 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIOS: Inter-Operator Scheduler for CNN Acceleration
Paper and Code
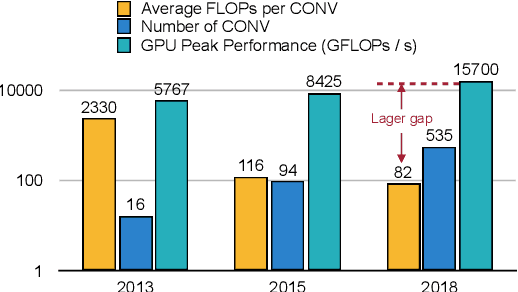
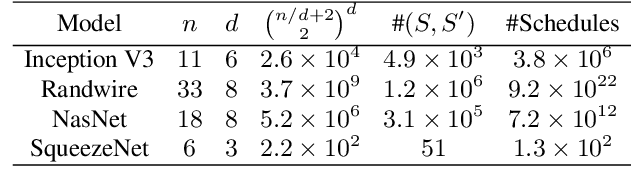
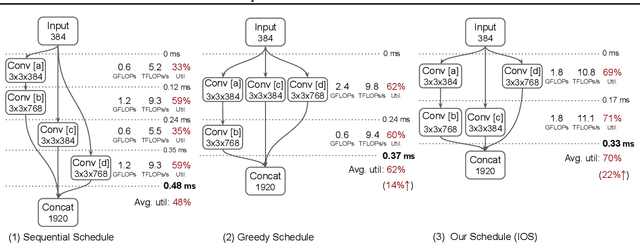
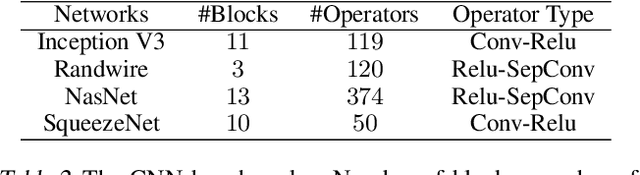
To accelerate CNN inference, existing deep learning frameworks focus on optimizing intra-operator parallelization. However, a single operator can no longer fully utilize the available parallelism given the rapid advances in high-performance hardware, resulting in a large gap between the peak performance and the real performance. This performance gap is more severe under smaller batch sizes. In this work, we extensively study the parallelism between operators and propose Inter-Operator Scheduler (IOS) to automatically schedule the execution of multiple operators in parallel. IOS utilizes dynamic programming to find a scheduling policy specialized for the target hardware. IOS consistently outperforms state-of-the-art libraries (e.g., TensorRT) by 1.1 to 1.5x on modern CNN benchmarks.