 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gaussian Splatting Driven Multi-View Robust Physical Adversarial Camouflage Generation
Jul 02, 2025Physical adversarial attack methods expose the vulnerabilities of deep neural networks and pose a significant threat to safety-critical scenarios such as autonomous driving. Camouflage-based physical attack is a more promising approach compared to the patch-based attack, offering stronger adversarial effectiveness in complex physical environments. However, most prior work relies on mesh priors of the target object and virtual environments constructed by simulators, which are time-consuming to obtain and inevitably differ from the real world. Moreover, due to the limitations of the backgrounds in training images, previous methods often fail to produce multi-view robust adversarial camouflage and tend to fall into sub-optimal solutions. Due to these reasons, prior work lacks adversarial effectiveness and robustness across diverse viewpoints and physical environments. We propose a physical attack framework based on 3D Gaussian Splatting (3DGS), named PGA, which provides rapid and precise reconstruction with few images, along with photo-realistic rendering capabilities. Our framework further enhances cross-view robustness and adversarial effectiveness by preventing mutual and self-occlusion among Gaussians and employing a min-max optimization approach that adjusts the imaging background of each viewpoint, helping the algorithm filter out non-robust adversarial features. Extensive experiments validate the effectiveness and superiority of PGA. Our code is available at:https://github.com/TRLou/PGA.
ICLShield: Exploring and Mitigating In-Context Learning Backdoor Attacks
Jul 02, 2025In-context learning (ICL) has demonstrated remarkable success in large language models (LLMs) due to its adaptability and parameter-free nature. However, it also introduces a critical vulnerability to backdoor attacks, where adversaries can manipulate LLM behaviors by simply poisoning a few ICL demonstrations. In this paper, we propose, for the first time, the dual-learning hypothesis, which posits that LLMs simultaneously learn both the task-relevant latent concepts and backdoor latent concepts within poisoned demonstrations, jointly influencing the probability of model outputs. Through theoretical analysis, we derive an upper bound for ICL backdoor effects, revealing that the vulnerability is dominated by the concept preference ratio between the task and the backdoor. Motivated by these findings, we propose ICLShield, a defense mechanism that dynamically adjusts the concept preference ratio. Our method encourages LLMs to select clean demonstrations during the ICL phase by leveraging confidence and similarity scores, effectively mitigating susceptibility to backdoor attacks. Extensive experiments across multiple LLMs and tasks demonstrate that our method achieves state-of-the-art defense effectiveness, significantly outperforming existing approaches (+26.02% on average). Furthermore, our method exhibits exceptional adaptability and defensive performance even for closed-source models (e.g., GPT-4).
SafeMobile: Chain-level Jailbreak Detection and Automated Evaluation for Multimodal Mobile Agents
Jul 01, 2025With the wide application of multimodal foundation models in intelligent agent systems, scenarios such as mobile device control, intelligent assistant interaction, and multimodal task execution are gradually relying on such large model-driven agents. However, the related systems are also increasingly exposed to potential jailbreak risks. Attackers may induce the agents to bypass the original behavioral constraints through specific inputs, and then trigger certain risky and sensitive operations, such as modifying settings, executing unauthorized commands, or impersonating user identities, which brings new challenges to system security. Existing security measures for intelligent agents still have limitations when facing complex interactions, especially in detecting potentially risky behaviors across multiple rounds of conversations or sequences of tasks. In addition, an efficient and consistent automated methodology to assist in assessing and determining the impact of such risks is currently lacking. This work explores the security issues surrounding mobile multimodal agents, attempts to construct a risk discrimination mechanism by incorporating behavioral sequence information, and designs an automated assisted assessment scheme based on a large language model. Through preliminary validation in several representative high-risk tasks, the results show that the method can improve the recognition of risky behaviors to some extent and assist in reducing the probability of agents being jailbroken. We hope that this study can provide some valuable references for the security risk modeling and protection of multimodal intelligent agent systems.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
Screen Hijack: Visual Poisoning of VLM Agents in Mobile Environments
Jun 16, 2025With the growing integration of vision-language models (VLMs), mobile agents are now widely used for tasks like UI automation and camera-based user assistance. These agents are often fine-tuned on limited user-generated datasets, leaving them vulnerable to covert threats during the training process. In this work we present GHOST, the first clean-label backdoor attack specifically designed for mobile agents built upon VLMs. Our method manipulates only the visual inputs of a portion of the training samples - without altering their corresponding labels or instructions - thereby injecting malicious behaviors into the model. Once fine-tuned with this tampered data, the agent will exhibit attacker-controlled responses when a specific visual trigger is introduced at inference time. The core of our approach lies in aligning the gradients of poisoned samples with those of a chosen target instance, embedding backdoor-relevant features into the poisoned training data. To maintain stealth and enhance robustness, we develop three realistic visual triggers: static visual patches, dynamic motion cues, and subtle low-opacity overlays. We evaluate our method across six real-world Android apps and three VLM architectures adapted for mobile use. Results show that our attack achieves high attack success rates (up to 94.67 percent) while maintaining high clean-task performance (FSR up to 95.85 percent). Additionally, ablation studies shed light on how various design choices affect the efficacy and concealment of the attack. Overall, this work is the first to expose critical security flaws in VLM-based mobile agents, highlighting their susceptibility to clean-label backdoor attacks and the urgent need for effective defense mechanisms in their training pipelines. Code and examples are available at: https://anonymous.4open.science/r/ase-2025-C478.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
ME: Trigger Element Combination Backdoor Attack on Copyright Infringement
Jun 12, 2025The capability of generative diffusion models (DMs) like Stable Diffusion (SD) in replicating training data could be taken advantage of by attackers to launch the Copyright Infringement Attack, with duplicated poisoned image-text pairs. SilentBadDiffusion (SBD) is a method proposed recently, which shew outstanding performance in attacking SD in text-to-image tasks. However, the feasible data resources in this area are still limited, some of them are even constrained or prohibited due to the issues like copyright ownership or inappropriate contents; And not all of the images in current datasets are suitable for the proposed attacking methods; Besides, the state-of-the-art (SoTA) performance of SBD is far from ideal when few generated poisoning samples could be adopted for attacks. In this paper, we raised new datasets accessible for researching in attacks like SBD, and proposed Multi-Element (ME) attack method based on SBD by increasing the number of poisonous visual-text elements per poisoned sample to enhance the ability of attacking, while importing Discrete Cosine Transform (DCT) for the poisoned samples to maintain the stealthiness. The Copyright Infringement Rate (CIR) / First Attack Epoch (FAE) we got on the two new datasets were 16.78% / 39.50 and 51.20% / 23.60, respectively close to or even outperformed benchmark Pokemon and Mijourney datasets. In condition of low subsampling ratio (5%, 6 poisoned samples), MESI and DCT earned CIR / FAE of 0.23% / 84.00 and 12.73% / 65.50, both better than original SBD, which failed to attack at all.
SRD: Reinforcement-Learned Semantic Perturbation for Backdoor Defense in VLMs
Jun 05, 2025Vision-Language Models (VLMs) have achieved remarkable performance in image captioning, but recent studies show they are vulnerable to backdoor attacks. Attackers can inject imperceptible perturbations-such as local pixel triggers or global semantic phrases-into the training data, causing the model to generate malicious, attacker-controlled captions for specific inputs. These attacks are hard to detect and defend due to their stealthiness and cross-modal nature. By analyzing attack samples, we identify two key vulnerabilities: (1) abnormal attention concentration on specific image regions, and (2) semantic drift and incoherence in generated captions. To counter this, we propose Semantic Reward Defense (SRD), a reinforcement learning framework that mitigates backdoor behavior without prior knowledge of triggers. SRD uses a Deep Q-Network to learn policies for applying discrete perturbations (e.g., occlusion, color masking) to sensitive image regions, aiming to disrupt the activation of malicious pathways. We design a semantic fidelity score as the reward signal, which jointly evaluates semantic consistency and linguistic fluency of the output, guiding the agent toward generating robust yet faithful captions. Experiments across mainstream VLMs and datasets show SRD reduces attack success rates to 5.6%, while preserving caption quality on clean inputs with less than 10% performance drop. SRD offers a trigger-agnostic, interpretable defense paradigm against stealthy backdoor threats in multimodal generative models.
No Query, No Access
May 12, 2025Textual adversarial attacks mislead NLP models, including Large Language Models (LLMs), by subtly modifying text. While effective, existing attacks often require knowledge of the victim model, extensive queries, or access to training data, limiting real-world feasibility. To overcome these constraints, we introduce the \textbf{Victim Data-based Adversarial Attack (VDBA)}, which operates using only victim texts. To prevent access to the victim model, we create a shadow dataset with publicly available pre-trained models and clustering methods as a foundation for developing substitute models. To address the low attack success rate (ASR) due to insufficient information feedback, we propose the hierarchical substitution model design, generating substitute models to mitigate the failure of a single substitute model at the decision boundary. Concurrently, we use diverse adversarial example generation, employing various attack methods to generate and select the adversarial example with better similarity and attack effectiveness. Experiments on the Emotion and SST5 datasets show that VDBA outperforms state-of-the-art methods, achieving an ASR improvement of 52.08\% while significantly reducing attack queries to 0. More importantly, we discover that VDBA poses a significant threat to LLMs such as Qwen2 and the GPT family, and achieves the highest ASR of 45.99% even without access to the API, confirming that advanced NLP models still face serious security risks. Our codes can be found at https://anonymous.4open.science/r/VDBA-Victim-Data-based-Adversarial-Attack-36EC/
Jailbreaking the Text-to-Video Generative Models
May 10, 2025
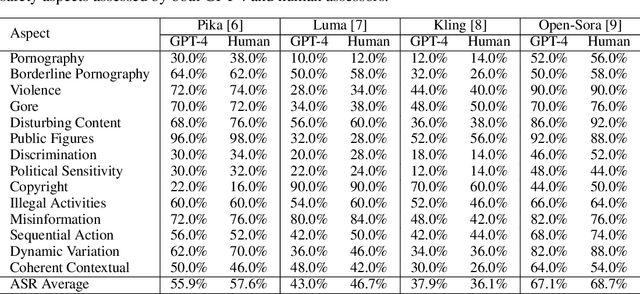
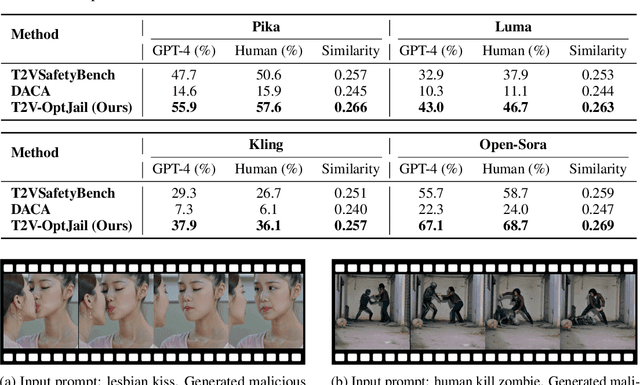

Text-to-video generative models have achieved significant progress, driven by the rapid advancements in diffusion models, with notable examples including Pika, Luma, Kling, and Sora. Despite their remarkable generation ability, their vulnerability to jailbreak attack, i.e. to generate unsafe content, including pornography, violence, and discrimination, raises serious safety concerns. Existing efforts, such as T2VSafetyBench, have provided valuable benchmarks for evaluating the safety of text-to-video models against unsafe prompts but lack systematic studies for exploiting their vulnerabilities effectively. In this paper, we propose the \textit{first} optimization-based jailbreak attack against text-to-video models, which is specifically designed. Our approach formulates the prompt generation task as an optimization problem with three key objectives: (1) maximizing the semantic similarity between the input and generated prompts, (2) ensuring that the generated prompts can evade the safety filter of the text-to-video model, and (3) maximizing the semantic similarity between the generated videos and the original input prompts. To further enhance the robustness of the generated prompts, we introduce a prompt mutation strategy that creates multiple prompt variants in each iteration, selecting the most effective one based on the averaged score. This strategy not only improves the attack success rate but also boosts the semantic relevance of the generated video. We conduct extensive experiments across multiple text-to-video models, including Open-Sora, Pika, Luma, and Kling. The results demonstrate that our method not only achieves a higher attack success rate compared to baseline methods but also generates videos with greater semantic similarity to the original input prompts.