 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Transfer Learning: Towards Memory-Efficient On-Device Learning
Paper and Code
Jul 28, 2020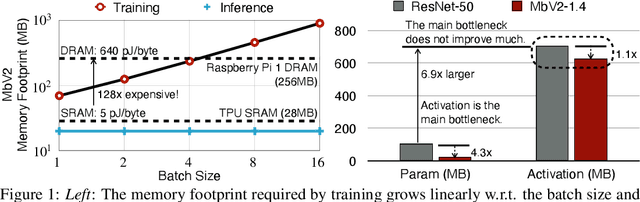
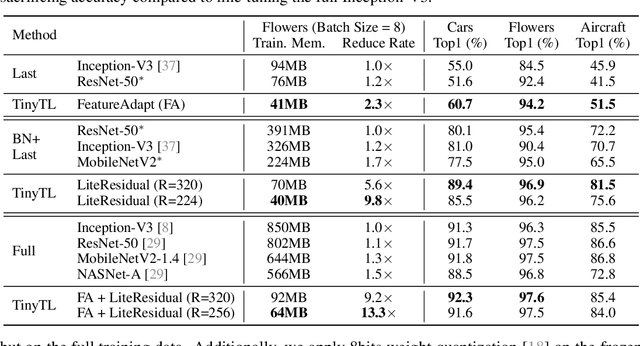
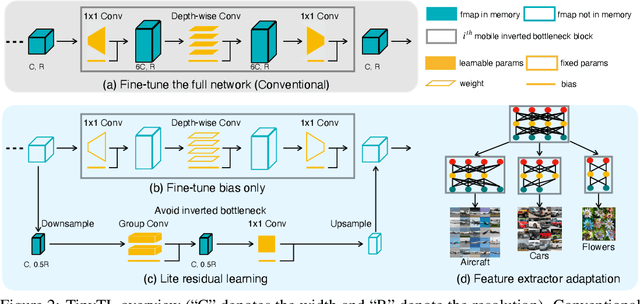
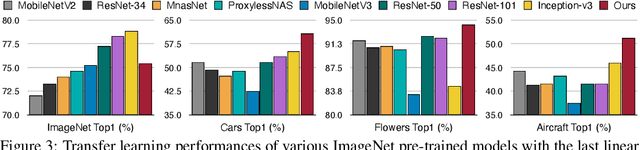
We present Tiny-Transfer-Learning (TinyTL), an efficient on-device learning method to adapt pre-trained models to newly collected data on edge devices. Different from conventional transfer learning methods that fine-tune the full network or the last layer, TinyTL freezes the weights of the feature extractor while only learning the biases, thus doesn't require storing the intermediate activations, which is the major memory bottleneck for on-device learning. To maintain the adaptation capacity without updating the weights, TinyTL introduces memory-efficient lite residual modules to refine the feature extractor by learning small residual feature maps in the middle. Besides, instead of using the same feature extractor, TinyTL adapts the architecture of the feature extractor to fit different target datasets while fixing the weights: TinyTL pre-trains a large super-net that contains many weight-shared sub-nets that can individually operate; different target dataset selects the sub-net that best match the dataset. This backpropagation-free discrete sub-net selection incurs no memory overhead. Extensive experiments show that TinyTL can reduce the training memory cost by order of magnitude (up to 13.3x) without sacrificing accuracy compared to fine-tuning the full network.