 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Machine Learning: Progress and Futures
Mar 29, 2024



Tiny Machine Learning (TinyML) is a new frontier of machine learning. By squeezing deep learning models into billions of IoT devices and microcontrollers (MCUs), we expand the scope of AI applications and enable ubiquitous intelligence. However, TinyML is challenging due to hardware constraints: the tiny memory resource makes it difficult to hold deep learning models designed for cloud and mobile platforms. There is also limited compiler and inference engine support for bare-metal devices. Therefore, we need to co-design the algorithm and system stack to enable TinyML. In this review, we will first discuss the definition, challenges, and applications of TinyML. We then survey the recent progress in TinyML and deep learning on MCUs. Next, we will introduce MCUNet, showing how we can achieve ImageNet-scale AI applications on IoT devices with system-algorithm co-design. We will further extend the solution from inference to training and introduce tiny on-device training techniques. Finally, we present future directions in this area. Today's large model might be tomorrow's tiny model. The scope of TinyML should evolve and adapt over time.
* arXiv admin note: text overlap with arXiv:2206.15472
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Mar 07, 2024



Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
BitDelta: Your Fine-Tune May Only Be Worth One Bit
Feb 28, 2024Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given the higher computational demand of pre-training, it's intuitive to assume that fine-tuning adds less new information to the model, and is thus more compressible. We explore this assumption by decomposing the weights of fine-tuned models into their pre-trained components and an additional delta. We introduce a simple method, BitDelta, which successfully quantizes this delta down to 1 bit without compromising performance. This interesting finding not only highlights the potential redundancy of information added during fine-tuning, but also has significant implications for the multi-tenant serving and multi-tenant storage of fine-tuned models. By enabling the use of a single high-precision base model accompanied by multiple 1-bit deltas, BitDelta dramatically reduces GPU memory requirements by more than 10x, which can also be translated to enhanced generation latency in multi-tenant settings. We validate BitDelta through experiments across Llama-2 and Mistral model families, and on models up to 70B parameters, showcasing minimal performance degradation over all tested settings.
EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss
Feb 07, 2024We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT's efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance. Our code and pre-trained models are released at https://github.com/mit-han-lab/efficientvit.
InfLLM: Unveiling the Intrinsic Capacity of LLMs for Understanding Extremely Long Sequences with Training-Free Memory
Feb 07, 2024



Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs, such as LLM-driven agents. However, existing LLMs, pre-trained on sequences with restricted maximum length, cannot generalize to longer sequences due to the out-of-domain and distraction issues. To alleviate these issues, existing efforts employ sliding attention windows and discard distant tokens to achieve the processing of extremely long sequences. Unfortunately, these approaches inevitably fail to capture long-distance dependencies within sequences to deeply understand semantics. This paper introduces a training-free memory-based method, InfLLM, to unveil the intrinsic ability of LLMs to process streaming long sequences. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies.
QuantumSEA: In-Time Sparse Exploration for Noise Adaptive Quantum Circuits
Jan 10, 2024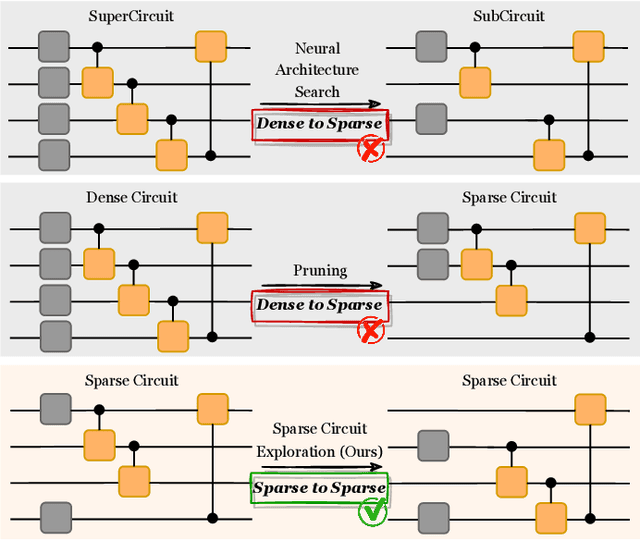
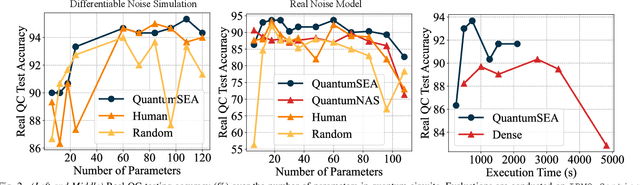
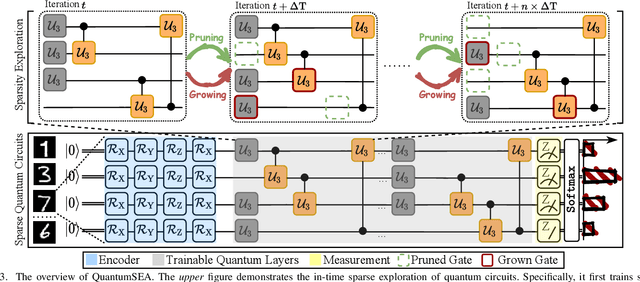
Parameterized Quantum Circuits (PQC) have obtained increasing popularity thanks to their great potential for near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Achieving quantum advantages usually requires a large number of qubits and quantum circuits with enough capacity. However, limited coherence time and massive quantum noises severely constrain the size of quantum circuits that can be executed reliably on real machines. To address these two pain points, we propose QuantumSEA, an in-time sparse exploration for noise-adaptive quantum circuits, aiming to achieve two key objectives: (1) implicit circuits capacity during training - by dynamically exploring the circuit's sparse connectivity and sticking a fixed small number of quantum gates throughout the training which satisfies the coherence time and enjoy light noises, enabling feasible executions on real quantum devices; (2) noise robustness - by jointly optimizing the topology and parameters of quantum circuits under real device noise models. In each update step of sparsity, we leverage the moving average of historical gradients to grow necessary gates and utilize salience-based pruning to eliminate insignificant gates. Extensive experiments are conducted with 7 Quantum Machine Learning (QML) and Variational Quantum Eigensolver (VQE) benchmarks on 6 simulated or real quantum computers, where QuantumSEA consistently surpasses noise-aware search, human-designed, and randomly generated quantum circuit baselines by a clear performance margin. For example, even in the most challenging on-chip training regime, our method establishes state-of-the-art results with only half the number of quantum gates and ~2x time saving of circuit executions. Codes are available at https://github.com/VITA-Group/QuantumSEA.
VILA: On Pre-training for Visual Language Models
Dec 14, 2023



Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Dec 07, 2023



Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.
RobustState: Boosting Fidelity of Quantum State Preparation via Noise-Aware Variational Training
Nov 27, 2023



Quantum state preparation, a crucial subroutine in quantum computing, involves generating a target quantum state from initialized qubits. Arbitrary state preparation algorithms can be broadly categorized into arithmetic decomposition (AD) and variational quantum state preparation (VQSP). AD employs a predefined procedure to decompose the target state into a series of gates, whereas VQSP iteratively tunes ansatz parameters to approximate target state. VQSP is particularly apt for Noisy-Intermediate Scale Quantum (NISQ) machines due to its shorter circuits. However, achieving noise-robust parameter optimization still remains challenging. We present RobustState, a novel VQSP training methodology that combines high robustness with high training efficiency. The core idea involves utilizing measurement outcomes from real machines to perform back-propagation through classical simulators, thus incorporating real quantum noise into gradient calculations. RobustState serves as a versatile, plug-and-play technique applicable for training parameters from scratch or fine-tuning existing parameters to enhance fidelity on target machines. It is adaptable to various ansatzes at both gate and pulse levels and can even benefit other variational algorithms, such as variational unitary synthesis. Comprehensive evaluation of RobustState on state preparation tasks for 4 distinct quantum algorithms using 10 real quantum machines demonstrates a coherent error reduction of up to 7.1 $\times$ and state fidelity improvement of up to 96\% and 81\% for 4-Q and 5-Q states, respectively. On average, RobustState improves fidelity by 50\% and 72\% for 4-Q and 5-Q states compared to baseline approaches.
Transformer-QEC: Quantum Error Correction Code Decoding with Transferable Transformers
Nov 27, 2023



Quantum computing has the potential to solve problems that are intractable for classical systems, yet the high error rates in contemporary quantum devices often exceed tolerable limits for useful algorithm execution. Quantum Error Correction (QEC) mitigates this by employing redundancy, distributing quantum information across multiple data qubits and utilizing syndrome qubits to monitor their states for errors. The syndromes are subsequently interpreted by a decoding algorithm to identify and correct errors in the data qubits. This task is complex due to the multiplicity of error sources affecting both data and syndrome qubits as well as syndrome extraction operations. Additionally, identical syndromes can emanate from different error sources, necessitating a decoding algorithm that evaluates syndromes collectively. Although machine learning (ML) decoders such as multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs) have been proposed, they often focus on local syndrome regions and require retraining when adjusting for different code distances. We introduce a transformer-based QEC decoder which employs self-attention to achieve a global receptive field across all input syndromes. It incorporates a mixed loss training approach, combining both local physical error and global parity label losses. Moreover, the transformer architecture's inherent adaptability to variable-length inputs allows for efficient transfer learning, enabling the decoder to adapt to varying code distances without retraining. Evaluation on six code distances and ten different error configurations demonstrates that our model consistently outperforms non-ML decoders, such as Union Find (UF) and Minimum Weight Perfect Matching (MWPM), and other ML decoders, thereby achieving best logical error rates. Moreover, the transfer learning can save over 10x of training cost.