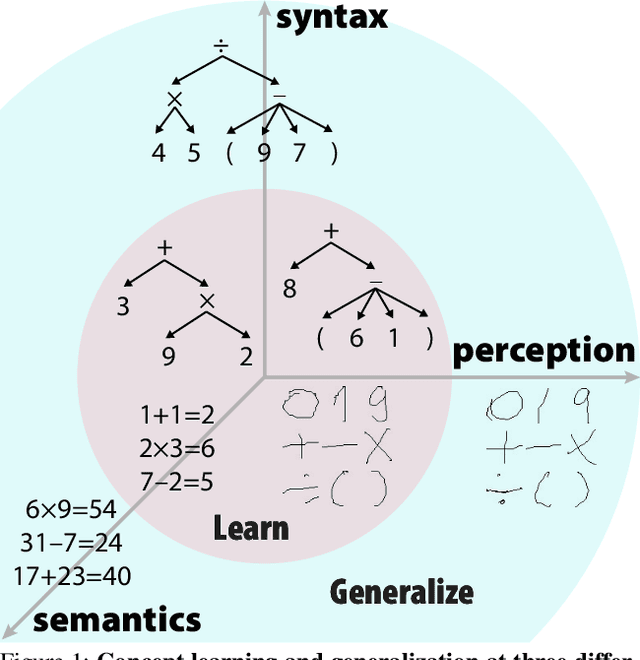
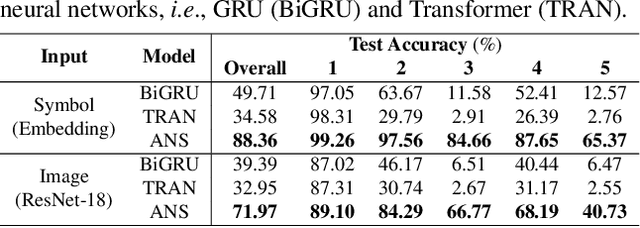
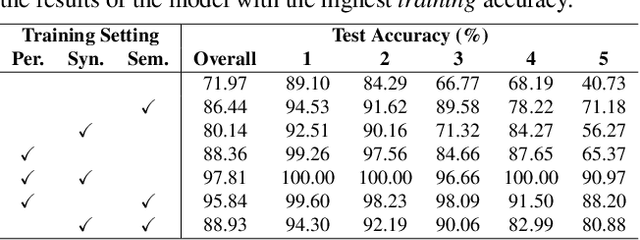
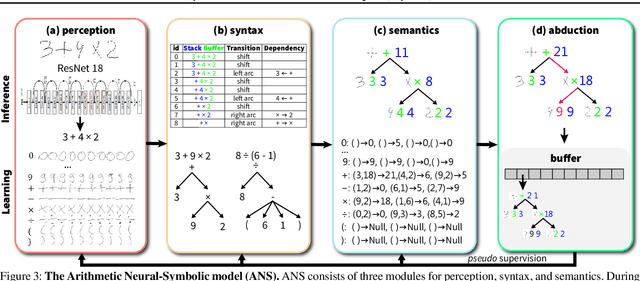
Inspired by humans' remarkable ability to master arithmetic and generalize to unseen problems, we present a new dataset, HINT, to study machines' capability of learning generalizable concepts at three different levels: perception, syntax, and semantics. In particular, concepts in HINT, including both digits and operators, are required to learn in a weakly-supervised fashion: Only the final results of handwriting expressions are provided as supervision. Learning agents need to reckon how concepts are perceived from raw signals such as images (i.e., perception), how multiple concepts are structurally combined to form a valid expression (i.e., syntax), and how concepts are realized to afford various reasoning tasks (i.e., semantics). With a focus on systematic generalization, we carefully design a five-fold test set to evaluate both the interpolation and the extrapolation of learned concepts. To tackle this challenging problem, we propose a neural-symbolic system by integrating neural networks with grammar parsing and program synthesis, learned by a novel deduction--abduction strategy. In experiments, the proposed neural-symbolic system demonstrates strong generalization capability and significantly outperforms end-to-end neural methods like RNN and Transformer. The results also indicate the significance of recursive priors for extrapolation on syntax and semantics.
HALMA: Humanlike Abstraction Learning Meets Affordance in Rapid Problem Solving
Feb 22, 2021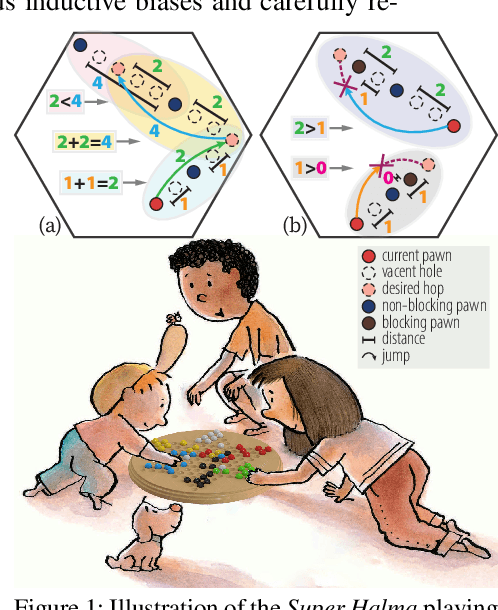
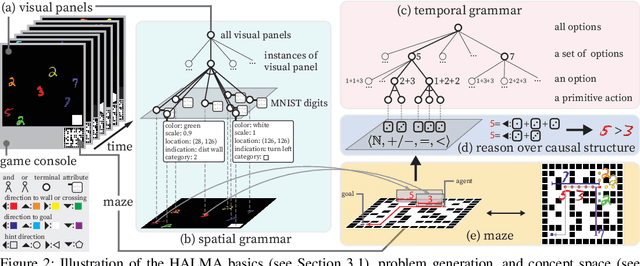
Humans learn compositional and causal abstraction, \ie, knowledge, in response to the structure of naturalistic tasks. When presented with a problem-solving task involving some objects, toddlers would first interact with these objects to reckon what they are and what can be done with them. Leveraging these concepts, they could understand the internal structure of this task, without seeing all of the problem instances. Remarkably, they further build cognitively executable strategies to \emph{rapidly} solve novel problems. To empower a learning agent with similar capability, we argue there shall be three levels of generalization in how an agent represents its knowledge: perceptual, conceptual, and algorithmic. In this paper, we devise the very first systematic benchmark that offers joint evaluation covering all three levels. This benchmark is centered around a novel task domain, HALMA, for visual concept development and rapid problem-solving. Uniquely, HALMA has a minimum yet complete concept space, upon which we introduce a novel paradigm to rigorously diagnose and dissect learning agents' capability in understanding and generalizing complex and structural concepts. We conduct extensive experiments on reinforcement learning agents with various inductive biases and carefully report their proficiency and weakness.
SMART: A Situation Model for Algebra Story Problems via Attributed Grammar
Dec 27, 2020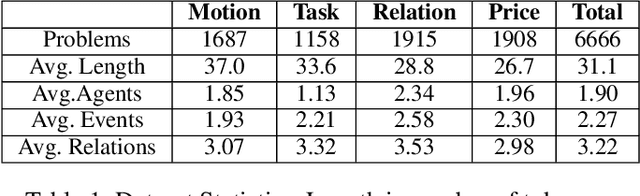
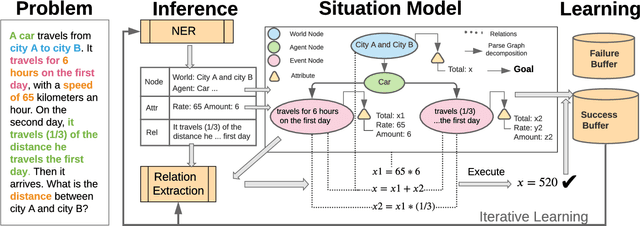

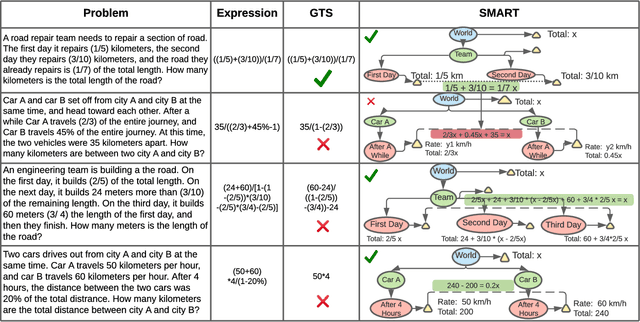
Solving algebra story problems remains a challenging task in artificial intelligence, which requires a detailed understanding of real-world situations and a strong mathematical reasoning capability. Previous neural solvers of math word problems directly translate problem texts into equations, lacking an explicit interpretation of the situations, and often fail to handle more sophisticated situations. To address such limits of neural solvers, we introduce the concept of a \emph{situation model}, which originates from psychology studies to represent the mental states of humans in problem-solving, and propose \emph{SMART}, which adopts attributed grammar as the representation of situation models for algebra story problems. Specifically, we first train an information extraction module to extract nodes, attributes, and relations from problem texts and then generate a parse graph based on a pre-defined attributed grammar. An iterative learning strategy is also proposed to improve the performance of SMART further. To rigorously study this task, we carefully curate a new dataset named \emph{ASP6.6k}. Experimental results on ASP6.6k show that the proposed model outperforms all previous neural solvers by a large margin while preserving much better interpretability. To test these models' generalization capability, we also design an out-of-distribution (OOD) evaluation, in which problems are more complex than those in the training set. Our model exceeds state-of-the-art models by 17\% in the OOD evaluation, demonstrating its superior generalization ability.
Generative VoxelNet: Learning Energy-Based Models for 3D Shape Synthesis and Analysis
Dec 25, 2020
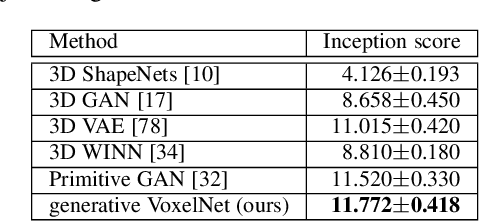

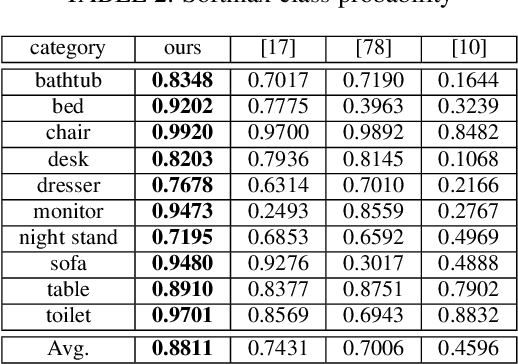
3D data that contains rich geometry information of objects and scenes is valuable for understanding 3D physical world. With the recent emergence of large-scale 3D datasets, it becomes increasingly crucial to have a powerful 3D generative model for 3D shape synthesis and analysis. This paper proposes a deep 3D energy-based model to represent volumetric shapes. The maximum likelihood training of the model follows an "analysis by synthesis" scheme. The benefits of the proposed model are six-fold: first, unlike GANs and VAEs, the model training does not rely on any auxiliary models; second, the model can synthesize realistic 3D shapes by Markov chain Monte Carlo (MCMC); third, the conditional model can be applied to 3D object recovery and super resolution; fourth, the model can serve as a building block in a multi-grid modeling and sampling framework for high resolution 3D shape synthesis; fifth, the model can be used to train a 3D generator via MCMC teaching; sixth, the unsupervisedly trained model provides a powerful feature extractor for 3D data, which is useful for 3D object classification. Experiments demonstrate that the proposed model can generate high-quality 3D shape patterns and can be useful for a wide variety of 3D shape analysis.
Learning by Fixing: Solving Math Word Problems with Weak Supervision
Dec 19, 2020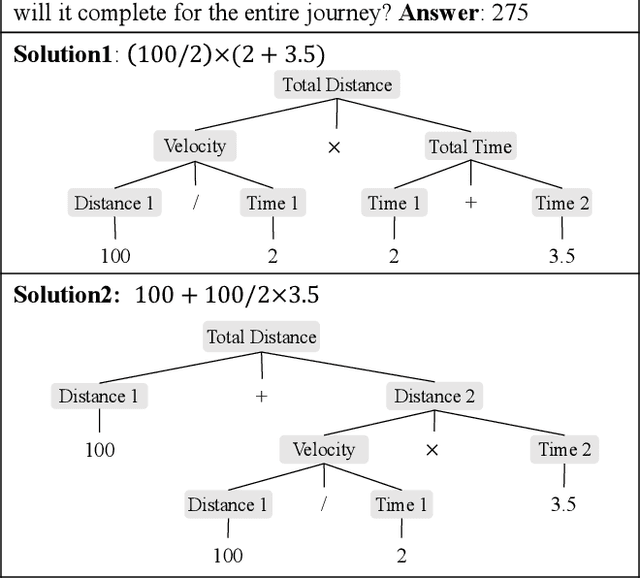
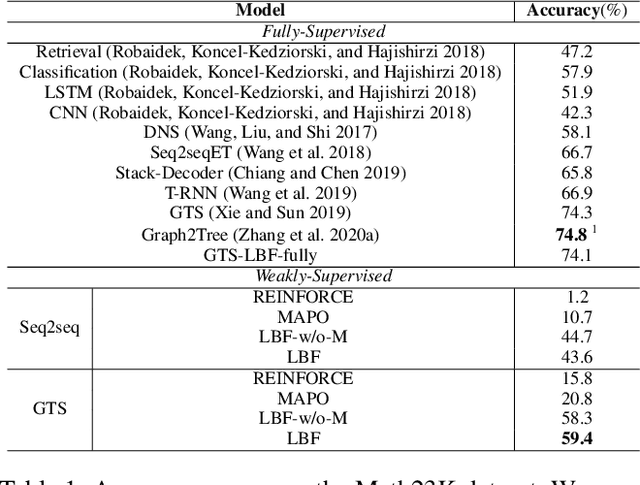
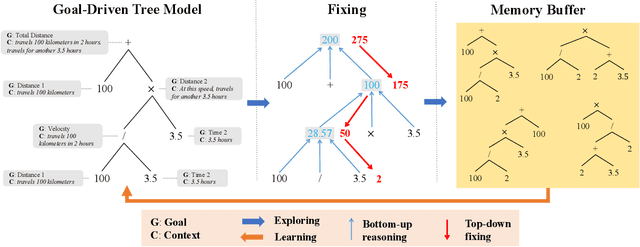
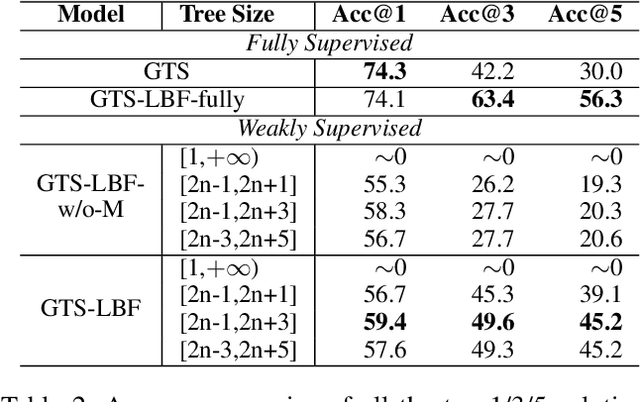
Previous neural solvers of math word problems (MWPs) are learned with full supervision and fail to generate diverse solutions. In this paper, we address this issue by introducing a \textit{weakly-supervised} paradigm for learning MWPs. Our method only requires the annotations of the final answers and can generate various solutions for a single problem. To boost weakly-supervised learning, we propose a novel \textit{learning-by-fixing} (LBF) framework, which corrects the misperceptions of the neural network via symbolic reasoning. Specifically, for an incorrect solution tree generated by the neural network, the \textit{fixing} mechanism propagates the error from the root node to the leaf nodes and infers the most probable fix that can be executed to get the desired answer. To generate more diverse solutions, \textit{tree regularization} is applied to guide the efficient shrinkage and exploration of the solution space, and a \textit{memory buffer} is designed to track and save the discovered various fixes for each problem. Experimental results on the Math23K dataset show the proposed LBF framework significantly outperforms reinforcement learning baselines in weakly-supervised learning. Furthermore, it achieves comparable top-1 and much better top-3/5 answer accuracies than fully-supervised methods, demonstrating its strength in producing diverse solutions.
Weighted Entropy Modification for Soft Actor-Critic
Nov 18, 2020
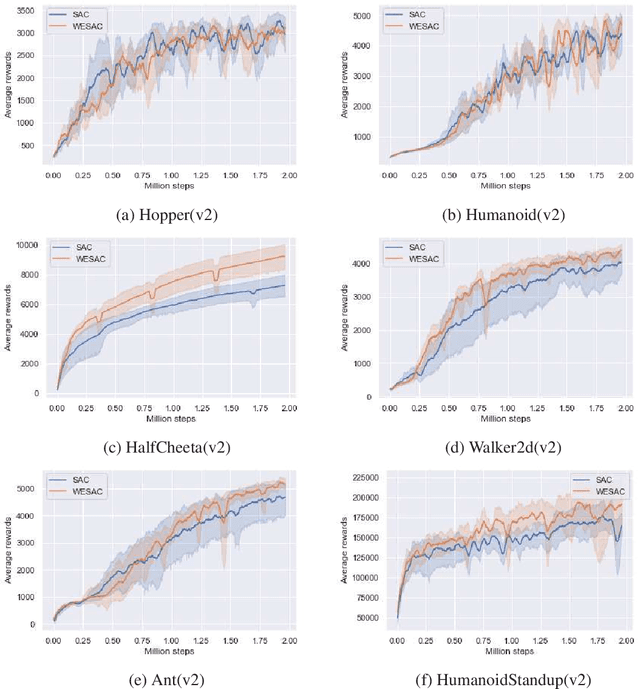
We generalize the existing principle of the maximum Shannon entropy in reinforcement learning (RL) to weighted entropy by characterizing the state-action pairs with some qualitative weights, which can be connected with prior knowledge, experience replay, and evolution process of the policy. We propose an algorithm motivated for self-balancing exploration with the introduced weight function, which leads to state-of-the-art performance on Mujoco tasks despite its simplicity in implementation.
Generalized Inverse Planning: Learning Lifted non-Markovian Utility for Generalizable Task Representation
Nov 12, 2020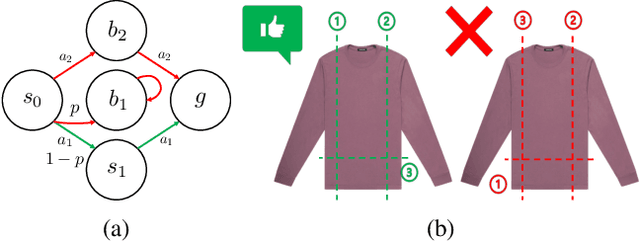
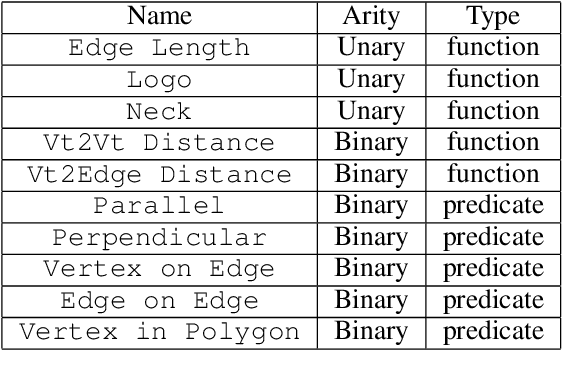
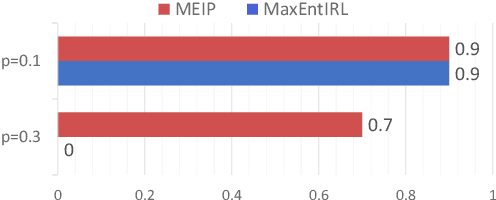
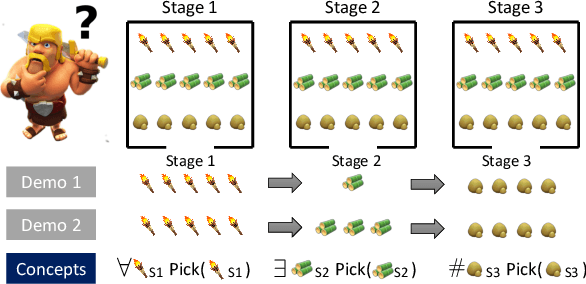
In searching for a generalizable representation of temporally extended tasks, we spot two necessary constituents: the utility needs to be non-Markovian to transfer temporal relations invariant to a probability shift, the utility also needs to be lifted to abstract out specific grounding objects. In this work, we study learning such utility from human demonstrations. While inverse reinforcement learning (IRL) has been accepted as a general framework of utility learning, its fundamental formulation is one concrete Markov Decision Process. Thus the learned reward function does not specify the task independently of the environment. Going beyond that, we define a domain of generalization that spans a set of planning problems following a schema. We hence propose a new quest, Generalized Inverse Planning, for utility learning in this domain. We further outline a computational framework, Maximum Entropy Inverse Planning (MEIP), that learns non-Markovian utility and associated concepts in a generative manner. The learned utility and concepts form a task representation that generalizes regardless of probability shift or structural change. Seeing that the proposed generalization problem has not been widely studied yet, we carefully define an evaluation protocol, with which we illustrate the effectiveness of MEIP on two proof-of-concept domains and one challenging task: learning to fold from demonstrations.
Structured Attention for Unsupervised Dialogue Structure Induction
Oct 09, 2020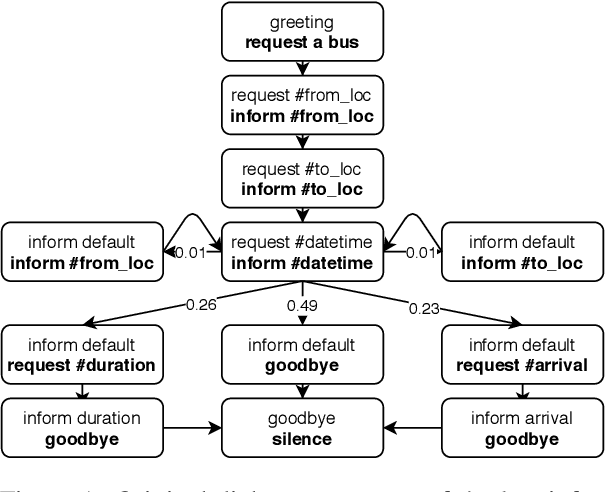

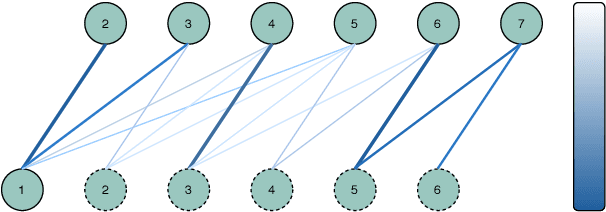
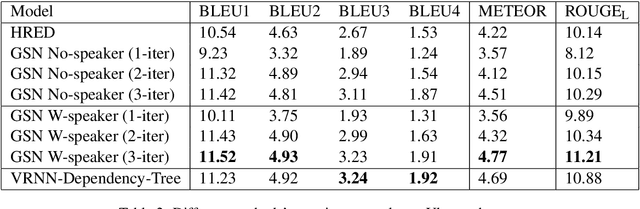
Inducing a meaningful structural representation from one or a set of dialogues is a crucial but challenging task in computational linguistics. Advancement made in this area is critical for dialogue system design and discourse analysis. It can also be extended to solve grammatical inference. In this work, we propose to incorporate structured attention layers into a Variational Recurrent Neural Network (VRNN) model with discrete latent states to learn dialogue structure in an unsupervised fashion. Compared to a vanilla VRNN, structured attention enables a model to focus on different parts of the source sentence embeddings while enforcing a structural inductive bias. Experiments show that on two-party dialogue datasets, VRNN with structured attention learns semantic structures that are similar to templates used to generate this dialogue corpus. While on multi-party dialogue datasets, our model learns an interactive structure demonstrating its capability of distinguishing speakers or addresses, automatically disentangling dialogues without explicit human annotation.