 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
Jul 12, 2021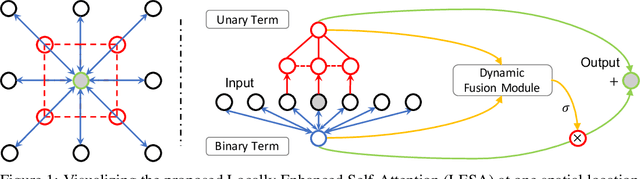

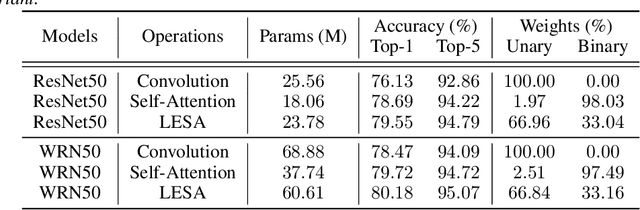

Self-Attention has become prevalent in computer vision models. Inspired by fully connected Conditional Random Fields (CRFs), we decompose it into local and context terms. They correspond to the unary and binary terms in CRF and are implemented by attention mechanisms with projection matrices. We observe that the unary terms only make small contributions to the outputs, and meanwhile standard CNNs that rely solely on the unary terms achieve great performances on a variety of tasks. Therefore, we propose Locally Enhanced Self-Attention (LESA), which enhances the unary term by incorporating it with convolutions, and utilizes a fusion module to dynamically couple the unary and binary operations. In our experiments, we replace the self-attention modules with LESA. The results on ImageNet and COCO show the superiority of LESA over convolution and self-attention baselines for the tasks of image recognition, object detection, and instance segmentation. The code is made publicly available.
DeepLab2: A TensorFlow Library for Deep Labeling
Jun 17, 2021


DeepLab2 is a TensorFlow library for deep labeling, aiming to provide a state-of-the-art and easy-to-use TensorFlow codebase for general dense pixel prediction problems in computer vision. DeepLab2 includes all our recently developed DeepLab model variants with pretrained checkpoints as well as model training and evaluation code, allowing the community to reproduce and further improve upon the state-of-art systems. To showcase the effectiveness of DeepLab2, our Panoptic-DeepLab employing Axial-SWideRNet as network backbone achieves 68.0% PQ or 83.5% mIoU on Cityscaspes validation set, with only single-scale inference and ImageNet-1K pretrained checkpoints. We hope that publicly sharing our library could facilitate future research on dense pixel labeling tasks and envision new applications of this technology. Code is made publicly available at \url{https://github.com/google-research/deeplab2}.
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
Dec 09, 2020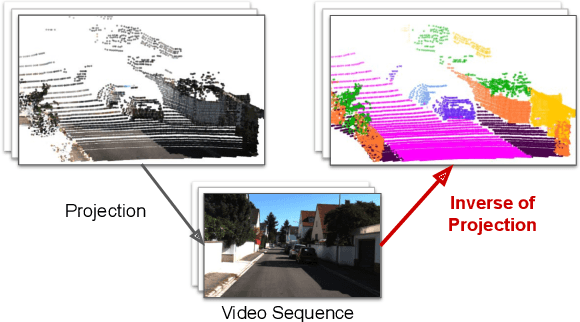
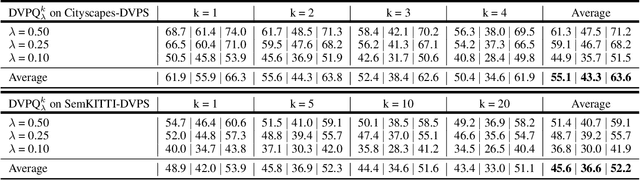
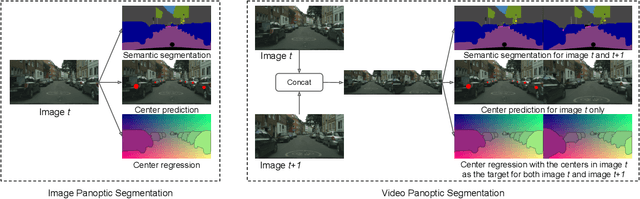
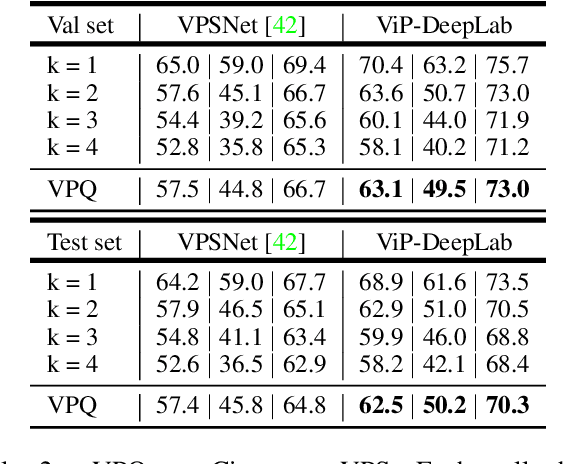
In this paper, we present ViP-DeepLab, a unified model attempting to tackle the long-standing and challenging inverse projection problem in vision, which we model as restoring the point clouds from perspective image sequences while providing each point with instance-level semantic interpretations. Solving this problem requires the vision models to predict the spatial location, semantic class, and temporally consistent instance label for each 3D point. ViP-DeepLab approaches it by jointly performing monocular depth estimation and video panoptic segmentation. We name this joint task as Depth-aware Video Panoptic Segmentation, and propose a new evaluation metric along with two derived datasets for it, which will be made available to the public. On the individual sub-tasks, ViP-DeepLab also achieves state-of-the-art results, outperforming previous methods by 5.1% VPQ on Cityscapes-VPS, ranking 1st on the KITTI monocular depth estimation benchmark, and 1st on KITTI MOTS pedestrian. The datasets and the evaluation codes are made publicly available.
Batch Normalization with Enhanced Linear Transformation
Nov 28, 2020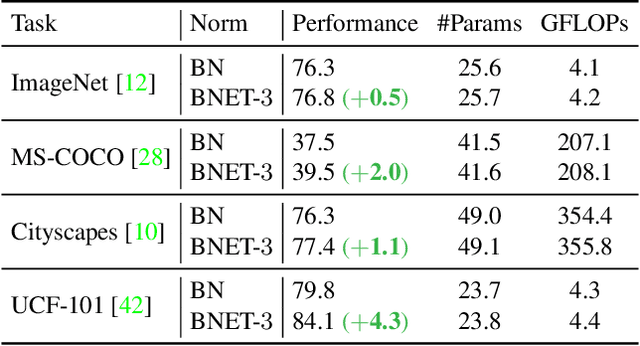
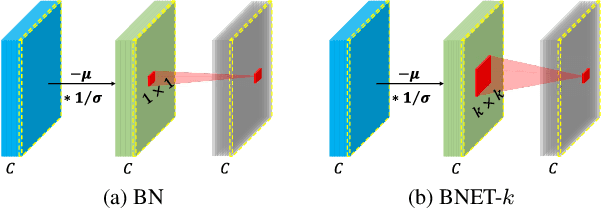
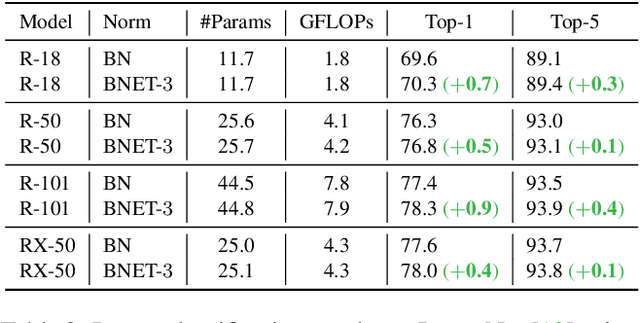
Batch normalization (BN) is a fundamental unit in modern deep networks, in which a linear transformation module was designed for improving BN's flexibility of fitting complex data distributions. In this paper, we demonstrate properly enhancing this linear transformation module can effectively improve the ability of BN. Specifically, rather than using a single neuron, we propose to additionally consider each neuron's neighborhood for calculating the outputs of the linear transformation. Our method, named BNET, can be implemented with 2-3 lines of code in most deep learning libraries. Despite the simplicity, BNET brings consistent performance gains over a wide range of backbones and visual benchmarks. Moreover, we verify that BNET accelerates the convergence of network training and enhances spatial information by assigning the important neurons with larger weights accordingly. The code is available at https://github.com/yuhuixu1993/BNET.
Scaling Wide Residual Networks for Panoptic Segmentation
Nov 23, 2020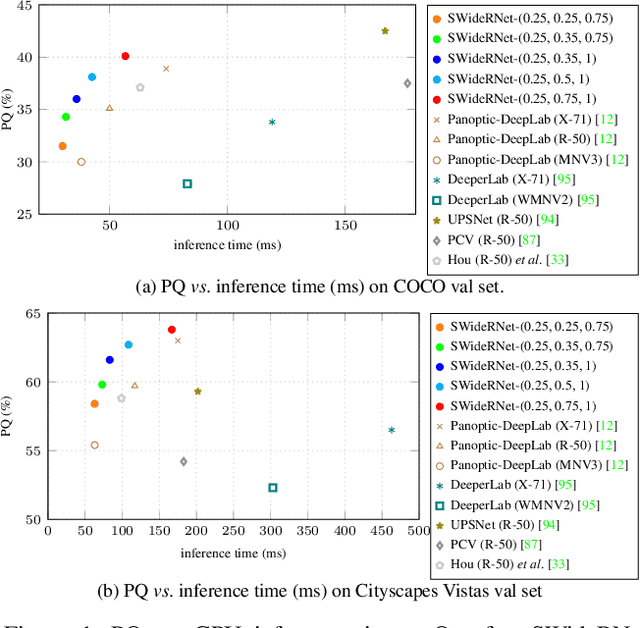
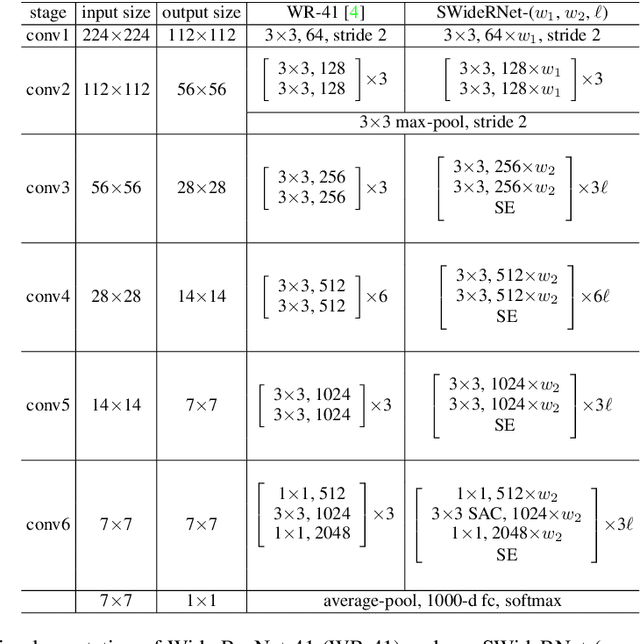
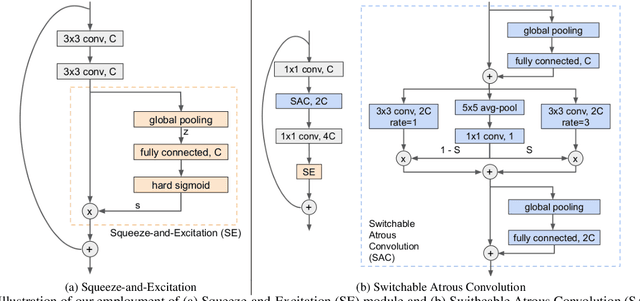
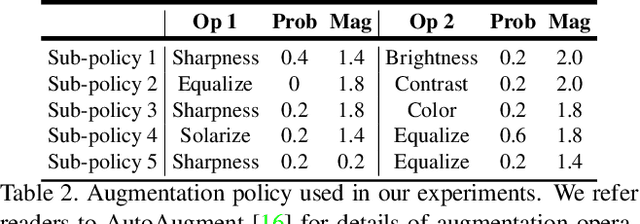
The Wide Residual Networks (Wide-ResNets), a shallow but wide model variant of the Residual Networks (ResNets) by stacking a small number of residual blocks with large channel sizes, have demonstrated outstanding performance on multiple dense prediction tasks. However, since proposed, the Wide-ResNet architecture has barely evolved over the years. In this work, we revisit its architecture design for the recent challenging panoptic segmentation task, which aims to unify semantic segmentation and instance segmentation. A baseline model is obtained by incorporating the simple and effective Squeeze-and-Excitation and Switchable Atrous Convolution to the Wide-ResNets. Its network capacity is further scaled up or down by adjusting the width (i.e., channel size) and depth (i.e., number of layers), resulting in a family of SWideRNets (short for Scaling Wide Residual Networks). We demonstrate that such a simple scaling scheme, coupled with grid search, identifies several SWideRNets that significantly advance state-of-the-art performance on panoptic segmentation datasets in both the fast model regime and strong model regime.
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
Jun 03, 2020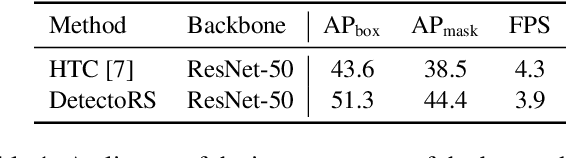
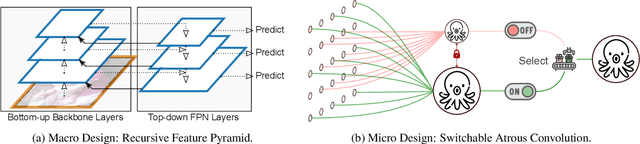
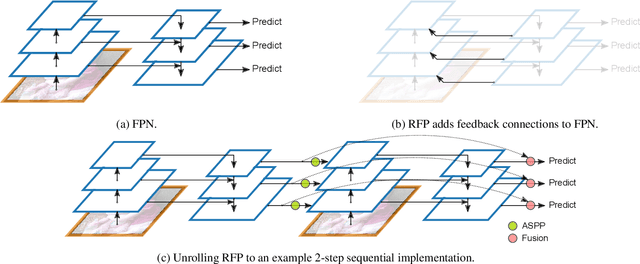

Many modern object detectors demonstrate outstanding performances by using the mechanism of looking and thinking twice. In this paper, we explore this mechanism in the backbone design for object detection. At the macro level, we propose Recursive Feature Pyramid, which incorporates extra feedback connections from Feature Pyramid Networks into the bottom-up backbone layers. At the micro level, we propose Switchable Atrous Convolution, which convolves the features with different atrous rates and gathers the results using switch functions. Combining them results in DetectoRS, which significantly improves the performances of object detection. On COCO test-dev, DetectoRS achieves state-of-the-art 54.7% box AP for object detection, 47.1% mask AP for instance segmentation, and 49.6% PQ for panoptic segmentation. The code is made publicly available.
Shape-aware Feature Extraction for Instance Segmentation
Nov 25, 2019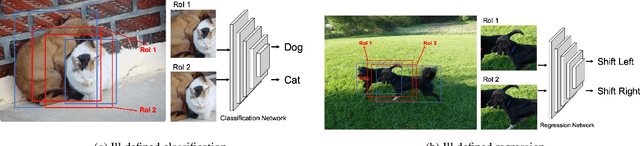
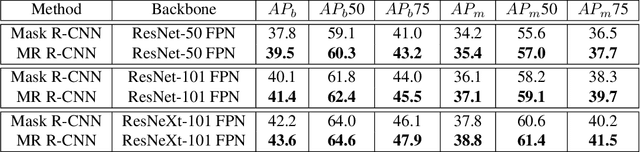

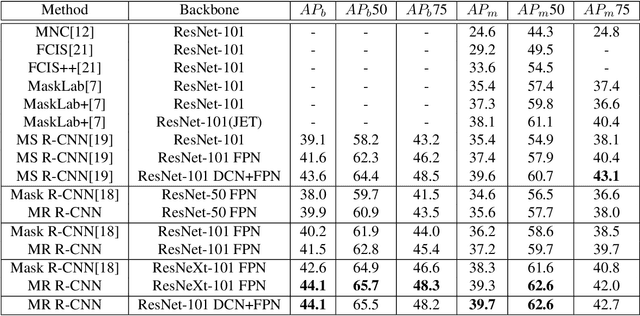
Modern instance segmentation approaches mainly adopt a sequential paradigm - ``detect then segment'', as popularized by Mask R-CNN, which have achieved considerable progress. However, they usually struggle to segment huddled instances, i.e., instances which are crowded together. The essential reason is the detection step is only learned under box-level supervision. Without the guidance from the mask-level supervision, the features extracted from the regions containing huddled instances are noisy and ambiguous, which makes the detection problem ill-posed. To address this issue, we propose a new region-of-interest (RoI) feature extraction strategy, named Shape-aware RoIAlign, which focuses feature extraction within a region aligned well with the shape of the instance-of-interest rather than a rectangular RoI. We instantiate Shape-aware RoIAlign by introducing a novel refining module built upon Mask R-CNN, which takes the mask predicted by Mask R-CNN as the region to guide the computation of Shape-aware RoIAlign. Based on the RoI features re-computed by Shape-aware RoIAlign, the refining module updates the bounding box as well as the mask predicted by Mask R-CNN. Experimental results show that the refining module equipped with Shape-aware RoIAlign achieves consistent and remarkable improvements than Mask R-CNN models with different backbones, respectively, on the challenging COCO dataset. The code will be released.
Rethinking Normalization and Elimination Singularity in Neural Networks
Nov 21, 2019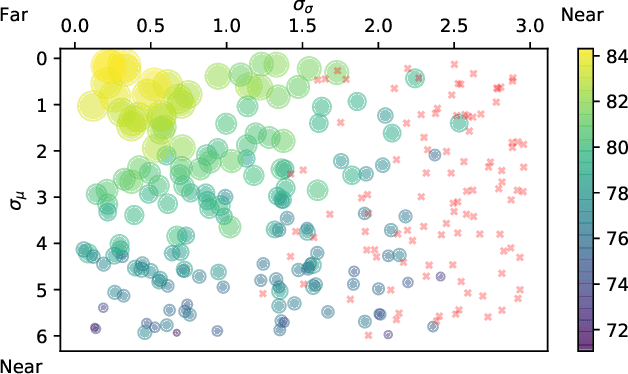
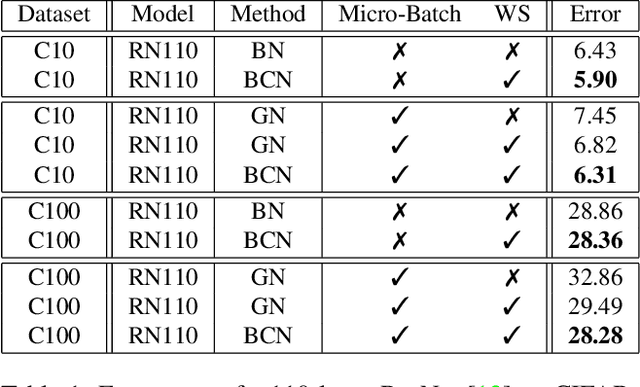
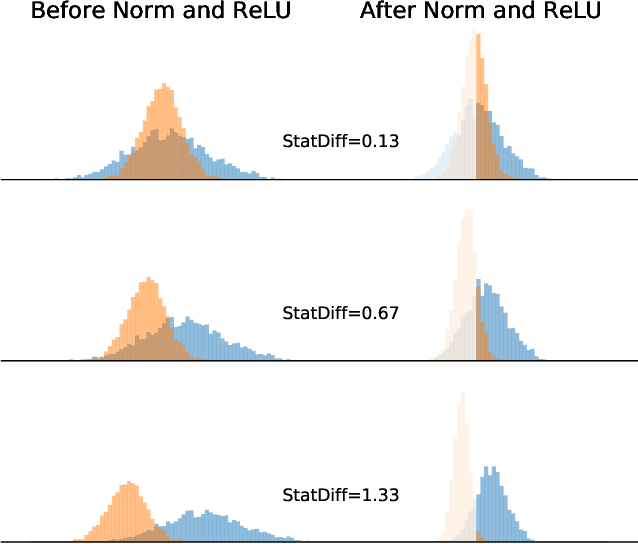
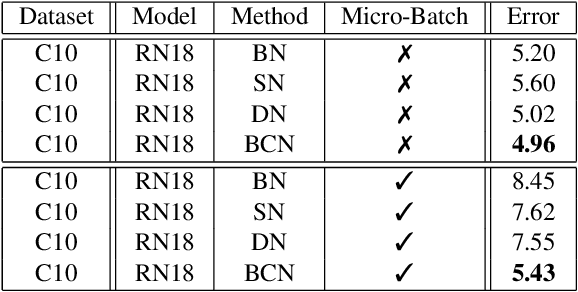
In this paper, we study normalization methods for neural networks from the perspective of elimination singularity. Elimination singularities correspond to the points on the training trajectory where neurons become consistently deactivated. They cause degenerate manifolds in the loss landscape which will slow down training and harm model performances. We show that channel-based normalizations (e.g. Layer Normalization and Group Normalization) are unable to guarantee a far distance from elimination singularities, in contrast with Batch Normalization which by design avoids models from getting too close to them. To address this issue, we propose BatchChannel Normalization (BCN), which uses batch knowledge to avoid the elimination singularities in the training of channel-normalized models. Unlike Batch Normalization, BCN is able to run in both large-batch and micro-batch training settings. The effectiveness of BCN is verified on many tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is here: https://github.com/joe-siyuan-qiao/Batch-Channel-Normalization.
TDAPNet: Prototype Network with Recurrent Top-Down Attention for Robust Object Classification under Partial Occlusion
Sep 09, 2019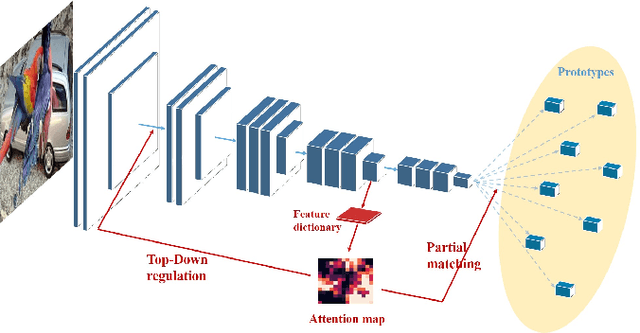
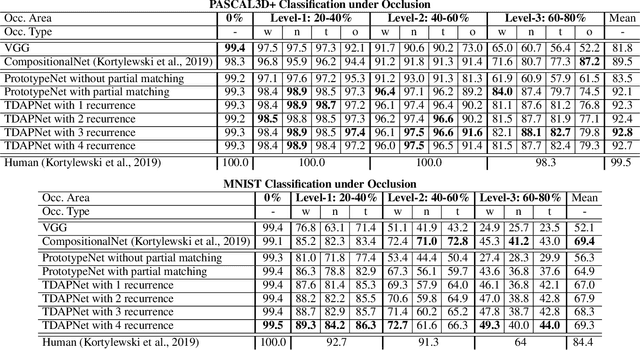

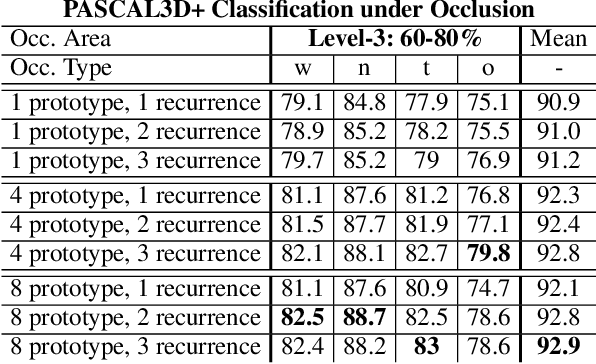
Despite deep convolutional neural networks' great success in object classification, it suffers from severe generalization performance drop under occlusion due to the inconsistency between training and testing data. Because of the large variance of occluders, our goal is a model trained on occlusion-free data while generalizable to occlusion conditions. In this work, we integrate prototypes, partial matching and top-down attention regulation into deep neural networks to realize robust object classification under occlusion. We first introduce prototype learning as its regularization encourages compact data clusters, which enables better generalization ability under inconsistent conditions. Then, attention map at intermediate layer based on feature dictionary and activation scale is estimated for partial matching, which sifts irrelevant information out when comparing features with prototypes. Further, inspired by neuroscience research that reveals the important role of feedback connection for object recognition under occlusion, a top-down feedback attention regulation is introduced into convolution layers, purposefully reducing the contamination by occlusion during feature extraction stage. Our experiment results on partially occluded MNIST and vehicles from the PASCAL3D+ dataset demonstrate that the proposed network significantly improves the robustness of current deep neural networks under occlusion. Our code will be released.
Weight Standardization
Mar 25, 2019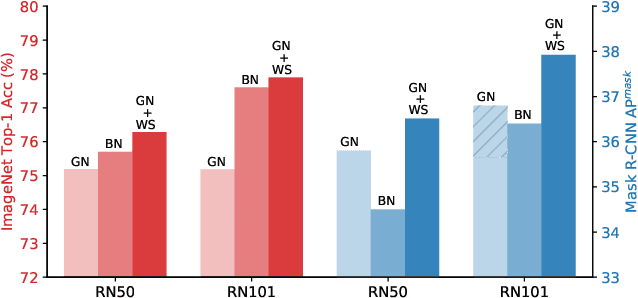

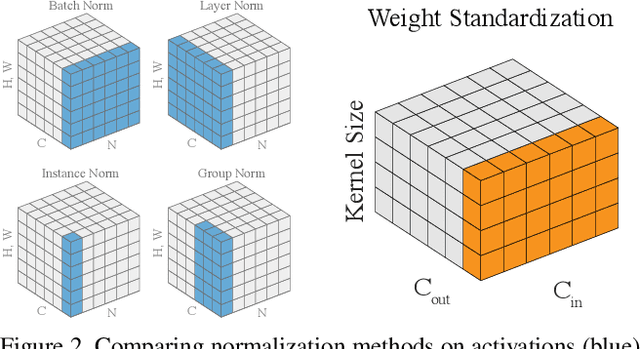
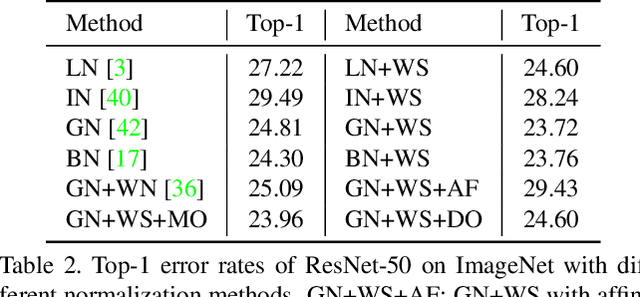
In this paper, we propose Weight Standardization (WS) to accelerate deep network training. WS is targeted at the micro-batch training setting where each GPU typically has only 1-2 images for training. The micro-batch training setting is hard because small batch sizes are not enough for training networks with Batch Normalization (BN), while other normalization methods that do not rely on batch knowledge still have difficulty matching the performances of BN in large-batch training. Our WS ends this problem because when used with Group Normalization and trained with 1 image/GPU, WS is able to match or outperform the performances of BN trained with large batch sizes with only 2 more lines of code. In micro-batch training, WS significantly outperforms other normalization methods. WS achieves these superior results by standardizing the weights in the convolutional layers, which we show is able to smooth the loss landscape by reducing the Lipschitz constants of the loss and the gradients. The effectiveness of WS is verified on many tasks, including image classification, object detection, instance segmentation, video recognition, semantic segmentation, and point cloud recognition. The code is available here: https://github.com/joe-siyuan-qiao/WeightStandardization.